










双十一是大丰收之日,不如也来个blog大丰收吧!(其实是因为,我没有抢到想要的!「呵呵」)
2016.02.05
Hadoop学习
51CTO是一个神奇的网站!
Hadoop安装
要点:
1. HADOOP_HOME不可用(/bin和/sbin中可能会生成对于该系统变量的使用),所以用HADOOP_INSTALL来替代
2. 在Linux中配置path是用:冒号进行分隔的
3. which gedit 可以查看gedit的目录
4. 若用Ubuntu或者debain系统,sudo gedit environment可以编辑path值
5. source environment或者其他配置文件名,可以使得配置文件中的内容立即生效
6. echo $HADOOP_INSTALL可以查看path是否已经生效
7. hadoop version查看hadoop是否已经生效,若未生效,则重启Ubuntu
8. Hadoop的安装过程:
(1) hadoop下载(apache-releases-binary-复制链接)
挂载目录-cd /mnt/hgfs
解压缩-tar zxvf
Binary直接就是可执行目录!我的天!!!
(2) 安装
(3) 配置HADOOP_INSTALL和PATH环境变量/etc/environment
(4) 测试安装 hadoop version
Hadoop简介
- 特点:分布式、可靠性、可伸缩
- 擅长:搜索引擎、海量数据存储
发展史
- 2002年Apache Nutch
- 2003年GFS论文
- 2004年Nutch NDFS->HDFS
- 2004年Google-MapReduce
现状
- Yahoo:广告/用户行为分析/反垃圾邮件
- 阿里:淘宝/天猫/支付宝/秒杀
- 腾讯:游戏/QQ/财付通
需要解决的核心问题(网页/网络)Hadoop集群!商业价值!!
海量数据(量级:t/p/e/z/y)
1. 怎么存储?分隔开来,放到多个主机上—->分布式存储dfs:distributed file system(hadoop)
2. 怎么运算?MapReduce->映射&化简
存储是基础,并发执行!
VMware安装与配置
- Virtualbox属于oracle?
- VMware workstation pro->x86版本(硬件要求:8G内存以上+SSD硬盘)
Ubuntu下载与虚拟机下安装
Ubuntu-Server-12.04-amd64
Hadoop配置
三种模式:独立模式(本地模式)MapReduce、伪分布式、完全分布式
1. 独立模式没有守护程序运行:jps命令行后发现除了jps外没有其他java进程正在运行
2. Hadoop fs -ls /:向hadoop发送ls / 指令 发现独立模式下是本地模式
3. Local job runner
2016.02.06
Hadoop配置伪分布式
- Core-site.xml - 名称节点配置(hdfs://localhost/)
- Hdfs-site.xml - 数据节点的个数(伪分布式下为1)
- mapred-site.xml - mapreduce的框架(Hadoop2.0下为yarn)
- Yarn-site.xml - yarn的资源管理器及节点管理器(localhost & mapreduce shuffle)
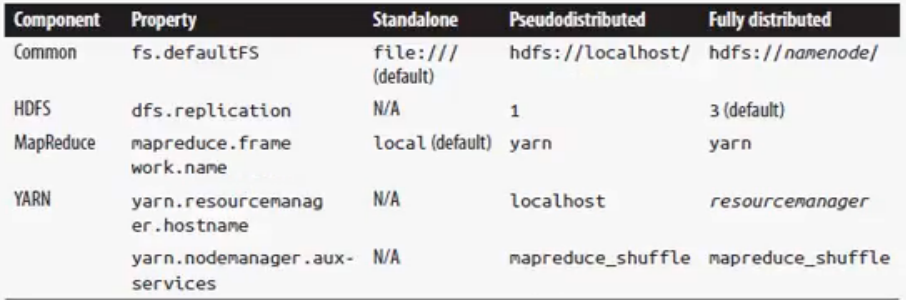
- Namenode-NN存放整个文件系统的目录(备份文件称为Secondary node)
- Datanode-DN存放实际数据(备份文件称为副本)


- config ssh:并没有区分伪分布模式和完全分布模式,在单个主机上运行的伪分布式是完全分布模式的一种特例。
- sudo apt-cache search xxx 查询所有满足xxx名称的开源包
- sudo apt-get install xxx
- ssh-keygen 生成秘钥(网络上的一种非对称加密通信:用公钥加密,私钥解密)
- ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa(.ssh表示其为隐藏文件目录)
cat id_rsa.pub >> authorized_keys
开启过程
start-dfs.sh --config $HADOOP_INSTALL/etc/hadoop/hadoop-pseudo
start-yarn.sh --config $HADOOP_INSTALL/etc/hadoop/hadoop-pseudo
Mr-jobhistory-daemon.sh start history server
# 或者使用
start-all.sh关闭过程
stop-yarn.sh-关闭集群管理器(yarn-resourcemanager-nodemanager)
stop-dfs.sh-关闭dfs
Localhost:50070-可以访问namenode
Localhost:8088-可以访问资源管理器节点cluster
Localhost:19888-历史服务器设置hadoop_conf_dir环境变量:
export HADOOP_CONF_DIR=$HADOOP_INSTALL/hadoop/pseudo
# Hadoop中的文件操作与基本的Linux下的文件操作基本保持一致。Hadoop win7下
- Dexpot - 多窗口管理页面
- Hadoop-Common-master-2.2.0:解压master.zip\bin* 复制到${hadoop_install}\bin\下,忽略覆盖
MapReduce编程
- Jar包引入:
必须加入所有的hadoop项目中的jar包,并去除所有的test和source包 - Mapper中的参数「keyIn,valueIn,keyOut,valueOut」 -> import hadoop.io
- Context.write(new Text(year), new IntWritable(teparature))//必须和extends Mapper中的输出结果相同,泛型!!
- Refactor->rename可以一次性改变所有相同的变量的名称
- Math.max(),我的天,惊呆了!
- 补充一下一个神奇的eclipse快捷键用法:
Alt+Shift+J(光标放在方法名上) -> 快速生成如下的注释行!
/**
* @param str
* @return
* @throws ParseException
*/
/*光标放在其他位置一般效果为生成文件Author注释行!*//**
* @author ZF *
*/
/*你值得拥有! */- APP类 - 入口函数
Job job = new Job();// Mapred 为旧版本的 API;mapreduce 为新版本的 API
Job.setJarByClass(Max Temprature);//本类 job.setJobName(“max”);//设置作业名称,便与调试
FileInputFormat.addInputPath(job, new Path(arg[0]));//添加输入路径,可以添加多个路 径,且 //输入文件不仅可以是一个具体文件,也可以是一个文件夹(路径,但不是递归 引入的)
FileOutFormat.setOutPath(job, new Path(arg[1])); //设置输出路径,而且不能存在该输出路径,不然会报错//引入 hadoop.fs.Path 包
job.setMapperClass(MaxTemparatureMapper.class);//设置 mapper 类
job.setReducerClass(MaxTemparatureReducer.class);//设置 reducer 类
job.setOutputKeyClass(Text.class);//设置输出的 key 类型
job.setOutputValueClass(IntWritable.class);//设置输出的 value 类型
job.waitForCompletion(true);//等待作业的完成,之后可以再这里解决乱码问题- 最终运行
导出 jar 包(java->jar 文件) / 设置 main class / 查看 jar / 运行 设置环境变量
- Win7: set HADOOP_CLASSPATH=HadoopDemo2.jar
- Linux:
- export HADOOP_CLASSPATH=HadoopDemo2.jar //记得设置堆内存大小
- hadoop -Xmx1000m jar com.shu.zhou.main file:///c:\a\19*.gz d:\x\out
- 在集群中运行(非常相似) 上传文件到 hadoop 集群中:
Hadoop fs -put /path # (-R表示递归显示)














 1729
1729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









