 深度学习与神经网络原理
深度学习与神经网络原理





 本文深入探讨了单层感知器的线性决策边界限制,以及如何通过多层网络实现高度非线性的决策表面。详细介绍了Sigmoid单元及其在神经网络中的作用,以及反向传播算法的工作流程,包括权重更新步骤。
本文深入探讨了单层感知器的线性决策边界限制,以及如何通过多层网络实现高度非线性的决策表面。详细介绍了Sigmoid单元及其在神经网络中的作用,以及反向传播算法的工作流程,包括权重更新步骤。
•Single Layer Perceptron can Only
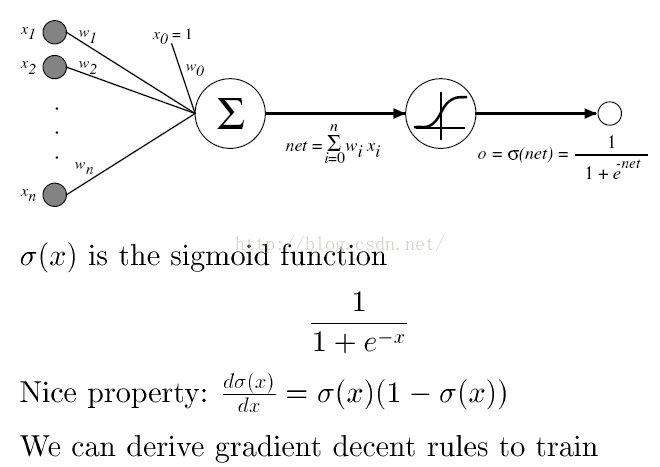
express linear decision surfaces
![]()
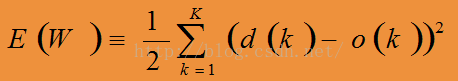
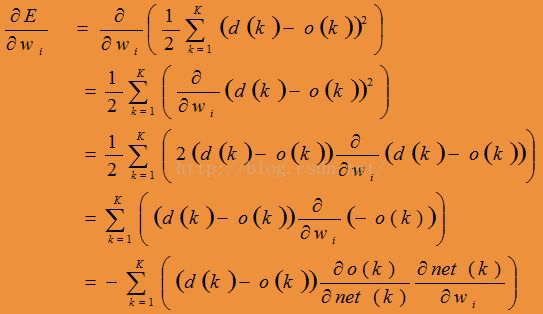
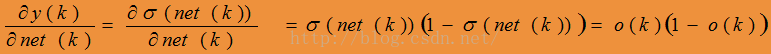
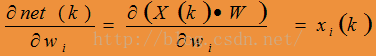
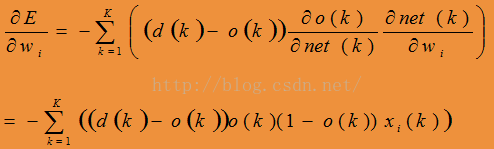
![]()
![]()
![]()
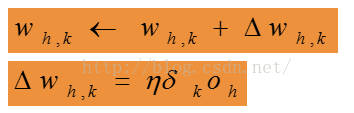
![]()
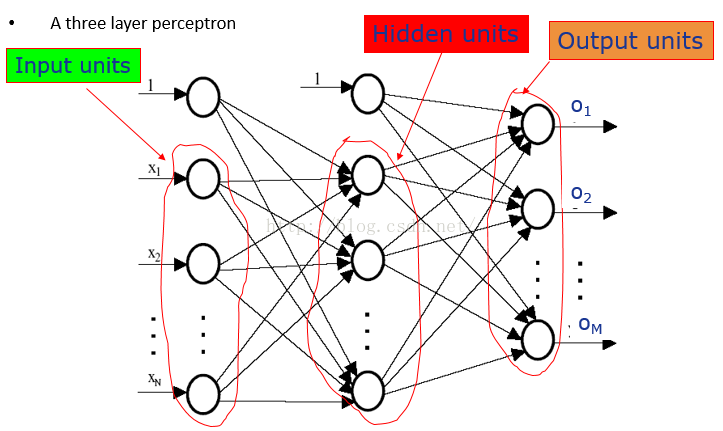
•We can build a multilayer network represent the highly nonlinear decision surfaces
Sigmoid Unit
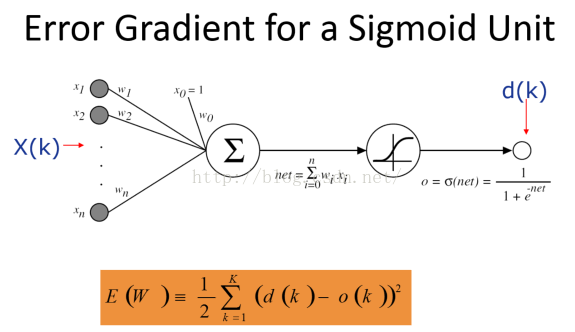
Back-propagation Algorithm
•For each training example, training involves following steps
Step 1: Present the training sample, calculate the outputs
(初始时,对于每一层的每个感知器的权重向量全是很小的随机数。)

Step 2: For each output unit k, calculate
(对于输出层的每个感知器)

Step 3: For hidden unit h, calculate
(对于隐藏层的每个感知器)


(k为输出层的感知器或者是下一层的感知器)、
Step 4: Update the output layer weights, wh,k
(更新输出层每个感知器的权重向量)where oh is the output of hidden layer h



Step 5: Update the hidden layer weights, wi,h
(更新隐藏层的每个感知器的权重向量)

如此迭代
通过梯度下降来更新神经网络中的权重向量,这样我们可能得到的只是一个局部极小值而不是全局最小值,但是在实践中神经网络表现不错。

















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









