






这几天在做数据挖掘实验,实验要求在 Matlab 环境下,利用 libsvm 工具包设计一个 SVM 两类分类器。在给定的数据集上进行 2-折交叉验证,另外可以使用SVMcgForClass函数寻找最优的c和g参数。
我在做实验的过程中参考了以下网址的解释,这里详细解释了libsvm中函数的使用,并且详细说明了每个参数的含义,另外还可以下载到libsvm以及SVMcgForClass函数的源代码。
http://www.matlabsky.com/thread-10966-1-1.html(很详细)
实验代码如下:
tic;
load('DATA.mat');
[N,M]=size(DATA);%N=14980,M=15
K=2;
%我觉得数据本身并不适合做归一化操作,归一化之后效果反而不好了
indices=crossvalind('Kfold',N,K);%将N个数据随机分成K份,并返回对应的索引
%%第一折
TEST1=(indices==1);%测试数据的索引
TRAIN1=~TEST1;%训练数据的索引
train1_data=DATA(TRAIN1,1:M-1);
train1_label=DATA(TRAIN1,M);
test1_data=DATA(TEST1,1:M-1);
test1_label=DATA(TEST1,M);
[bestacc1,bestc1,bestg1] = SVMcgForClass(train1_label,train1_data,-8,8,-8,8,2,1,1,4.5)
model1=svmtrain(train1_label,train1_data,'-c bestc1 -g bestg1' );
[label_train1, acc_train1,decision_train1] = svmpredict(train1_label,train1_data,model1);
[label_test1, acc_test1,decision_test1] = svmpredict(test1_label,test1_data,model1);
%%第二折
TEST2=(indices==2);%测试数据的索引
TRAIN2=~TEST2;%训练数据的索引
train2_data=DATA(TRAIN2,1:M-1);
train2_label=DATA(TRAIN2,M);
test2_data=DATA(TEST2,1:M-1);
test2_label=DATA(TEST2,M);
[bestacc2,bestc2,bestg2] = SVMcgForClass(train2_label,train2_data,-8,8,-8,8,2,1,1,4.5)
model2=svmtrain(train2_label,train2_data,'-c bestc2 -g bestg2');
[label_train2, acc_train2,decision_train2] = svmpredict(train2_label,train2_data,model2);
[label_test2, acc_test2,decision_test2] = svmpredict(test2_label,test2_data,model2);
toc;实验结果如下:
工作区中的结果变量:
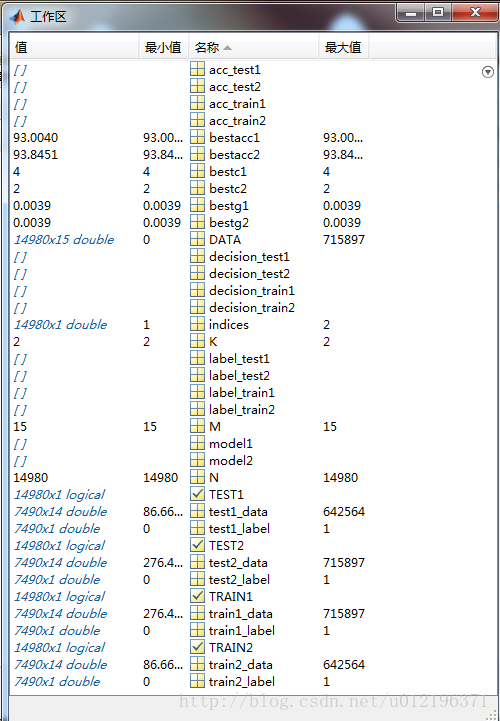
另外,由于是二折交叉验证,每一折都会在训练集上使用SVMcgForClass函数寻找最优的参数(c和g),所以一共生成了四个结果图片,如下:
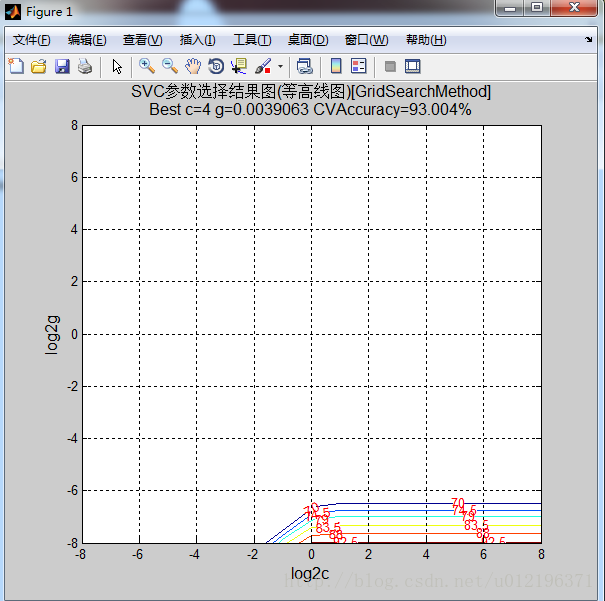
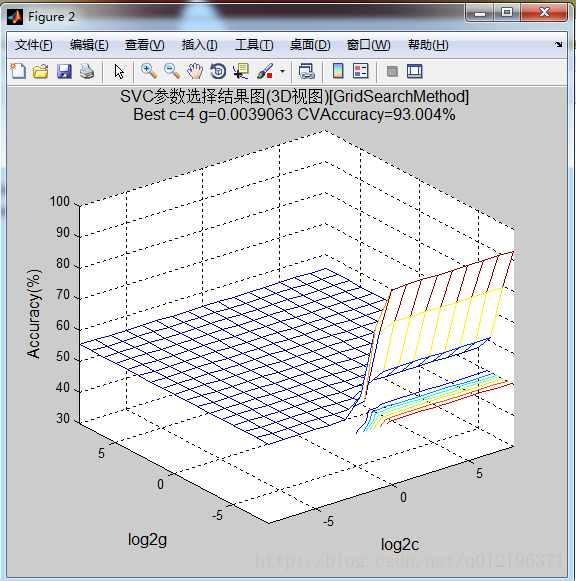
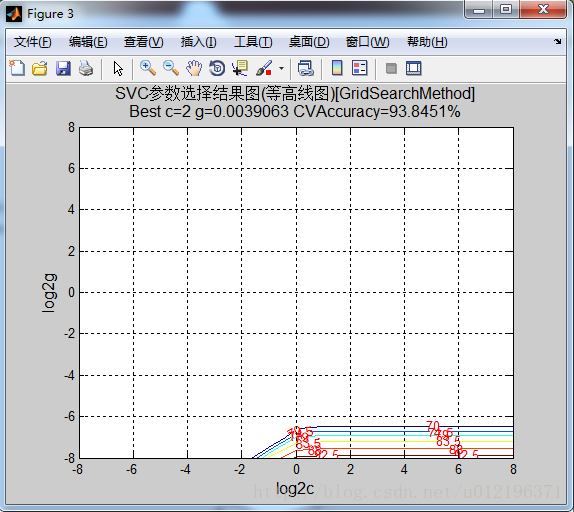
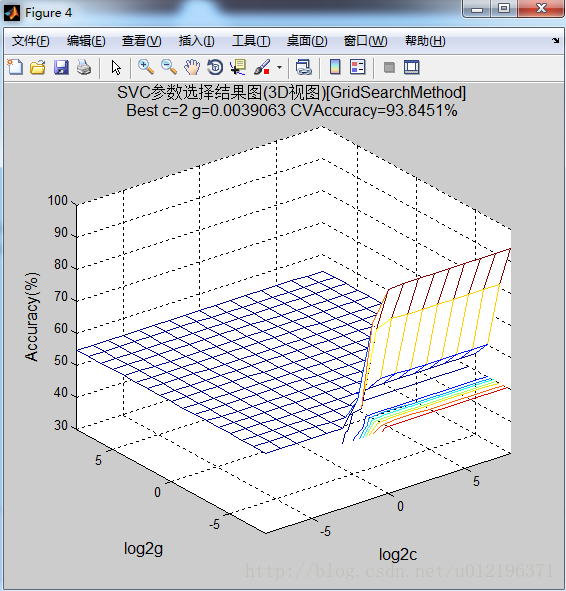
上面工作区中的结果有点奇怪啊,在找到最优的c和g之后,分别使用model1=svmtrain(train1_label, train1_data, ‘-c bestc1 -g bestg1’ )进行模型训练;使用[label_train1, acc_train1, decision_train1] = svmpredict(train1_label, train1_data, model1)对训练数据进行测试;
使用[label_test1, acc_test1, decision_test1] = svmpredict(test1_label, test1_data, model1)对测试数据进行测试;
但是model1,model2,label_train1,acc_train1, decision_train1等结果都为空,我猜想是不是训练时使用svmtrain(train1_label,train1_data,’-c bestc1 -g bestg1’ )导致的原因,于是又做了下面的实验:把svmtrain(train1_label,train1_data,’-c bestc1 -g bestg1’ )中的bestc1和bestg1直接替换成找到的最优的c和g的值(从工作区中可以看出,bestc1=4,bestg1=0.0039, bestc2=2, bestg2=0.0039),于是直接运行了这几行代码:
model1=svmtrain(train1_label,train1_data,'-c 4 -g 0.0039' );
[label_train1, acc_train1,decision_train1] = svmpredict(train1_label,train1_data,model1);
[label_test1, acc_test1,decision_test1] = svmpredict(test1_label,test1_data,model1);model2=svmtrain(train2_label,train2_data,'-c 2 -g 0.0039');
[label_train2, acc_train2,decision_train2] = svmpredict(train2_label,train2_data,model2);
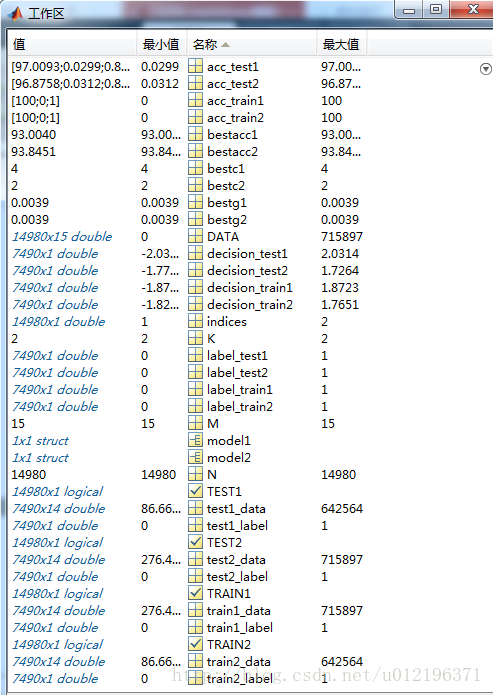
[label_test2, acc_test2,decision_test2] = svmpredict(test2_label,test2_data,model2);这样运行完成后,刚才没有的数据就都出现了,如下图:
实验结论:
1.从图上可以看出,第一折的训练准确率:100%,第一折测试准确率:97%;第二折的训练准确率是:100%,第二折的测试准确率:96.87%
2.使用找到的最优c和g训练我们的模型时,要写成’-c 4 -g 0.0039’,不要写成’-c bestc1 -g bestg1’ ,好像寻优函数并不知道字符串里面保存的是啥内容。















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









