







1. Replica Sets 复制集
只需要在某一个服务启动时加上–master参数,而另一个服务加上–slave与–source参数,
即可实现同步。MongoDB 的最新版本已不再推荐此方案。
1. 建立数据文件夹
[root@node1 bin]# ./mongod -f master.conf
[root@node1 bin]# ./mongod -f slaver.conf
[root@node1 bin]# ./mongod -f arbiter.conf
4.配置主,备,仲裁节点
可以通过客户端连接mongodb,也可以直接在三个节点中选择一个连接mongodb。
>use admin
>cfg={ _id:"testrs", members:[
同时可以查看对应节点的日志,发现正在等待别的节点生效或者正在分配数据文件。
现在基本上已经完成了集群的所有搭建工作。至于测试工作,可以留给大家自己试试。一个是往主节点插入数据,能从备节点查到之前插入的数据(查询备节点可能会遇到某个问题,可以自己去网上查查看)。二是停掉主节点,备节点能变成主节点提供服务。三是恢复主节点,备节点也能恢复其备的角色,而不是继续充当主的角色。二和三都可以通过rs.status()命令实时查看集群的变化。
![]()
./mongod --replSet rs1 --keyFile /mongodb/data/key/r1 --fork --port 28011 --dbpath /mongodb/data/r1 --logpath=/mongodb/log/r1.log --logappend
./mongod --replSet rs1 --keyFile /mongodb/data/key/r2 --fork --port 28012 --dbpath /mongodb/data/r2 --logpath=/mongodb/log/r2.log --logappend
5、配置及初始化Replica Sets
> cfg= {_id: 'rs1', members: [
{_id: 0, host: '192.168.56.87:28010', priority:1}, --成员IP及端口,priority=1 指PRIMARY
{_id: 1, host: '192.168.56.88:28011'},
{_id: 2, host: '192.168.56.89:28012'}
MongoDB 支持在多个机器中通过异步复制达到故障转移和实现冗余。多机器中同一时刻只有一台是用于写操作。正是由于这个情况,为 MongoDB 提供了数据一致性的保障。担当
Primary角色的机器能把读操作分发给 slave。
MongoDB 高可用可用分两种:
1.1 Master-Slave :主从复制
1.2 Replica Sets复制集
MongoDB 在 1.6版本对开发了新功能replica set,这比之前的replication功能要强大一些,
增加了故障自动切换和自动修复成员节点,各个DB之间数据完全一致,大大降低了维护成功。auto shard已经明确说明不支持replication paris,建议使用replica set,replica set
故障切换完全自动。
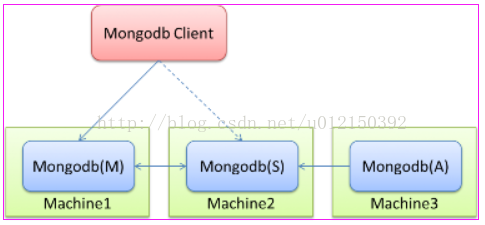
如果上图所示,Replica Sets的结构非常类似一个集群。是的,你完全可以把它当成集群,因为它确实跟集群实现的作用是一样的,其中一个节点如果出现故障,其它节点马上会将业务接过来而无须停机操作。
Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做
Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。我开始也不相信必须要有仲裁节点,但是自己也试过没仲裁节点的话,主节点挂了备节点还是备节点,所以咱们还是需要它的。
只是负责故障转移的群体投票,这样就少了数据复制的压力。
2.部署 Replica Sets
环境: redhat linux5.5
1. 建立数据文件夹
mkdir -p /mongodb/data/master --主
mkdir -p /mongodb/log/
mkdir -p /mongodb/data/slaver --备
mkdir -p /mongodb/log/
mkdir -p /mongodb/data/arbiter --仲裁
mkdir -p /mongodb/log/
touch /mongodb/log/master.log
touch /mongodb/log/slaver.log
touch /mongodb/log/arbiter.log
touch /mongodb/master.pid
touch /mongodb/slaver.pid
touch /mongodb/arbiter.pid
chmod -R 755 /mongodb --三个节点都执行
2.建立配置文件
# master.conf
dbpath=/mongodb/data/master
logpath=/mongodb/log/master.log
pidfilepath=/mongodb/master.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=192.168.56.87
port=27017
oplogSize=10000
fork=true
noprealloc=true
logpath=/mongodb/log/master.log
pidfilepath=/mongodb/master.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=192.168.56.87
port=27017
oplogSize=10000
fork=true
noprealloc=true
# slaver.conf
dbpath=/mongodb/data/slaver
logpath=/mongodb/log/slaver.log
pidfilepath=/mongodb/slaver.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=192.168.56.88
port=27017
oplogSize=10000
fork=true
noprealloc=true
logpath=/mongodb/log/slaver.log
pidfilepath=/mongodb/slaver.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=192.168.56.88
port=27017
oplogSize=10000
fork=true
noprealloc=true
#arbiter
.conf
dbpath=/mongodb/data/arbiter
logpath=/mongodb/log/arbiter.log
logpath=/mongodb/log/arbiter.log
pidfilepath=/mongodb/arbiter.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=192.168.56.89
port=27017
oplogSize=10000
fork=true
noprealloc=true
logappend=true
replSet=testrs
bind_ip=192.168.56.89
port=27017
oplogSize=10000
fork=true
noprealloc=true
给以上文件加上读写执行的权限
[root@node1 bin]# chmod 755
master.conf
[root@node1 bin]# chmod 755
slaver.conf
[root@node1 bin]# chmod 755 arbiter
.conf
注意: 把 .log 等文件也建好
参数解释:
dbpath:数据存放目录
logpath:日志存放路径
pidfilepath:进程文件,方便停止mongodb
directoryperdb:为每一个数据库按照数据库名建立文件夹存放
logappend:以追加的方式记录日志
replSet:replica set的名字
bind_ip:mongodb所绑定的ip地址
port:mongodb进程所使用的端口号,默认为27017
oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5%
fork:以后台方式运行进程
noprealloc:不预先分配存储
dbpath:数据存放目录
logpath:日志存放路径
pidfilepath:进程文件,方便停止mongodb
directoryperdb:为每一个数据库按照数据库名建立文件夹存放
logappend:以追加的方式记录日志
replSet:replica set的名字
bind_ip:mongodb所绑定的ip地址
port:mongodb进程所使用的端口号,默认为27017
oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5%
fork:以后台方式运行进程
noprealloc:不预先分配存储
3.启动mongodb
进入每个mongodb节点的bin目录下
进入每个mongodb节点的bin目录下
[root@node1 bin]# ./mongod -f master.conf
[root@node1 bin]# ./mongod -f slaver.conf
[root@node1 bin]# ./mongod -f arbiter.conf
注意配置文件的路径一定要保证正确,可以是相对路径也可以是绝对路径。
4.配置主,备,仲裁节点
可以通过客户端连接mongodb,也可以直接在三个节点中选择一个连接mongodb。
./mongo 192.168.56.87:27017 #ip和port是某个节点的地址
>use admin
>cfg={ _id:"testrs", members:[
{_id:0,host:'192.168.56.87:27017',priority:2},
{_id:1,host:'192.168.56.88:27017',priority:1},
{_id:2,host:'192.168.56.89:27017', arbiterOnly:true}] --永远不成为主节点
{_id:2,host:'192.168.56.89:27017', arbiterOnly:true}] --永远不成为主节点
};
>rs.initiate(cfg) #使配置生效
cfg是可以任意的名字,当然最好不要是mongodb的关键字,conf,config都可以。
最外层的_id表示replica set的名字,
members里包含的是所有节点的地址以及优先级。优先级最高的即成为主节点,即这里的192.168.56.87:27017。
特别注意的是,对于仲裁节点,
需要有个特别的配置——arbiterOnly:true。只能作为secondary副本节点,防止一些性能不高的节点成为主节点。
这个千万不能少了,不然主备模式就不能生效。
配置的生效时间根据不同的机器配置会有长有短,配置不错的话基本上十几秒内就能生效,有的配置需要一两分钟。
如果生效了,执行rs.status()命令会看到如下信息:
testrs:PRIMARY> rs.status()
{
"set" : "testrs",
"date" : ISODate("2015-05-08T03:27:59.706Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "192.168.56.87:27017",
"health" : 1, --1表明正常; 0表明异常
"state" : 1, -- 1表明是Primary; 2 表明是Secondary;
"stateStr" : "PRIMARY", --表明此机器是主库
"uptime" : 620,
"optime" : Timestamp(1431055581, 1),
"optimeDate" : ISODate("2015-05-08T03:26:21Z"),
"electionTime" : Timestamp(1431055584, 1),
"electionDate" : ISODate("2015-05-08T03:26:24Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "192.168.56.88:27017",
"health" : 1,
"state" : 2, -- 1表明是Primary; 2 表明是Secondary;
"stateStr" : "SECONDARY", --表明此机器是从库
"uptime" : 294,
"optime" : Timestamp(1431055581, 1),
"optimeDate" : ISODate("2015-05-08T03:26:21Z"),
"lastHeartbeat" : ISODate("2015-05-08T03:27:58.189Z"),
"lastHeartbeatRecv" : ISODate("2015-05-08T03:27:59.287Z"),
"pingMs" : 0,
"configVersion" : 1
},
{
"_id" : 2,
"name" : "192.168.56.89:27017",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 294,
"lastHeartbeat" : ISODate("2015-05-08T03:27:59.686Z"),
"lastHeartbeatRecv" : ISODate("2015-05-08T03:27:58.028Z"),
"pingMs" : 0,
"configVersion" : 1
}
],
"ok" : 1
}
{
"set" : "testrs",
"date" : ISODate("2015-05-08T03:27:59.706Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "192.168.56.87:27017",
"health" : 1, --1表明正常; 0表明异常
"state" : 1, -- 1表明是Primary; 2 表明是Secondary;
"stateStr" : "PRIMARY", --表明此机器是主库
"uptime" : 620,
"optime" : Timestamp(1431055581, 1),
"optimeDate" : ISODate("2015-05-08T03:26:21Z"),
"electionTime" : Timestamp(1431055584, 1),
"electionDate" : ISODate("2015-05-08T03:26:24Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "192.168.56.88:27017",
"health" : 1,
"state" : 2, -- 1表明是Primary; 2 表明是Secondary;
"stateStr" : "SECONDARY", --表明此机器是从库
"uptime" : 294,
"optime" : Timestamp(1431055581, 1),
"optimeDate" : ISODate("2015-05-08T03:26:21Z"),
"lastHeartbeat" : ISODate("2015-05-08T03:27:58.189Z"),
"lastHeartbeatRecv" : ISODate("2015-05-08T03:27:59.287Z"),
"pingMs" : 0,
"configVersion" : 1
},
{
"_id" : 2,
"name" : "192.168.56.89:27017",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 294,
"lastHeartbeat" : ISODate("2015-05-08T03:27:59.686Z"),
"lastHeartbeatRecv" : ISODate("2015-05-08T03:27:58.028Z"),
"pingMs" : 0,
"configVersion" : 1
}
],
"ok" : 1
}
如果配置正在生效,其中会包含如下信息:
"stateStr" : "RECOVERING"
现在基本上已经完成了集群的所有搭建工作。至于测试工作,可以留给大家自己试试。一个是往主节点插入数据,能从备节点查到之前插入的数据(查询备节点可能会遇到某个问题,可以自己去网上查查看)。二是停掉主节点,备节点能变成主节点提供服务。三是恢复主节点,备节点也能恢复其备的角色,而不是继续充当主的角色。二和三都可以通过rs.status()命令实时查看集群的变化。
5.测试集群是否同步
登录进入备库
./mongo 192.168.56.88:27017
查询person下的数据: db.person.find()
testrs:SECONDARY> db.person.find()
Error: error: { "$err" : "not master and slaveOk=false", "code" : 13435 }
Error: error: { "$err" : "not master and slaveOk=false", "code" : 13435 }
报错了:说明从库不能执行查询操作
让从库可以执行查询操作:
testrs:SECONDARY> db.getMongo().setSlaveOk()
testrs:SECONDARY> db.person.find() -- 没报错了,但是没有任何数据
登录主库:
./mongo 192.168.56.88:27017
插入一条数据: testrs:PRIMARY> db.person.insert({"name":"zw","sex":"M","age":19})
testrs:PRIMARY> db.person.find() --主库查询,ok数据出来了
{ "_id" : ObjectId("554c2f77478a8bbe95a474d9"), "name" : "zw", "sex" : "M", "age" : 19 }
{ "_id" : ObjectId("554c2f77478a8bbe95a474d9"), "name" : "zw", "sex" : "M", "age" : 19 }
testrs:SECONDARY> db.person.find() --备库查询,哈哈已经同步过来啦
{ "_id" : ObjectId("554c2f77478a8bbe95a474d9"), "name" : "zw", "sex" : "M", "age" : 19 }
{ "_id" : ObjectId("554c2f77478a8bbe95a474d9"), "name" : "zw", "sex" : "M", "age" : 19 }
到此为止,集群搭建成功.....
---------------------------------------------------------------------------------------------------------------------------------------------------------------
二、一个主节点,两个备用节点环境搭建
1、 创建数据文件存储路径
[root@node1 ~]# mkdir -p /mongodb/data/r0
[root@node1 ~]# mkdir -p /mongodb/data/r1
[root@node1 ~]# mkdir -p /mongodb/data/r1
[root@node1 ~]# mkdir -p /mongodb/data/r2
2、 创建日志文件路径
[root@node1 ~]# mkdir -p /mongodb/log
[root@node1 ~] chmod -R 755 /mongodb
3、创建主从key文件,用于标识集群的私钥的完整路径,如果各个实例的key file内容不一致,程序将不能正常用。
[root@node1 ~]# mkdir -p /mongodb/data/key
[root@node1 ~]# echo "this is rs1 super secret key" > /mongodb/data/key/r0
[root@node1 ~]# echo "this is rs1 super secret key" > /mongodb/data/key/r1
[root@node1 ~]# echo "this is rs1 super secret key" > /mongodb/data/key/r2
[root@node1 ~]# chmod 600 /mongodb/data/key/r*
4、启动3个实例
./mongod --replSet rs1 --keyFile /mongodb/data/key/r0 --fork --port 28010 --dbpath /mongodb/data/r0 --logpath=/mongodb/log/r0.log --logappend
./mongod --replSet rs1 --keyFile /mongodb/data/key/r1 --fork --port 28011 --dbpath /mongodb/data/r1 --logpath=/mongodb/log/r1.log --logappend
./mongod --replSet rs1 --keyFile /mongodb/data/key/r2 --fork --port 28012 --dbpath /mongodb/data/r2 --logpath=/mongodb/log/r2.log --logappend
5、配置及初始化Replica Sets
[root@node1 bin]# ./mongo 192.168.56.87:28010
MongoDB shell version: 3.0.2
connecting to: 192.168.56.87:28010/test
MongoDB shell version: 3.0.2
connecting to: 192.168.56.87:28010/test
> use admin
switched to db admin
switched to db admin
> cfg= {_id: 'rs1', members: [
{_id: 0, host: '192.168.56.87:28010', priority:1}, --成员IP及端口,priority=1 指PRIMARY
{_id: 1, host: '192.168.56.88:28011'},
{_id: 2, host: '192.168.56.89:28012'}
]}
初始化设置
> rs.initiate(cfg);
报错 "errmsg" : "not authorized on admin to execute command { replSetGetStatus: 1.0 }",
|
6、查看复制集状态
>rs.status()
还可以用isMaster查看Replica Sets状态。
rs1:PRIMARY> rs.isMaster()
{
"setName" : "rs1",
"ismaster" : true,
"secondary" : false,
"hosts" : [
"localhost:28010",
"localhost:28012",
"localhost:28011"
],
"maxBsonObjectSize" : 16777216,
"ok" : 1
}
rs1:PRIMARY>
{
"setName" : "rs1",
"ismaster" : true,
"secondary" : false,
"hosts" : [
"localhost:28010",
"localhost:28012",
"localhost:28011"
],
"maxBsonObjectSize" : 16777216,
"ok" : 1
}
rs1:PRIMARY>














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









