







学习笔记:
考研的时候了解过一点,当时找了各种资料,理解的也是头昏脑涨,仅仅记住了next数组的心算过程。写个笔记有助于自己加深理解。如有朋友感兴趣可去:http://blog.csdn.net/v_july_v/article/details/7041827
这篇是我现在看到解释的最透彻的一篇。
首先理解KMP算法的抽象思想
一般的字符串比较思维:
首先将文本串和模式串的第一位相互比较:
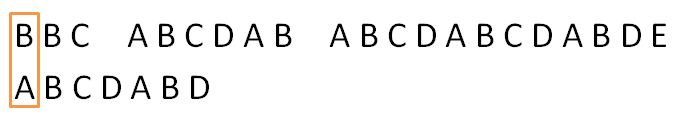
不相等,模式串向后移一位:
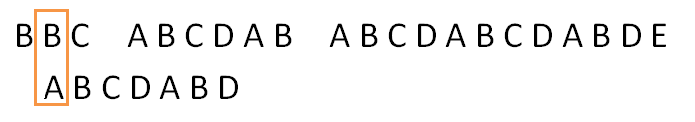
直到遇到与模式串第一位相等的位置:
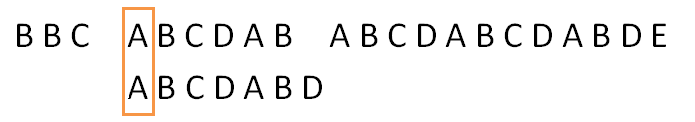
再比较模式串的第二位:
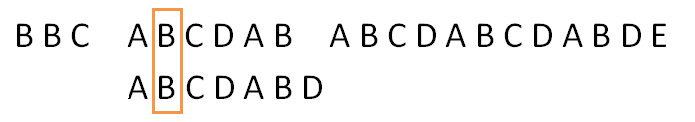
如果有不相等的时候:
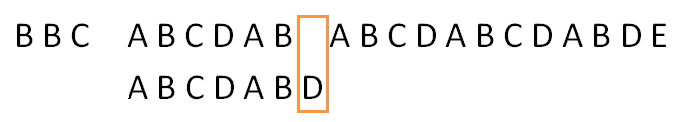
将模式串右移一位,再从头开始:
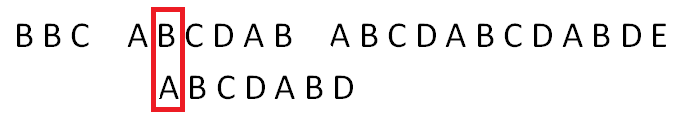
可是根据模式串的特点可以右移四位,从模式串的第2位(从0开始)与当前文本串比较
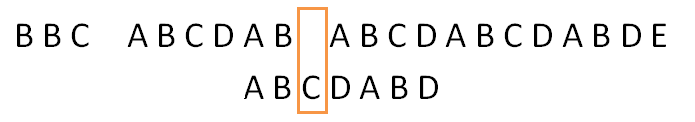
于是这个四 和2是怎么确定的呢?
先死板地接受这样一种概念:
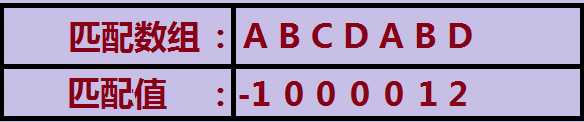
暂时叫做匹配数组:表示在一个串中,当前下标i对应的值为前i-1个串中前缀和后缀能匹配的最大长度:
eg:
什么是前缀?
比如单词word:前缀有 w、wo、wor;后缀:d、rd、ord。
匹配数组计算过程:
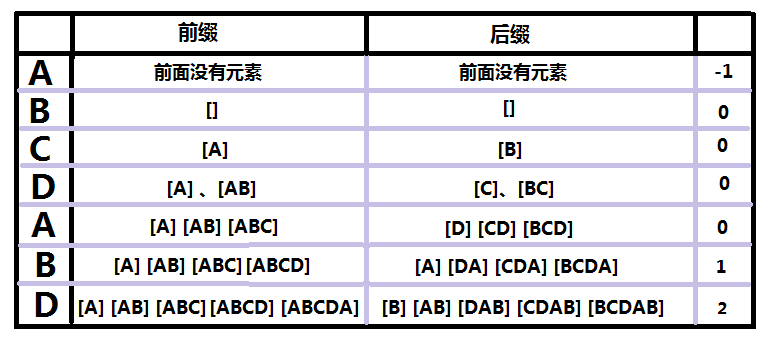
回到匹配时:
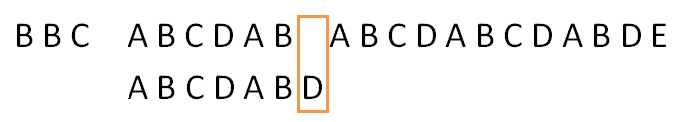
设文本串s的比较下标为i,模式串p的比较下标为j , 匹配数组为next。当前i = 10, j = 6,现在s[i] != p[j],将j = next[j] = 2,有:
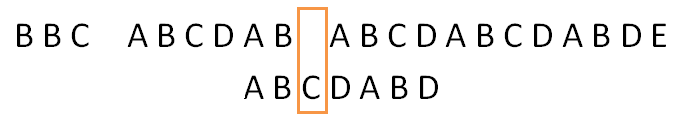
人性化的想象一下,比较到s[i]和p[j]时,前j个字符必然相等的。

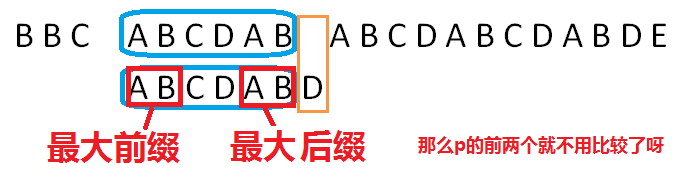
直接比较p[2]和s[10]
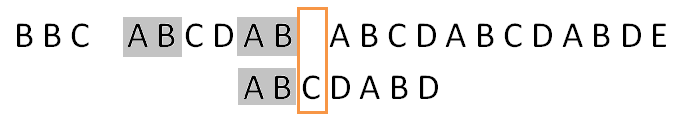
求next数组
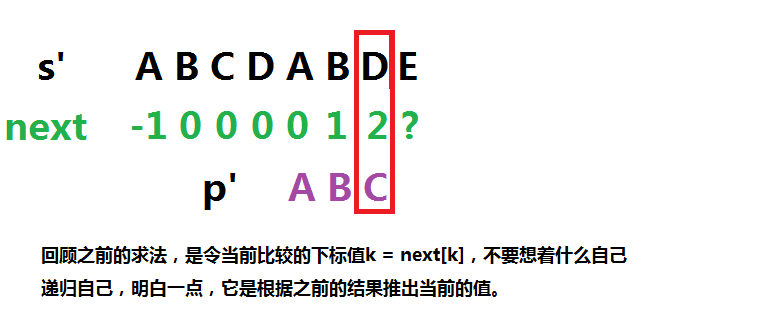
利用递归思想,假设已经求了next[0~j],且已知next [j] = k,要求next[j+1]。分为两种情况:
(1)next[k] == next[j] =>next[j+1] = next[j]+1; 表示最大前缀 最大后缀一直匹配着
(2)next[k] != next[j],一切要重新洗牌,找出前0~j个字符的最大前缀后缀。
不妨想像模式串p为文本串s’,p[0~k]为模式串p’
代码如下:
求next数组:
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//找不到就一直回溯
while(k != -1 && p[j] != p[k]) k = next[k];
next[++j] = ++k;
}
} kmp扫描:
int KmpSearch(char* s, char* p)
{
int k = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (j < sLen && k < pLen)
{
while (k != -1 && s[k] != p[j]) k = next[k];
k++;
j++;
}
if (j == pLen)
return i - j;
else
return -1;
} 














 5063
5063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









