










Note_1
虽然我很想吐槽这笔记的视频出处==,但是类比做不错。
- 流处理 like 以前的定时批处理。
- Spark 作业动态生成三大核心:
- JobGenerator:负责 Job 生成。 「基于 DStream 生成 Job 」
- JobSheduler:负责 Job 调度。 「 like Runnable 线程的操作」
- ReceiverTracker:获取元数据。
- Spark Streaming 基于定时/状态操作参数 Job ,还可以进行聚合操作。
- 每 5 秒钟 JobGenerator 都会产生 Job ,基于 DStream 构建的依赖关系导致的 Job 是逻辑级别的,底层是基于 RDD 的逻辑级别的。
val ssc = new StreamingContext(conf, Seconds(5)) - 当我们的 JobScheduler 要调度 Job 的时候,转过来在线程池中拿出一条线程执行封装的方法。

引自:
第6课:Spark Streaming源码解读之Job动态生成和深度思考
Note_2
infoq这篇果然可以啊!And 这段引言不错嘛!
引言
Apache Spark 框架/使用 Spark SQL 库访问数据这些方案是基于批处理模式下静态信息处理的,比如作为一个按小时或天运行的任务。但若是在数据驱动的业务决策场景下,当需要飞快地分析实时数据流以执行分析并创建决策支持时,又该如何呢?
使用流式数据处理,一旦数据到达计算就会被实时完成,而非作为批处理任务。实时数据处理与分析正在变为大多数组织的大数据战略中至关重要的一个组件。
常见的流数据的例子有网站上的用户行为、监控数据、服务器日志与其他事件数据。流数据处理应用会有助于现场面板、实时在线推荐与即时诈骗检测。
Spark 流正在变为实现实时数据处理与分析方案的首选平台,这些实时数据往往来源于物联网( Internet of Things,IoT )和传感器。
Uber - 实时遥测分析,Pinterest - 可视化书签工具,Netflix - 实时在线电影推荐与数据监控。在本文中,我们将会学习到如何使用 Apache Spark 中一个被称为 Spark 流的库进行实时数据分析,并以一个网络服务器日志分析用例,展示 Spark 流是如何帮助我们对持续产生的数据流进行分析的。
工作原理介绍
Spark 流工作的方式是将数据流按照预先定义的间隔( N 秒)划分为批(称微批次),然后将每批数据视为一个弹性分布式数据集。随后我们就可以使用诸如 map 、reduce、reduceByKey、join 和 window 这样的操作来处理这些 RDDs 。
- RDD 操作的结果会以批的形式返回。通常我们会将这些结果保存到数据存储中以供未来分析并生成报表与面板,或是发送基于事件的预警。
- 合理为 Spark 流决定时间间隔
- 用微批次的方法,我们可以在同一应用下使用 Spark 流 API 来应用其他 Spark 库(比如核心、机器学习等)。
- 流数据可以来源于许多不同的数据源。下面列出一些这样的数据源:
- Kafka
- Flume
- ZeroMQ
- Amazon’s Kinesis
- TCP sockets「啊?666。。」
同系统中组合批处理与 Streaming/MLlib 与 GraphX :

详细条目
三种不同的流数据处理框架:
「其他流处理框架是基于每个事件而非一个微批次来处理数据流的」- Apache Samza
- Storm
- Spark 流
Spark 流的两个组件:
- DStream:描述了一个持续的数据流,在内部被描述为一个 RDD 对象的序列。「好像 RDD 基本操作==」
- like RDD
- map
- flatMap
- filter
- count
- reduce
- countByValue
- reduceByKey
- join
- updateStateByKey
- window/stateful
- window
- countByWindow
- reduceByWindow
- countByValueAndWindow
- reduceByKeyAndWindow
- updateStateByKey
- like RDD
- 流上下文:与 Spark 中的 Spark 上下文( SparkContext )相似,流上下文( StreamingContext )是所有流功能的主入口。「流上下文拥有内置方法可以将流数据接收到 Spark 流程序中!!!凭这点你赢了。」
- start() - 启动计算
- awaitTermination() - 等待计算终结
- DStream:描述了一个持续的数据流,在内部被描述为一个 RDD 对象的序列。「好像 RDD 基本操作==」
- Spark 编程的步骤:
- 用两个参数初始化流上下文对象:Spark 上下文和切片间隔时间
- 切片间隔 - 流中处理输入数据的更新窗口
- 上下文初始化后,无法再向已存在的上下文中定义或添加新的计算
- 同一时间只有一个流上下文对象可以被激活
- 创建输入 DStreams 以指定输入数据源
- 使用 map 和 reduce 这样的 Spark 流变换 API 为 DStreams 定义计算
- 使用流上下文对象中的 start 方法来开始接收并处理数据
- 使用流上下文对象的 awaitTermination 方法等待流数据处理完毕并停止它。
- 用两个参数初始化流上下文对象:Spark 上下文和切片间隔时间
简例
==,明天再看,说好的 早睡 !!!
引自:
用 Apache Spark 进行大数据处理——第三部分:Spark 流
Note_3
是时候找研究生大大们 down 一下别人的论文了。。
引自:
Note_4
一个 2011年11月21日(有点旧啊)的百度分享,基于hadoop。可参考部分思路,这张图算是有点意思吧!以后做这类设计可以引荐一下。
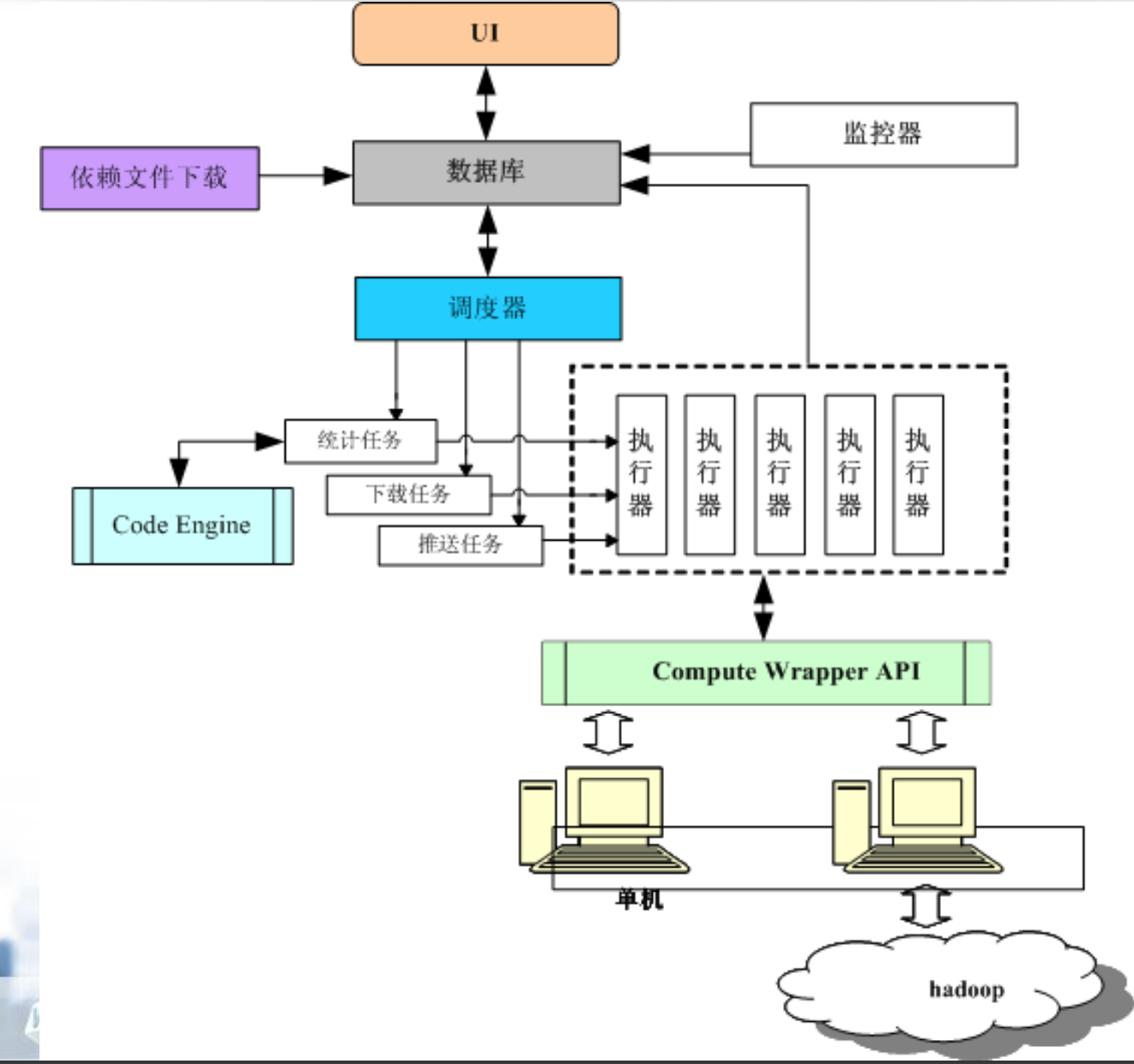
引自:
Note_5
官方 Spark Streaming 标例 network_wordcount standalone 模式下执行:
# $SPARK_HOME/sbin/start-master.sh
# spark-submit --master local[2] $SPARK_HOME/examples/src/main/python/streaming/network_wordcount.py localhost 9999
# nc -lk 9999
xxxxx xxxx
xxxx xxxNote_6
看到是基于nodejs的介绍点进去的。一个看起来不错但是 git 上文件不可见的项目。。
「系统笔记 Sevnote 是使用 NodeJS 开发的基于 Elasticsearch 的海量日志分析系统,能通过主机,设备,程序,优先级,关键字来过滤系统日志,更有动态仪表盘能实时的监控日志的产生。」
引自:
Note_7
mark 一下 elasticsearch,看的几个项目介绍都是基于这个做的。 wait to be watched…
Note_8 - Spark Streaming
人民邮电出版社「 Spark 快速大数据分析 」笔记
DStream -> 离散化「每个时间区间的数据都以 RDD 存在」
操作
- 转化操作
- 无状态
- map()
- flatMap()
- filter()
- repartition()
- reduceByKey()
- groupByKey()
- transform()
- 有状态
- reduceByWindow()
- reduceByKeyAndWindow()
- updateStateByKey()「跨批次维护状态函数」
- …(其他window操作)
- 输出操作
- print()
- save()
- foreachRDD()
- …(其他)
输入源
- 核心输入源
- 文件流 ssc.textFileStream(logDirectory)
- Akka actor流 不常见
- 附加输入源
- Apache Kafka
- Apache Flume
- 推式接收器
- 拉式接收器
- 自定义
多数据源和集群规模
与接收器数目相同的核心数
24/7不间断工作
- 检查点机制
- 控制失败时的重算状态数
- 提供驱动器程序容错
- ssc.checkpoint(directory)
- 驱动器程序容错
- sc.getOrCreate(checkpointDir,sscFactoryObj)
- 独立模式:zookeeper
- 集群模式:–deploymode cluster –supervisor(出错时重启进程)
- 工作节点容错 -> RDD 谱系图
- 接收器容错 -> 可靠数据源(,底层也提供了备份)
- 处理保证
Note_9 - Storm
机械工业出版社「 Storm 企业级应用实战/运维和调优 」笔记
认识 Storm
- 特征
- 持续处理「常驻任务」
- 近似性/自适应性
- 应用
- 实时数据源,对用户相应时间亦实时
- 数据量大,但要求对用户响应时间实时
- 处理
- 实时采集(要求实时/可靠/部署容易)「以下皆可达到每秒数百 MB 」
- Scribe (Facebook)
- Kafka (LinkedIn)
- Flume (Cloudera)
- TimeTunnel (Alibaba)
- Chukwa (Hadoop)
- 实时计算(要求不间断/稳定/扩展性好/可维护性好)
- 传统:用户查询 -> DBMS -> 查询结果
- 流处理:
- 处理节点1 -> 数据流流入 -> 处理节点2 -> 数据流流出 -> 处理节点3
- 处理节点2 -> 计算节点 -> 数据存储
- 实时查询(全内存/半内存/全磁盘)
- 半内存
- Redis
- Memcache
- MangoDB
- BerkeleyDB
- 全磁盘(HDFS 下 HBase)
- 实时计算框架
- StreamBase (IBM)
- S4 (Yahoo)
- Storm (Twitter)「Clojure/Java/Ruby/Python」
- Rainbird (Twitter)
- Puma (Facebook)
- JStorm (Alibaba)
- HStreaming
- Esper
- Borealis
- 处理瓶颈
- 流式处理 -> 实时框架
- NoSQL -> 数据大规模存储计算
Hadoop 与 Storm 角色与组件比较
- 系统角色
- JobTracker & Nimbus -> 主节点
- TaskTracker & Supervisor -> 工作节点
- Child & Worker -> 工作进程
- 应用名称
- Job & Topology
- 组件接口
- Mapper/Reducer & Spout/Bolt
- 补充
- kill -9 杀死 Nimbus 和 Supervisor 进程
- Nimbus 和 Supervisor 进程具有快速失败和无状态的特性,所以需要使用 zookeeper 或者本地的方式。
- Storm 的核心包括 Nimbus/Supervisor/Worker/任务线程 Task ( Bolt / Spout )
- 在 Nimbus 和 Supervisor 间协调 zookeeper
Storm 特点
- 编程模型简单
- 可扩展
- 高可靠性
- 高容错性
- 支持多种编程语言
- 支持本地模式
- 高效 -> ZeroMQ
- Storm 的功能
- 实时分析/在线机器学习/持续计算/分布式 RPC /ETL
- 三大应用
- 信息流处理
- 持续计算
- distributed RPC
开始使用 Storm(略)
- JDK 1.6 + SSH + Python 2.6.6
- ZooKeeper
- ZeroMQ 2.1.7
- J2MQ
- Storm 0.8.2
- …
核心概念与数据流模型
- Tuple 元组 -> 键值对
- open(conf, context, collector)
- nextTuple()
- ack(obj msgid)
- fail(obj msgid)
- close()
- spout 数据源
- open(conf, context, collector)
- declareOutputFields(declarer)
- nextTuple()
- getComponentConfiguration/ack/fail/close/…
- Bolt 消息处理者
- 创建 Bolts
- 序列化
- 开始 worker 进程处理
- 反序列
- 调用 prepare 处理 Tuple
- Topoloty 拓扑
- Stream 消息流和 Stream Grouping 消息流组
- Task 任务
- Worker 工作者进程
- 事务(容错/严格要求/实时计算处理)
- 数据流模型
- 主要内容
- 数据流
- 数据处理任务
- 数据节点
- 数据处理任务实例
- 步骤
- 定义数据流
- 定义数据处理任务
- 定义数据处理节点
- 定义数据处理任务实例
- 读取数据源头产生的数据流
- 节点上运行任务实例
- 下一个节点运行任务实例,直至到达数据流末节点
- 输出结果















 6839
6839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









