







 本文介绍了一个整合人脸检测与人脸标注的新框架。该框架通过级联的CNN实现高效的实时处理,包括快速预选框获取、复杂CNN裁剪及强力CNN调节定位。文中还详细介绍了训练数据集构成以及在线硬样本挖掘方法。
本文介绍了一个整合人脸检测与人脸标注的新框架。该框架通过级联的CNN实现高效的实时处理,包括快速预选框获取、复杂CNN裁剪及强力CNN调节定位。文中还详细介绍了训练数据集构成以及在线硬样本挖掘方法。
1、Introduction (略)
2、Method
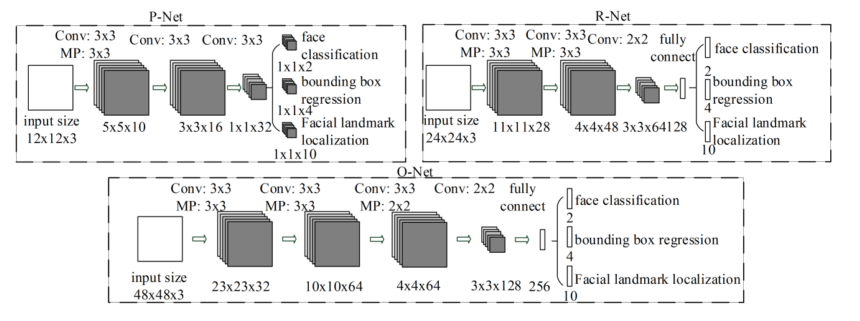
这篇文章提出了一个新的框架整合了人脸检测以及人脸标注的两个任务。这个CNN框架包含三个部分,第一部分,用浅层的cnn快速获取预选的框。然后通过一个相对复杂的cnn来裁剪大部分没有人脸的框。最后用通过一个强力的cnn来调节结果并定位人脸的关键点。
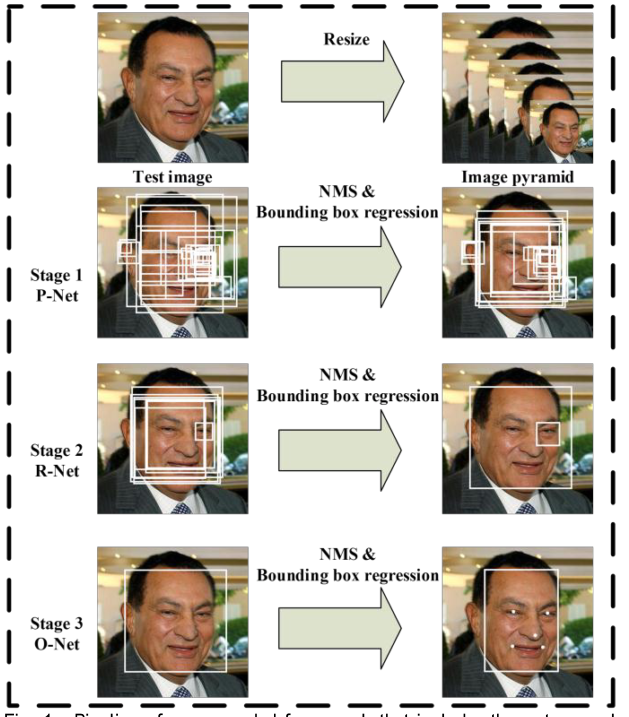
3、Contributions
- 提出了一种级联的cnn来解决人脸检测及人脸标注的联合问题,并且使用了轻量级的cnn来达到实时的效果。
- 他们提出了一种高效的方法来在线产生挖掘hard sample以提高性能。
- Extensive experiments are conducted on challenging benchmarks, to show the significant performance improvement of the proposed approach compared to the state-of-the-art techniques in both face detection and face alignment tasks.
4、Training
这个cnn分为三个任务:人脸/非人脸的检测,bounding box的回归,人脸关键点的定位。
采用的损失分别为:交叉熵损失,欧拉损失,欧拉损失。
Online hard sample mining: 在每一个mini batch, 他们按照损失将样本进行排序,将前面70%的设置为hard samples。然后只用hard samples计算梯度,忽略简单的样本。
5、Training Data
文章使用4类不同的标注数据:
- 负样本, 跟任何grounding truth的IoU小于0.3。
- 正样本,IoU大于0.65。
- part face,IoU介于0.4-0.65之间。
- Landmark faces,标注5个标注点的人脸图。
正负样本用于人脸分类,正样本和part face用于人脸bounding box的回归,Landmark faces用于人脸标注点定位。
6、论文程序运行结果




7、总结
个人见解
【缺陷,不能end to end的学习,根据我的运行结果来看,当图片比较或者人脸框较多时,检测的时间急速增加】
【优点,速度快,效果很不错】
















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









