










1.GAN基本思想
生成式对抗网络GAN (Generative adversarial networks) 是Goodfellow 等在2014 年提出的一种生成式模型。GAN 的核心思想来源于博弈论的纳什均衡。它设定参与游戏双方分别为一个生成器(Generator)和一个判别器(Discriminator), 生成器捕捉真实数据样本的潜在分布, 并生成新的数据样本; 判别器是一个二分类器, 判别输入是真实数据还是生成的样本。
为了取得游戏胜利, 这两个游戏参与者需要不断优化, 各自提高自己的生成能力和判别能力, 这个学习优化过程就是寻找二者之间的一个纳什均衡。生成器和判别器均可以采用目前研究火热的深度神经网络.
2.GAN结构
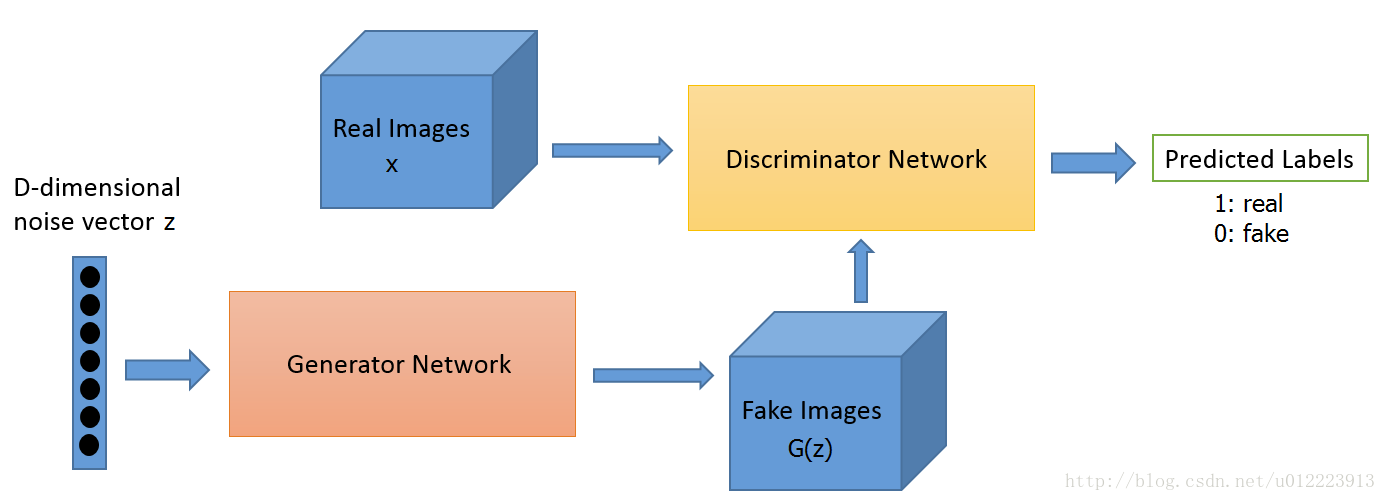
GAN的计算流程与结构如图 所示。
任意可微分的函数都可以用来表示GAN 的生成器和判别器, 由此,我们用可微分函数D 和G 来分别表示判别器和生成器, 它们的输入分别为真实数据x 和随机变量z。G(z) 为由G 生成的尽量服从真实数据分布
pdata
p
d
a
t
a
的样本。如果判别器的输入来自真实数据, 标注为1.如果输入样本为G(z), 标注为0。
这里D 的目标是实现对数据来源的二分类判别: 真(来源于真实数据x 的分布) 或者伪(来源于生成器的伪数据G(z)),而G 的目标是使自己生成的伪数据G(z) 在D 上的表现D(G(z)) 和真实数据x 在D 上的表现D(x)一致.
3.GAN 的学习方法

实际上是生成器和判别器的极大极小博弈:
D的目标是最大化V(D,G)
G的目标是最小化 max V(D,G)
4.GAN 实现
接下来实现一个vanilla GAN,生成器和判别器都是二层的神经网络。数据集采用mnist。
点击下载代码
实现结果是这样的:

接下来就来一步一步实现吧~
4.1 导入数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
from tensorflow.examples.tutorials.mnist import input_data
sess = tf.InteractiveSession()
mb_size = 128
Z_dim = 100
mnist = input_data.read_data_sets('../../MNIST_data', one_hot=True)4.2 声明变量
def weight_var(shape, name):
return tf.get_variable(name=name, shape=shape, initializer=tf.contrib.layers.xavier_initializer())
def bias_var(shape, name):
return tf.get_variable(name=name, shape=shape, initializer=tf.constant_initializer(0))
# discriminater net
X = tf.placeholder(tf.float32, shape=[None, 784], name='X')
D_W1 = weight_var([784, 128], 'D_W1')
D_b1 = bias_var([128], 'D_b1')
D_W2 = weight_var([128, 1], 'D_W2')
D_b2 = bias_var([1], 'D_b2')
theta_D = [D_W1, D_W2, D_b1, D_b2]
# generator net
Z = tf.placeholder(tf.float32, shape=[None, 100], name='Z')
G_W1 = weight_var([100, 128], 'G_W1')
G_b1 = bias_var([128], 'G_B1')
G_W2 = weight_var([128, 784], 'G_W2')
G_b2 = bias_var([784], 'G_B2')
theta_G = [G_W1, G_W2, G_b1, G_b2]
4.3 定义模型
def generator(z):
G_h1 = tf.nn.relu(tf.matmul(z, G_W1) + G_b1)
G_log_prob = tf.matmul(G_h1, G_W2) + G_b2
G_prob = tf.nn.sigmoid(G_log_prob)
return G_prob
def discriminator(x):
D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1)
D_logit = tf.matmul(D_h1, D_W2) + D_b2
D_prob = tf.nn.sigmoid(D_logit)
return D_prob, D_logit
G_sample = generator(Z)
D_real, D_logit_real = discriminator(X)
D_fake, D_logit_fake = discriminator(G_sample)4.4 设定loss function
论文中的解释如下:

由于tensorflow只能做minimize,loss function可以写成如下:
D_loss = -tf.reduce_mean(tf.log(D_real) + tf.log(1. - D_fake))
G_loss = -tf.reduce_mean(tf.log(D_fake))值得注意的是,论文中提到,比起最小化 tf.reduce_mean(1 - tf.log(D_fake)) ,最大化tf.reduce_mean(tf.log(D_fake)) 更好。
另外一种写法是利用tensorflow自带的tf.nn.sigmoid_cross_entropy_with_logits 函数:
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=D_logit_real, labels=tf.ones_like(D_logit_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=D_logit_fake, labels=tf.zeros_like(D_logit_fake)))
D_loss = D_loss_real + D_loss_fake
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=D_logit_fake, labels=tf.ones_like(D_logit_fake)))4.5 优化
D_optimizer = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D)
G_optimizer = tf.train.AdamOptimizer().minimize(G_loss, var_list=theta_G)
4.6 训练
def sample_Z(m, n):
'''Uniform prior for G(Z)'''
return np.random.uniform(-1., 1., size=[m, n])
sess.run(tf.global_variables_initializer())
for it in range(1000000):
X_mb, _ = mnist.train.next_batch(mb_size)
_, D_loss_curr = sess.run([D_optimizer, D_loss], feed_dict={
X: X_mb, Z: sample_Z(mb_size, Z_dim)})
_, G_loss_curr = sess.run([G_optimizer, G_loss], feed_dict={
Z: sample_Z(mb_size, Z_dim)})
if it % 1000 == 0:
print('Iter: {}'.format(it))
print('D loss: {:.4}'.format(D_loss_curr))
print('G_loss: {:.4}'.format(G_loss_curr))
print()4.7 保存生成的图片
在4.6 训练中的代码加入一段,每1000 step保存16张生成图片:
def sample_Z(m, n):
'''Uniform prior for G(Z)'''
return np.random.uniform(-1., 1., size=[m, n])
def plot(samples):
fig = plt.figure(figsize=(4, 4))
gs = gridspec.GridSpec(4, 4)
gs.update(wspace=0.05, hspace=0.05)
for i, sample in enumerate(samples): # [i,samples[i]] imax=16
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_aspect('equal')
plt.imshow(sample.reshape(28, 28), cmap='Greys_r')
return fig
if not os.path.exists('out/'):
os.makedirs('out/')
sess.run(tf.global_variables_initializer())
i = 0
for it in range(1000000):
if it % 1000 == 0:
samples = sess.run(G_sample, feed_dict={
Z: sample_Z(16, Z_dim)}) # 16*784
fig = plot(samples)
plt.savefig('out/{}.png'.format(str(i).zfill(3)), bbox_inches='tight')
i += 1
plt.close(fig)
X_mb, _ = mnist.train.next_batch(mb_size)
_, D_loss_curr = sess.run([D_optimizer, D_loss], feed_dict={
X: X_mb, Z: sample_Z(mb_size, Z_dim)})
_, G_loss_curr = sess.run([G_optimizer, G_loss], feed_dict={
Z: sample_Z(mb_size, Z_dim)})
if it % 1000 == 0:
print('Iter: {}'.format(it))
print('D loss: {:.4}'.format(D_loss_curr))
print('G_loss: {:.4}'.format(G_loss_curr))
print()5 reference
[1] http://wiseodd.github.io/techblog/2016/09/17/gan-tensorflow/
[2] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in Neural Information Processing Systems. 2014.
[3] 王坤峰, et al. “生成式对抗网络 GAN 的研究进展与展望.”















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









