







go语言
开源的编程语言,2007诞生,2009开源
特点
1.运行效率高-编译型语言;开发高效-语法简单;部署简单-直接运行,编译迅速
2.语言层支持并发,易于利用多核实现并发
3.内置runtime,性能监控,GC垃圾回收
4.简单易学,丰富的标准库,网络库,开源
5.gofmt内置强大的工具
应用场景
服务器编程
分布式系统,中间件等
网络编程,web
云平台,docker-go开发的
环境搭建
https://studygolang.com/dl 下载对应版本安装
设置环境变量
PATH里加上go的安装目录到bin路径
GOROOT:go语言安装路径
GOPATH:go语言源码存放路径,可设置多个目录
go命令行
go build 编译源码文件,代码包,依赖包等
go run 编译并运行go源码文件
go get 动态获取远程代码包
基础语法
关键字,标识符:25个关键字,36个预定标识符(包括基础数据类型和系统内嵌函数)
注释和基础结构://单行注释,/**/多行注释
import依赖包,常量变量声明赋值,结构体,接口,主函数,类型声明
第一个go程序
创建firstGo.go文件,go语言源文件扩展名为*.go
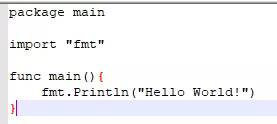
在firstGo.go文件目录下打开命令行,输入go run firstGo.go,运行go语言程序,结果如下
开发go语言推荐使用IDE:LiteIDE

下载地址:http://liteide.org/cn/download/
选择需要安装的版本进行下载,我下载的是liteidex36.windows-qt5.9.5.zip,下载后直接解压,进入到解压后文件夹中的bin目录,双击liteide.exe运行IDE
IDE打开后的起始页有LiteIDE的使用方法,可以看看















 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









