







简介
线性回归是在统计学以及机器学习中应用最为广泛的模型之一,线性回归常用于预测连续型的随机变量。如果在线性模型中加入核算法或者feature transformation,可以模拟非线性的模型。
线性回归
线性回归模型可以表示成一下形式:
最终的需要预测y的取值,based on 输入向量X,以及系数。
通过将输入向量进行变换,可以使线性模型扩展到非线性:
里面的函数是base function,比较常用的基函数有多项式函数:
线性回归的最大似然
要用概率来表示机器学习的理论常用最大似然法,接下来咱们看看线性回归的最大似然理论:
这里表示的意义是,咱们要找到这样的一个向量theta:这个theta使得咱们手中的数据产生的概率最大。
假设数据集中的每一对Xi,yi是idd(独立同分布,independent identically distributed),那么上式可以写成:
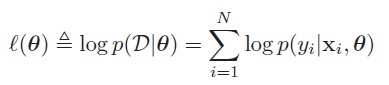
多个独立事件同时发生的概率等于他们各自概率相乘,为了方便后面的优化工作,咱们使用负的log likelihood,目的从找到使概率最大的theta值,变成了找到使negative log likelihood最小的theta值。
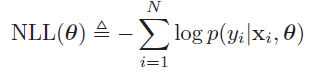
加入高斯模型假设,可以得到线性回归的loss function:

其中RSS是平方差和函数sum of squared errors, 常见的SSE/N就是均方差mean squared error:

最终咱们看到max likelihood转化为了最小二乘法,对于一维的x的预测情况如下图所示:

max likelihood的导数
用向量的乘法来表示平方差和如下所示:
它的梯度如下所示:
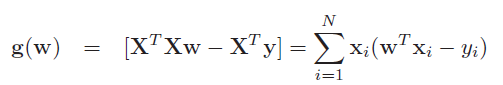
最终得到了最小二乘法的normal equation:

最小二乘的几何意义
最小二乘的更为详细的推导线性代数讲的细,其几何意义在于:将y映射至由X span的向量空间,找到residual最少的那个映射向量。

如上图,x1和x2 span了一个平面,我们做最小二乘的目的是将y映射至这个平面,红线就是residual,使residual最小的办法就是residual与X span的平面垂直。所以预测的y值就是真实的y值在X平面上的投影。
凸性
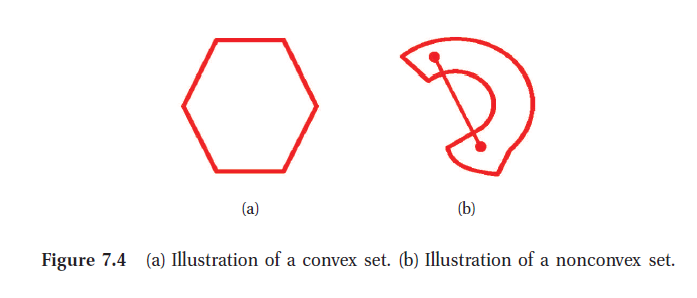
最小二乘所优化的loss function是凸函数,如果说set S是凸的,对于S中的任意两点Theta具有以下性质:
这个公式表示的意义是S中的任意两点的连线也在S这个set中。如下图,左边就是一个凸集,而右图不是。
凸函数具有以下性质:for any θ, θ‘ ∈ S, and for any 0 ≤ λ ≤ 1:
凸函数示例如左图:
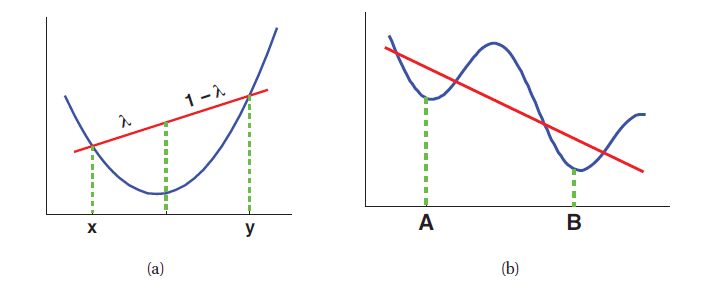
凸函数对于优化来说是很好的一件事,它表明了有global minimum存在,让优化工作充满了希望。凸函数常常呈碗状,它的二次导数必须在任意点都是整数。
Ridge regression
普通线性回归常常存在overfitting的问题,例如如果X中的两个向量相关度较高,那么最终我们得到的他们的系数可能都会很大,仅凭直觉就知道这样的模型generalization不会太好。所以引入了Ridge regression的概念,目的是将现行回归的参数本身也加入优化的loss function,目的是控制整个模型的复杂度,使得它的generalization更好。这里我们从最大后验概率(MAP)出发,去推导Ridge regression。
首先假设参数W的先验概率服从高斯分布:

最终MAP变成了MLL加上最大先验:

前半部分很熟悉了,下半部分是咱们认为的W的先验概率。最终推导出:
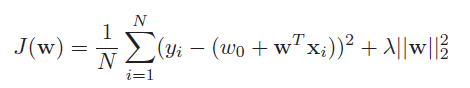
可以发现loss function比之前多了后半部分,相当于把参数W本身也加入了优化队列,最后的效果是保证得到的模型既可以很好的解释训练数据,也能在测试数据上会有良好的表现。
当然Ridge regression也有normal equation:

这里多了一个参数:λ,它用来控制惩罚W的大小,学术名词weight decay,也叫parameter shrinkage,惩罚越多,模型的variance越小。这也叫做regularization。
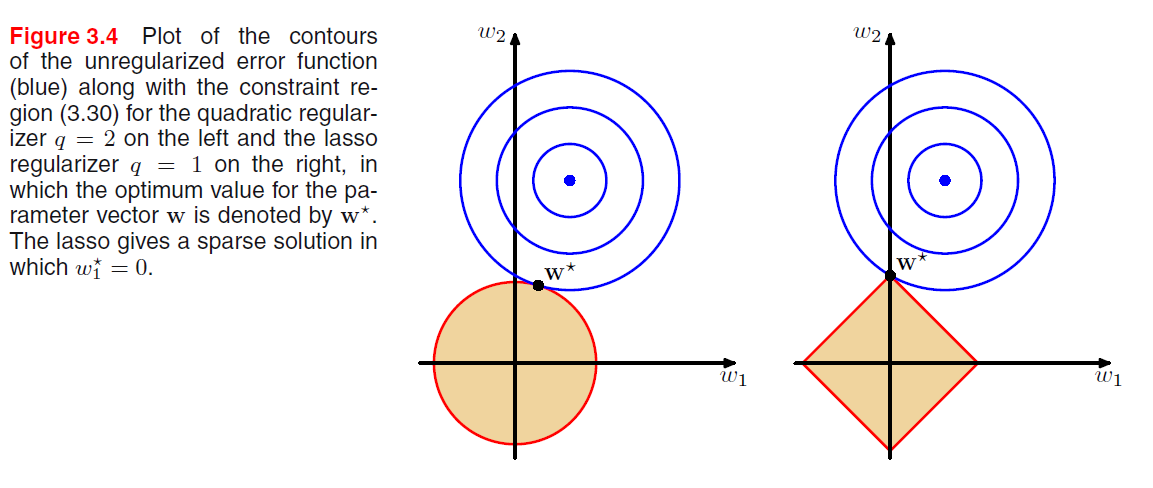
以上介绍的是惩罚项为二次项的情况,更为一般的情况如下:
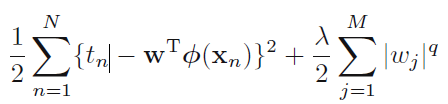
当q=1时,称为lasso regression,它的性质是:当Lamda足够大的时候,系数W中的某些项可以为0,它常用语某些稀疏的模型。正则化的另外一个理解是:把原先的优化问题转化成了一个有限制条件的优化问题,限制条件是:
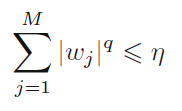
我们可以看看不同的系数q所表示的限制条件在图形化上的解释:

下图很好的解释了lasso的稀疏性,参照于Ridge。
大数据的正则化
正则化在工业中是非常常用的,特别是数据量比较小的时候,但是另外一种方法也十分常用:加入更多的数据量:直觉表示加入的数据量越多,咱们能够学习的越好。
测试数据集上的错误常分为两类:数据集本身不可避免的错误:noise floor,另外一种是与选择的模型相关的:structural error。研究表明只要数据量足够多,简单的模型也能够发挥很好的作用,但是我们必须掌握一些复杂的模型,因为有用的数据始终是珍贵的。不过现在是大数据时代, 大数据基础上的简单算法比小数据基础上的复杂算法或许更加有效。
Bias and variance Decomposition
上一节提到了算法的两种错误,第一种是不可避免的错误,第二种是由于模型本身引入的结构性错误,下面咱们推导一下这两种错误:

第一部分是结构性错误,h是真实的模型,y是我们构造的模型,这部分表示的是构造的模型与真实模型之间的差异。第二部分是真实模型预测的值与实际值之间的偏差,这是不可避免的,是数据本身带来的错误。所以机器学习算法的目的是要减小第一部分的差值。
然后第一部分结构性错误还可以再分:可以分为bias和variance。
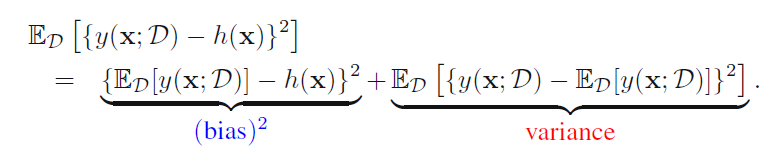
所以最终的期望错误可以分为以下几类:

机器学习的目标是减小错误,最后一部分noise无法避免,剩下的就是在bias和variance之间权衡了。所以才会第一节讲到的模型选择,选择在测试数据集上表现好的模型,达到好的trade off on bias and variance。
在线学习
之前我们所做的都是batch learning,即把所有的训练数据直接导入算法,生成结果,或者是进行batch gradient decent,现在咱们来看看我们每次用一小部分数据来训练模型的情况,这种情况适用于数据量比较大的情况,同时它的训练时间也会比较快。这种学习算法叫做stochastic gradient descent,也叫作sequential gradient descent。以下是随机梯度下降的公式,W沿着梯度方向下降一定系数的程度。η是一个学习程度的参数,越小代表每次学习的越少,这样波动越小。
En是loss function,前面加上三角符号代表了它的梯度。在实际应用中,η常常选择一个动态的值,我们可以在训练刚开始是使用较大的η,随着数据量的增张,η越来越小,方便最后结果的收敛。
References:
MLAPP
PRML















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









