









原创文章,链接:http://blog.csdn.net/u012150179/article/details/38226711
1.redis使用
(1)应用
redis在抓取系统中主要承担两方面的责任,其一是作为链接存储数据库,其二是与ceawler一起并作为crawler的调度器。后者将在“scrapr+redis( http://blog.csdn.net/u012150179/article/details/38226915)”中阐述。(2)为什么选择redis
redis的特性体现在“内存数据库”和“KV”存储方式上,前者决定其性能,后者决定其存储内容的易于组织性。reidis的使用适合链接的大量存取、快速调度的使用情景,最主要的是,由于链接需要的存储空间有限,内存的容量并不构成存储瓶颈,这时,存取速度(每秒十万次左右)便称为了redis的极大优势。
数据结构的易用性。
2.redis链接存储架构
(1)架构与部署
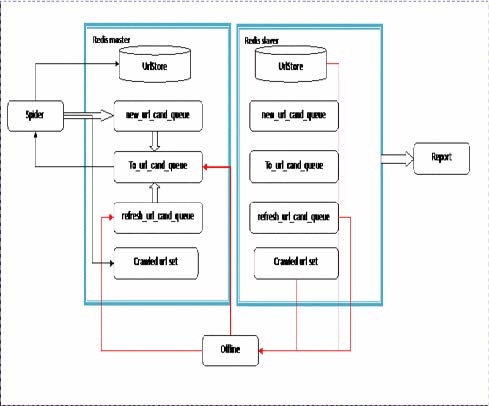 图1 redis存储架构
图1 redis存储架构

 图2 部署
图2 部署
(2)分析
i)reidis master + redis slave
master+slave一般是为了防止单点故障的出现,保护数据的安全。这是一种通过复制(replication)实现数据同步的机制,避免鸡蛋放在一个篮子的危险性。实现起来也很简单,只需设定slave的配置文件中的
slaveof <masterip> <masterport>
相应ip和port即可。除了数据安全保障,这种机制的另一特色就是读写分离,分担负载。其它可查看文章:( Redis学习手册(主从复制))。
但是注意的是默认情况下配置为slave的数据库是只读的,可通过配置文件中的slave-read-only修改。
redis数据安全另一保障是持久化机制,将内存中的数据保存到硬盘中。他提供了RDB和AOF两种方式。本质上讲AOF安全性更高,RDB备份文件更小恢复更快。更详细可见:(http://redis.readthedocs.org/en/latest/topic/persistence.html)
ii)redis数据结构应用
在文章的阐述中,可以得到几种数据结构在链接存储上的应用。如使用hash结构存储链接信息。待抓取的url队列和更新的url队列使用list。而redis几种结构的选择一般遵循如下原则:list-适合实现queue和stack的功能,在首尾部的push和pop操作更方便。
hash-存储的信息有多个字段。
set-集合。可以利用在集合中不能出现重复元素的特性将其作为filter使用。
sorted set-元素需要排序。
3.代码实现
4.参考文章
[1] 快速构建实时抓取集群[2]淘宝摘星
原创文章,链接: http://blog.csdn.net/u012150179/article/details/38226711















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









