




在计算机科学中,效率是衡量算法和数据结构性能的关键指标。我们已经了解了线性结构(如数组、链表、栈、队列)和非线性结构(如树、图),它们各自在不同场景下展现出独特的优势。数组提供快速的随机访问,链表擅长动态增删,而树和图则能有效地表示复杂的层级或关联关系。然而,当对查找、插入和删除操作有极致性能要求时,即使是性能优异的二叉搜索树,在最坏情况下的时间复杂度也只能达到 O(logN)。
那么,是否存在一种数据结构,能够将这些核心操作的时间复杂度逼近理论上的极限 O(1) 呢?答案是肯定的,这就是我们今天要深入探讨的——散列表(Hash Table),也被称作哈希表。
1. 为什么追求 O(1)?散列表的魅力
想象一下,你管理着一个藏书百万的巨大图书馆。如果想找到一本特定的书:
- 使用线性查找(遍历书架),效率会非常低下,需要花费大量时间。
- 使用二叉搜索树(按书名排序),虽然效率有所提升,但仍需沿着“岔路”逐级查找,耗时也可能不短。
然而,如果图书馆能为你提供一个神奇的“书架号”,你只需根据这个号码就能直接找到那本书,那将会是何等高效!
散列表正是这种“神奇的图书馆索引”。它通过将键(key)映射到存储位置(地址)的方式,实现了近似于 O(1) 的平均时间复杂度,从而在查找、插入和删除操作上达到了极致的效率。这种极致效率的背后,通常需要以空间上的开销和处理冲突的复杂性为代价。
2. 核心思想:哈希函数与哈希冲突
散列表的核心机制围绕着两个关键概念展开:哈希函数(Hash Function)和哈希冲突(Hash Collision)。
2.1 哈希函数:从键到地址的桥梁
哈希函数是一个至关重要的映射工具。它接收一个键(key)作为输入,经过一系列计算后,返回一个整数值,这个整数值通常被称为哈希值(Hash Value)或散列值。随后,这个哈希值会被进一步映射到散列表底层数组的某个索引(Index),这个索引即是数据实际存储的地址。
一个优秀的哈希函数应具备以下核心特点:
- 确定性:对于任何相同的输入键,哈希函数必须始终返回相同的哈希值。这是确保数据能够被正确查找和存储的基础。
- 高效计算:哈希值的计算过程必须极其迅速,否则它本身将成为性能瓶颈,抵消散列表带来的效率优势。
- 均匀分布:这是哈希函数最重要的特性之一。它应尽量将不同的键均匀地映射到散列表的不同位置,以最大程度地减少哈希冲突。均匀分布能确保散列表的每个“桶”承载的数据量尽可能平衡。
- 低冲突率:虽然完全避免冲突是不可能的,但一个好的哈希函数应努力最小化不同键产生相同哈希值的情况。
常见哈希函数构造方法:

2.2 哈希冲突:无法避免的碰撞
尽管我们竭尽全力设计优秀的哈希函数,但由于键的可能范围通常远大于散列表的实际存储容量(例如,所有可能的字符串远多于一个有限大小的数组),因此不同的键很有可能会被哈希到相同的索引位置。这种情况被称为哈希冲突(Hash Collision)。
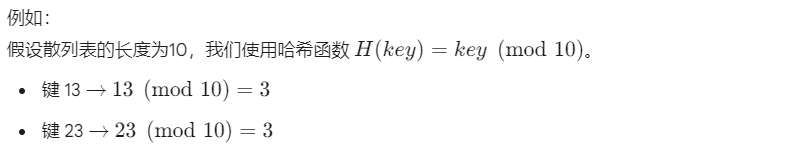
此时,键 13 和 23 发生了冲突,它们都试图存放在索引 3 的位置。如何有效地处理哈希冲突,是设计和实现散列表的关键核心。
3. 哈希冲突的解决策略:化解碰撞
解决哈希冲突的策略主要分为两大类:链地址法(Chaining)和开放寻址法(Open Addressing)。
3.1 链地址法(Chaining / Separate Chaining)
核心思想:当多个键哈希到同一个索引位置时,不将它们直接存储在该位置,而是将该索引位置视为一个**“桶”(bucket)。每个桶实际上是一个指向链表(或其
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









