







Kmp个人理解:
感谢这篇博文,讲的很详细!
个人认为要理解kmp首先我们得了解几个概念:
- 最长前缀后缀:
- 基于最长公共前缀后缀进行匹配
- next数组
- 通过代码来递推计算next数组
- next数组的优化
- 完整的kmp代码
最长前缀后缀:
这个很好理解,举个例子吧:
如果给定的模式串是:“ABCDABD”,从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:
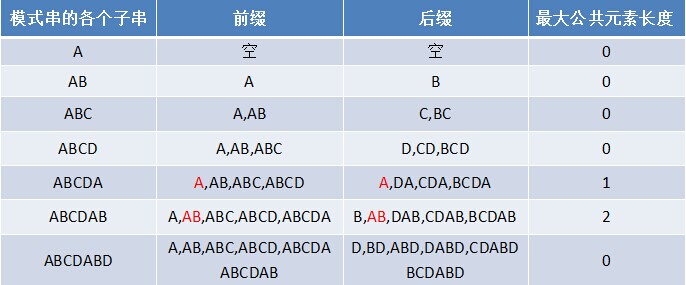
前缀不包括最后一个字符,后缀不包括第一个字符。
然后在这张图里列出了模式串的各个子串的前缀和后缀,
我们可以根据这张图来求最长前缀后缀公共长度。

基于最长公共最长前缀后缀匹配:
失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
如下图所示:当D与文本串中的不匹配时,那么下一步我们该怎么办呢?

我们应该向右移动4位,因为前面也有一个AB嘛

next数组的求法:
next数组的求法就是最大长度表全部往右移动一位,然后最左边的那个值赋值为-1就可以了。

那么,失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
通过代码来递推计算next数组:
若p0,p1,…,pk-1=pj-k,pj-k+1,…,pj-1,
①若p[k]==p[j],则next[j+1]=next[j]+1=next[k]+1
②若p[k]!=p[j],则我们需要递归前缀索引k=next[k]若找到一个字符k’,p[k’]=p[j],则最大相同的前缀后缀的长度为k’+1。
那为何递归前缀索引k = next[k],就能找到长度更短的相同前缀后缀呢?这又归根到next数组的含义。我们拿前缀 p0 pk-1 pk 去跟后缀pj-k pj-1 pj匹配,如果pk 跟pj 失配,下一步就是用p[next[k]] 去跟pj 继续匹配,如果p[ next[k] ]跟pj还是不匹配,则需要寻找长度更短的相同前缀后缀,即下一步用p[ next[ next[k] ] ]去跟pj匹配。此过程相当于模式串的自我匹配,所以不断的递归k = next[k],直到要么找到长度更短的相同前缀后缀,要么没有长度更短的相同前缀后缀。
(如下图所示)
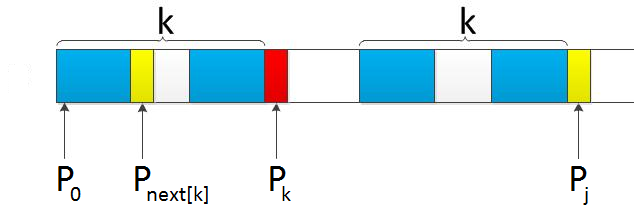
综上,可以通过递推得到next数组:
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
} next数组的优化:
比如,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。

右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?

问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
一开始我不是很明白为什么要让next[j]=next[next[j]],为什么一定就保证只要进行一次next[j]就可以了呢?后来想到是因为我们是从前面往后面来进行的,所以如果idx1与idx2这两个位置的字符相同的话,那么我们只需要找next[idx1]就好了,因为我们从前往后保证idx1是与next[idx1]是不同的两个变量。
完整的kmp代码:
以此题为例
求的是给你一个模式串和文本串,让你判断一下模式串是否是文本串的子串。
#include<cstdio>
#include<cstring>
#include<set>
#include<cmath>
#include<map>
#include<stack>
#include<string>
#include<vector>
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
#define inf 99999999
#define maxn 1000010
char s[maxn],p[maxn];
int nex[maxn];
void GetNextval(){
memset(nex,0,sizeof(nex));
int plen=strlen(p);
nex[0]=-1;
int k=-1;
int j=0;
while(j<plen-1){
if(k==-1||p[j]==p[k]){
++k;
++j;
if(p[j]!=p[k]){
nex[j]=k;
}
else{
nex[j]=nex[k];
}
}
else{
k=nex[k];
}
}
}
int Kmp(){
int i=0;
int j=0;
GetNextval();
int slen=strlen(s);
int plen=strlen(p);
while(i<slen&&j<plen){
if(j==-1||s[i]==p[j]){
++i;
++j;
}
else{
j=nex[j];
}
}
if(j==plen) return 1;
else return -1;
}
int main(){
scanf("%s",s);
int T;
scanf("%d",&T);
while(T--){
scanf("%s",p);
int ans=Kmp();
if(ans==-1) printf("no\n");
else printf("yes\n");
}
return 0;
}
/*
acmicpczjnuduzongfei
3
icpc
du
liu
*/















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









