









注意:创作不易,如果喜欢记得点赞收藏,引用请说明出处
方案名称:随机前缀和扩容RDD进行join
1、方案使用场景:如果少量KEY存在倾斜问题,可以采用此方案
2、实现思路:
2.1、先通过spark中simple方式采样一批数据进行聚合排序,查看时候存在某个KEY的数据量占比非常高,如果存在则获取这几个KEY出来,注意KEY是指需要进行join的字段
2.2、将这几个KEY在原始数据中过滤出来,通过给KEY新增随机前缀进行打散,从而让其分散到不同task中进行处理
2.3、将需要join的另外一个数据源中的相对于的KEY的数据也过滤出来,将数据膨胀与2.2中相应打散的前缀数字匹配,这样方便后续关联表join,如下图
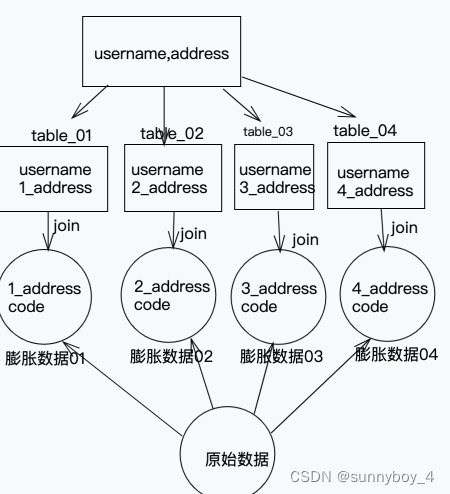
2.4、第四步将KEY的数据过滤出来,和需要join暑另一个数据源的非KEY数据获取出来进行 join
2.5、将key的join数据和非KEY的join数据union联合就得到了全部数据
3、优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
4、缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
代码如下:
原始测试数据:
database01
{'username': '王麻子', 'age': 18, 'address': '河北', 'bank': 10}
{'username': '张三', 'age': 45, 'address': '河北', 'bank': 31}
{'username': '王五', 'age': 45, 'address': '河北', 'bank': 31}
{'username': '二娃', 'age': 45, 'address': '河北', 'bank': 31}
{'username': '李四', 'age': 45, 'address': '四川', 'bank': 32}
database02
{'address':'四川','code':'0001'}
{'address':'武汉','code':'0002'}
{'address':'成都','code':'0003'}
{'address':'石家庄','code':'0004'}
{'address':'河北','code':'0005'}
{'address':'湖北','code':'0006'}
{'address':'广州','code':'0007'}
{'address':'广安','code':'0008'}
{'address':'湖南','code':'0009'}
{'address':'重庆','code':'00010'}
{'address':'河北','code':'0005'}
{'address':'河北','code':'0002'}
{'address':'河北','code':'0003'}
{'address':'河北','code':'0001'}
java源码
public class DataSkewStatistics02 {
public static void main(String[] args) {
if(args.length != 2) {
System.err.println("Usage: BigDataETL <path>");
System.exit(1);
}
SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("DataSkewStatistics").getOrCreate();
//读入数据
Dataset<String> dataset = sparkSession.read().textFile(args[0]);
//withReplacement:true、fraction:表示每个样本被选中概率
Dataset<String> randomSample = dataset.sample(true, 0.5);
JavaRDD<Row> randomRowJavaRDD = convertUserData(randomSample);
Dataset<Row> randomRowDatasetDF = convertDataFrame(sparkSession, randomRowJavaRDD);
randomRowDatasetDF.createOrReplaceTempView("random_user_data");
Dataset<Row> randomSql = randomRowDatasetDF.sqlContext().sql("select address,count(address) as user_count from random_user_data group by address order by user_count desc");
//这里可以show出来看如果某些key的占比非常大就可以考虑拿去出来多少个key,目前就拿去第一个
Row first = randomSql.first();
String address = first.getAs("address");
//筛选数据
JavaRDD<Row> globalRowJavaRDD = convertUserData(dataset);
Dataset<Row> globalRowDatasetDF = convertDataFrame(sparkSession, globalRowJavaRDD);
globalRowDatasetDF.createOrReplaceTempView("global_user_data");
Dataset<Row> skewSql = globalRowDatasetDF.sqlContext().sql("select username,age,address,bank from global_user_data where address = '" + address + "'");
//将key进行打散
JavaPairRDD<String, String> skewRandomRDD = breakUpKey(skewSql);
//排除倾斜Key的数据
Dataset<Row> commonSql = globalRowDatasetDF.sqlContext().sql("select username,age,address,bank from global_user_data where address != '" + address + "'");
//加载需要关联表的数据
Dataset<String> rightDataset = sparkSession.read().textFile(args[1]);
JavaRDD<Row> rightRowJavaRDD = convertRightData(rightDataset);
Dataset<Row> rightRowDatasetDF = convertRightDataFrame(sparkSession, rightRowJavaRDD);
//过滤出address相同key
rightRowDatasetDF.createOrReplaceTempView("global_join_code");
Dataset<Row> codeSql = rightRowDatasetDF.sqlContext().sql("select address,code from global_join_code where address = '" + address + "'");
JavaPairRDD<String, String> skewRightRDD = breakRightUpKey(codeSql);
JavaPairRDD<String, Tuple2<String, String>> skewJoinRDD = skewRandomRDD.join(skewRightRDD);
//JavaPairRDD与JavaRDD互转
JavaRDD<Row> skewData = skewJoinRDD.map(line -> RowFactory.create(line._2._1, line._1.split("_")[1], line._2._2));
//公共数据
Dataset<Row> commonCodeSql = rightRowDatasetDF.sqlContext().sql("select address,code from global_join_code where address != '" + address + "'");
//公共数据进行join
commonSql.registerTempTable("common_left_user");
commonCodeSql.registerTempTable("common_code_user");
Dataset<Row> commonDatasetJoin = sparkSession.sqlContext().sql("select a.username,a.address,b.code from common_left_user a left join common_code_user b on a.address = b.address");
JavaRDD<Row> commonData = commonDatasetJoin.javaRDD();
JavaRDD<Row> unionData = skewData.union(commonData);
System.out.println("=========");
unionData.foreach(k -> {
System.out.println(k.getString(0)+":"+k.getString(1)+k.getString(2));
});
}
//膨胀数据
private static JavaPairRDD<String, String> breakRightUpKey(Dataset<Row> codeSql){
JavaPairRDD<String, String> pairRDD = codeSql.javaRDD().flatMap(line -> {
String address = line.getAs("address");
String code = line.getAs("code");
ArrayList<Tuple2> list = new ArrayList<>();
for (int i = 0; i < 4; i++) {
Tuple2 tuple2 = new Tuple2<>(i + "_" + address, code);
list.add(tuple2);
}
return list.iterator();
}).mapToPair(word -> word);
return pairRDD;
}
private static JavaPairRDD<String, String> breakUpKey(Dataset<Row> skewSql){
JavaPairRDD<String, String> skewRandomRDD = skewSql.javaRDD().mapToPair(line -> {
Random random = new Random();
int sj = random.nextInt(4);
String address = line.getAs("address");
String username = line.getAs("username");
return new Tuple2(sj + "_" + address, username);
});
return skewRandomRDD;
}
private static Dataset<Row> convertRightDataFrame(SparkSession sparkSession,JavaRDD<Row> rightRowJavaRDD){
List<StructField> fields = new ArrayList<>();
StructField addressField = DataTypes.createStructField("address", DataTypes.StringType, true);
StructField codeField = DataTypes.createStructField("code", DataTypes.StringType, true);
fields.add(addressField);
fields.add(codeField);
StructType schema = DataTypes.createStructType(fields);
Dataset<Row> dataFrame = sparkSession.createDataFrame(rightRowJavaRDD, schema);
return dataFrame;
}
//转换JavaRDD 为DataFrame
private static Dataset<Row> convertDataFrame(SparkSession sparkSession,JavaRDD<Row> userData){
List<StructField> fields = new ArrayList<>();
StructField usernameField = DataTypes.createStructField("username", DataTypes.StringType, true);
StructField ageField = DataTypes.createStructField("age", DataTypes.LongType, true);
StructField addressField = DataTypes.createStructField("address", DataTypes.StringType, true);
StructField bankField = DataTypes.createStructField("bank", DataTypes.LongType, true);
fields.add(usernameField);
fields.add(ageField);
fields.add(addressField);
fields.add(bankField);
StructType schema = DataTypes.createStructType(fields);
Dataset<Row> dataFrame = sparkSession.createDataFrame(userData, schema);
return dataFrame;
}
//解析right数据为Row
private static JavaRDD<Row> convertRightData(Dataset<String> dataset){
JavaRDD<Row> rightData = dataset.javaRDD().map(line -> {
JsonObject jsonObject = new JsonParser().parse(line).getAsJsonObject();
String username = jsonObject.get("address").getAsString();
String code = jsonObject.get("code").getAsString();
return RowFactory.create(username, code);
});
return rightData;
}
//解析用户数据为Row
private static JavaRDD<Row> convertUserData(Dataset<String> dataset){
JavaRDD<Row> userData = dataset.javaRDD().map(line -> {
JsonObject jsonObject = new JsonParser().parse(line).getAsJsonObject();
String username = jsonObject.get("username").getAsString();
Long age = jsonObject.get("age").getAsLong();
String address = jsonObject.get("address").getAsString();
Long bank = jsonObject.get("bank").getAsLong();
return RowFactory.create(username, age, address, bank);
});
return userData;
}
}
















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











