









编写不易如果觉得不错,麻烦关注一下~
github 代码地址:https://github.com/microsoft/scene_graph_benchmark
但是目前我仔细看了只有150 个目标类可以应用在这个代码中,所以.........感觉不是很实用。
{"airplane": 1, "animal": 2, "arm": 3, "bag": 4, "banana": 5, "basket": 6, "beach": 7, "bear": 8, "bed": 9, "bench": 10, "bike": 11, "bird": 12, "board": 13, "boat": 14, "book": 15, "boot": 16, "bottle": 17, "bowl": 18, "box": 19, "boy": 20, "branch": 21, "building": 22, "bus": 23, "cabinet": 24, "cap": 25, "car": 26, "cat": 27, "chair": 28, "child": 29, "clock": 30, "coat": 31, "counter": 32, "cow": 33, "cup": 34, "curtain": 35, "desk": 36, "dog": 37, "door": 38, "drawer": 39, "ear": 40, "elephant": 41, "engine": 42, "eye": 43, "face": 44, "fence": 45, "finger": 46, "flag": 47, "flower": 48, "food": 49, "fork": 50, "fruit": 51, "giraffe": 52, "girl": 53, "glass": 54, "glove": 55, "guy": 56, "hair": 57, "hand": 58, "handle": 59, "hat": 60, "head": 61, "helmet": 62, "hill": 63, "horse": 64, "house": 65, "jacket": 66, "jean": 67, "kid": 68, "kite": 69, "lady": 70, "lamp": 71, "laptop": 72, "leaf": 73, "leg": 74, "letter": 75, "light": 76, "logo": 77, "man": 78, "men": 79, "motorcycle": 80, "mountain": 81, "mouth": 82, "neck": 83, "nose": 84, "number": 85, "orange": 86, "pant": 87, "paper": 88, "paw": 89, "people": 90, "person": 91, "phone": 92, "pillow": 93, "pizza": 94, "plane": 95, "plant": 96, "plate": 97, "player": 98, "pole": 99, "post": 100, "pot": 101, "racket": 102, "railing": 103, "rock": 104, "roof": 105, "room": 106, "screen": 107, "seat": 108, "sheep": 109, "shelf": 110, "shirt": 111, "shoe": 112, "short": 113, "sidewalk": 114, "sign": 115, "sink": 116, "skateboard": 117, "ski": 118, "skier": 119, "sneaker": 120, "snow": 121, "sock": 122, "stand": 123, "street": 124, "surfboard": 125, "table": 126, "tail": 127, "tie": 128, "tile": 129, "tire": 130, "toilet": 131, "towel": 132, "tower": 133, "track": 134, "train": 135, "tree": 136, "truck": 137, "trunk": 138, "umbrella": 139, "vase": 140, "vegetable": 141, "vehicle": 142, "wave": 143, "wheel": 144, "window": 145, "windshield": 146, "wing": 147, "wire": 148, "woman": 149, "zebra": 150}
1、出现torch._six has no attribute 'PY3' 问题
利用python 直接输出torch.__six. 按tab 补齐按键看备选项,我发现了PY37 所以将代码中的PY3改为PY37即可跑通。


2、数据集的准备
利用azcopy 工具。可以使用windows 操作。
此工具为免安装版,直接将它的路径存储到Path环境变量 即可。在cmd 命令窗口中直接输入azcopy 出现 命令后缀提示信息,即为安装成功。需要链接为双引号。
https://docs.microsoft.com/en-us/azure/storage/common/storage-use-azcopy-v10
path/to/azcopy copy 'https://penzhanwu2.blob.core.windows.net/sgg/sgg_benchmark/datasets/TASK_NAME' <target folder> --recursive(此处为github 中对应的代码段,可以根据自己的需求更改下载数据集。)

3、运行错误 module yaml has no attribute CLoader
![]()
请安装PyYAML

4、运行visual genome实例(因为模型太大,image batch 按照错误提示设置为1,原数值为4)
python -m torch.distributed.launch --nproc_per_node=1 tools/test_sg_net.py --config-file sgg_configs/vg_vrd/rel_danfeiX_FPN50_nm.yaml
正常是可以跑的。等结果出来再来分析
有些文件此github 找不到就有可能是mask rcnn github 中的,比如有的config caffe 文件

结果截图:

5、寻找只预测谓词,visual genome实例
python -m torch.distributed.launch --nproc_per_node=1 tools/test_sg_net.py --config-file CONFIG_FILE_PATH MODEL.ROI_RELATION_HEAD.MODE "predcls“
config-file 同4
6、可能(我认为6可以不看,如果其他部分有错误可以参考,但是好像这里的数据集并不需要instances_minival2014.json. 所以请避开这一部分,这里只是为了留住调试语句)
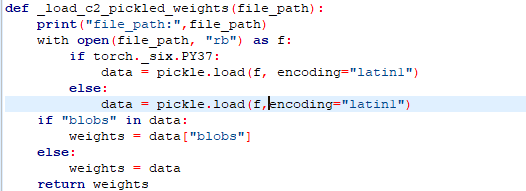
还有编码问题:
![]()
则将分支的load 的函数添加一个latin1编码即可
由于没有![]()
故将instances_val2014的名词改为instances_minival2014.json
程序又可以继续run ....

但是一次运行时间太长:尝试构建小型json

正常是可以跑的。等结果出来再来分析
又蹦出bug,
![]()
方法中缺少一个参数

之后又找到了所谓的minival2014
7、结语
经过九九八十一难,【秘籍】就是将上面生成图生成的数据文件,例如 sgg_configs/vg_vrd/rel_danfeiX_FPN50_nm.yaml,而且要准备neural motif 的参数文件,zoo_model 下载即可,我选择的bias 模式,model_final.pth 文件即可。而且为了成功,因为中间10407左右图片数据有问题,所以只让模型dataloader 使用前100个图片数据进行测试!天机不可泄露~
终于好像可以了。但是为了应用在自己的数据集上,还需要学会准备数据集的tsv格式
下面展示的测试集的前100个图片,使用的NeuralMotif 模型参数:

原文中 predcls 的截图如下,看着还有那么一回事。

















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









