








标题:BASE:在查询优化的成本和延迟之间架起桥梁
***摘要***:查询优化一直是数据库领域的一个基础而又具有挑战性的课题。最近的一些研究显示了基于强化学习(RL)的学习查询优化器的优势,而不是依赖于手工制作的成本模型。这些工作通常使用成本(即成本模型的估计)或延迟(即执行计划的时间)作为训练其学习模型的指导信号。然而,基于成本的学习存在延迟性能不理想的问题,而基于延迟的学习则非常耗时。为了绕过这一困境,研究人员试图将学习值网络从Cost域转移到Latency域。在本文中,我们确定了关于基于成本/延迟的训练的几个有价值的观察结果,这些观察结果激励我们直接转移奖励函数,而不是价值网络。基于这个想法,我们提出了一个两阶段的基于RL的框架BASE,以弥合成本和延迟之间的gap。在第一阶段学习了基于成本信号的策略后,BASE将奖励函数的传递过程表述为逆强化学习的一种变体。直观地,BASE学习校准奖励函数,并以一种相互改进的方式更新校准后的奖励函数的策略。大量的实验显示了BASE在两个基准数据集上的优势:与SOTA方法相比,我们的学习优化器平均节省了30%的训练时间,也优于传统DBMS。同时,BASE也进一步适用于其他基于学习的优化器,并使这些优化器更加高效,证实了传递奖励函数的有效性。
介绍
查询优化器是数据库管理系统(DBMS)中的一个关键组件,用于为每个给定的SQL查询找到最有效的执行计划。近年来,机器学习(ML)增强DBMS的研究越来越受到关注,并显示出以数据驱动的方式提升数据库性能的优越性[1,9,17]。特别是,强化学习(RL)被应用于生成执行计划,并展示了其在寻找竞争执行计划方面的优势,而不需要启发式方法[6,11,12,21]。
强化学习以试错的方式训练策略,以最大化/最小化奖励函数的累积回报。当应用于查询优化时,学习的查询优化器根据其当前策略生成执行计划,并检索奖励作为反馈,表示该计划的好坏。然后,优化器可以根据奖励更新策略,使好的计划更有可能实现,而坏的计划更不可能实现。因此,优化器可以从奖励函数中学习,使其策略更好。通常,奖励函数中可以考虑两种类型的信号:成本和延迟。成本是指DBMS成本模型对一个执行计划估计的计算量。数据库用户真正关心的延迟,是执行计划的实际时间成本。事实上,最近的工作已经显示了基于强化学习的查询优化的前景。它们的共同之处在于,它们学习了一个将执行计划映射到累积奖励(即执行计划的总成本/延迟)的价值网络。因此,他们可以通过搜索网络输出的最小值来贪婪地选择最优计划。不同之处在于它们如何使用这两个信号来设置奖励功能,奖励功能可以分为三种类型。第一类工作,如Rejoin[12],只考虑奖励函数中的成本信号。第二种类型的工作使用延迟信号训练它们的策略。例如,Bao[10]以监督回归的方式通过延迟来训练其价值网络。Neo[11]通过回归演示(即传统查询优化器生成的计划)的延迟信号来预训练值网络。预训练策略减少了需要执行的计划的数量。第三种类型的工作同时利用了成本和延迟。DQ[6]和RTOS[21]都使用成本对价值网络进行预训练,然后将其从成本域转移到延迟域。他们假设特征提取器(除了网络的最后一层)可以在这两个域之间共享,因此只有最后一层需要学习延迟信号。
尽管上述工作已经显示出不错的结果,但我们对它们进行了深入研究,并确定了一些关于训练查询优化策略的观察结果。OBS-1:成本和延迟通常不一致,因此关于成本的最优策略可能不会产生导致最小延迟的执行计划。OBS-2:直接学习具有延迟的策略非常耗时,因为它需要花费大量时间来执行生成的计划以收集延迟信号,更不用说一些糟糕的计划甚至需要几天才能完成。OBS-3:尽管存在OBS-1,但就其相应的最优策略的行为而言,只有一小部分查询在成本和延迟之间表现出很大的差距。我们在第3节中提供了更多关于这些观察结果的经验证据。OBS-1和OBS-2提出了有效性vs效率-困境:我们需要学习一个关于延迟而不是成本的最佳策略,但是为了有效的训练,执行的次数必须最小化。根据OBS-1,只有成本的方法,如Rejoin,可以实现高效的训练,但他们学习的策略在延迟方面是不完美的。Neo和Bao等纯延迟方法的关键问题在于如何减少需要执行的计划数量。他们使用的价值回归需要在好的和坏的经验上进行,以了解应该采取哪种执行计划[4]。预训练的价值网络从几乎没有好的经验中学习,所以它仍然需要探索许多计划来改进自己。对于DQ和RTOS,他们试图实现高效的训练。即使特征提取器假设成立,学习随机初始化的最后一层仍然是低效的,因为它在执行探索时没有利用成本域的经验。
为了从成本域和延迟域中获益,现在的问题是:我们如何维持从成本域学到的知识,并将其改进到延迟域?我们提出了一种新颖的解决方案,不像以前的方法那样去掉成本信号,而是将奖励函数和策略以一种相互改进的方式从成本域转移到延迟域。直观地说,成本和延迟之间的差距导致了不同的最优策略。如果我们能够弥合这一差距,即校准“错误的”基于成本的奖励函数,那么在校准奖励函数的基础上求解最优策略,将很容易产生具有最佳延迟性能的策略。第二个问题来了:直接致力于奖励函数而不是价值函数的好处是什么?根据OBS-3,只有在一部分查询中,成本和延迟才会导致不同的最优计划。通过传递奖励函数,我们只需要消除这种冲突。相比之下,成本和延迟对应的最优值函数之间的差异比最优策略要大得多,这使得传递值函数需要更多的训练样本和微调步骤。
基于传递奖励函数的好处,我们提出了一个基于两阶段强化学习的框架BASE来学习查询优化器。在BASE的第一阶段,我们使用成本信号预训练策略,期望该策略能够有效地收敛于所采用DBMS的查询优化器。在BASE的第二阶段,我们将预训练策略转移到延迟域。受OBS-3的启发,BASE采用了奖励函数的校准函数来填补延迟的空白。校准功能将纠正在延迟方面导致糟糕执行计划的成本。BASE将定位和填充gap的过程表述为逆强化学习(IRL)的一种变体:
-
为了找到gap,BASE利用主动学习(AL)技术来选择当前奖励函数可能导致延迟冲突的潜在查询和计划。从相应最优策略的行为角度来讨论冲突,定义了两个选择标准——多样性和信息性,并借助当前的策略网络进行度量。然后将执行选定的计划来收集延迟信号。这一步类似于在一些IRL方法中主动请求标签来更新基于分类器的奖励函数[18]。
-
为了填补gap,通过鼓励校准函数将当前奖励函数与新收集的矛盾样本(即查询-计划 对)的延迟关联起来,同时保持它们在其他样本上的一致性,从而更新校准函数。然后根据校准后的奖励函数更新当前的策略。这一步对应于IRL公式的内部循环。
该策略通过发现更多需要消除的冲突来改进奖励函数。校正后的奖励函数通过提供更一致的监督来改善策略。通过重复这样的过程,冲突逐渐被发现并固定,学习到的校准函数将使奖励函数接近延迟。因此,学习的策略在延迟方面变得最优。
我们进行了大量的实验来证明我们的方法的训练效率和延迟性能。与现有的方法相比,BASE平均缩短了30%的训练时间,从而优于传统的DBMS。通过执行一定数量的查询,BASE比其他方法减少了9%以上的延迟。同时,BASE还进一步应用于其他基于学习的优化器,如ML-steered query optimizer,大大提高了训练效率,证实了BASE技术的鲁棒性。
本文的贡献总结如下:
-
我们实证分析了SOTA的基于RL的查询优化方法,并确定了其基于成本/延迟的训练过程的可行性和挑战(见第3节)。
-
我们提出了一个两阶段的基于RL的框架BASE来有效地学习端到端查询优化器。优化器可以预测每个给定查询的完整执行计划,包括连接顺序、索引和物理操作符选择,并且具有令人满意的延迟性能(见第4节)。
-
据我们所知,这是第一个使用IRL公式将策略从成本域转移到延迟域的工作。同时,我们进行了理论分析,为传递奖励函数提供了理论依据(第5节)。
-
我们在基准上进行了大量的实验,证明了BASE的优越性和实用性(见第6节)。
问题陈述
2.1 Problem Settings
-
Query Optimization
对于一个SQL查询𝑞,Rel(𝑞)是𝑞中所有基本关系的集合。每个查询执行计划𝑝都可以用计划树表示。树的每个叶节点都是一个关系∈Rel(𝑞)。特定叶节点的每个关系𝑏也用scan类型𝑒∈E来指定,其中E表示所有scan类型的集合,例如顺序扫描Seq(𝑏)和索引扫描Index(𝑏)。其他的非叶树节点是连接实现
∈𝐽,其中𝐽表示所有连接实现的集合,例如:嵌套循环连接
,合并连接
,哈希连接
。𝑝将以自下而上的顺序执行,因此它指定了一个连接顺序。
端到端查询优化器𝑄𝑂可以将给定的SQL查询𝑞直接映射到执行计划𝑝。执行计划的时间通常称为延迟。DBMS成本模型可以估计一个执行计划的成本,预计它会反映计划的延迟,但在实践中它们并不是正相关的。本文的研究目标如下:
Objective 1:给定一个DBMS、一个数据集和一个训练工作量,我们的目标是有效地学习一个𝑄𝑂来取代DBMS中基于成本的优化器。学习到的𝑄𝑂生成具有最小执行延迟的测试工作负载的查询执行计划。
-
Domain Transfer
BASE首先从数据丰富的source域学习(cost),然后将从source域学习到的知识转移到数据稀缺的目标域(latency),从而极大地提高了学习查询优化器的训练效率和稳定性。我们推迟了域转移问题的表述到5.1节中。
2.2 Plan Enumeration in Markov Decision Process
MDP包括五部分:状态空间S ={},操作空间A={
},转移概率分布T(
|
,
),奖励𝑟(
,
)和折扣因素𝛾,用M = (S, A, T, 𝑟, 𝛾)表示。对于查询优化问题,我们使用了与之前基于RL的工作相同的MDP公式[11,20]。
对于MDP,策略π是一个函数,它告诉agent(查询优化器)在每个状态下选择哪个是最佳操作。表示一个轨迹𝜏=〈,
,
,
, ...,
,
,
〉, agent的任务是最小化预期累积奖励E_{𝜏∼𝜋,T}[𝑅(𝜏)]= 公式(具体见下)。

因此,不同的奖励函数可能导致不同的最优策略。对于目标1,最直接的奖励函数的设计是让𝑟(,
)= 0,∀𝑡<𝑇−1和𝑟(
,
)=𝐿(
),其中𝐿(·)代表一个函数映射的输入状态
相应计划的延迟信号(即计划
代表)。这种设置在以前的方法中被广泛使用[11,21]。显然,有了这样的奖励函数,累积奖励可以通过生成最小延迟的计划来最小化。然而,模型训练非常耗时。奖励函数需要精心设计,以实现目标1。我们将在第4节详细阐述奖励函数设计。
查询优化中的观察
-
OBS-1:成本和延迟不一致,导致不同的最优策略。
作为一个例子,我们使用传统的DBMS,即PostgreSQL[19],从Join Order Benchmark (JOB)[7]工作负载执行查询。图1显示了PostgreSQL中成本估计和执行延迟之间的关系。显然,成本信号与延迟信号并不一致。成本的设计是为了反映相对延迟性能,而实际上,它可能产生长时间运行的执行计划。
在另一个例子中,我们基于两个信号训练[11]中提出的值模型:来自PostgreSQL的成本和来自BASE的校准成本。然后,我们使用这两个训练好的模型来生成JOB工作负载的执行计划,并比较它们相应的性能。如表1所示,基于成本的模型以较低的成本生成执行计划,这表明它通过成本信号学习策略。相反,我们的微调模型生成的计划成本较高,但延迟性能较低。这种矛盾反映了成本和延迟的不一致及其对强化学习策略学习的影响。

-
OBS-2:在RL中,纯粹基于延迟的训练时间消耗是灾难性的。
作为一个例子,我们比较了基于成本和延迟在JOB上训练值模型的效率,其中查询执行超时设置为90𝑠。基于延迟和基于成本的模型分别训练3小时。如表2所示,基于延迟的训练92%的时间花在查询计划执行上,并且模型只训练了226回合。相比之下,基于成本的训练96%的时间用于训练神经网络,训练了88,524回合。最后,在有限的训练时间内,基于成本的模型比基于延迟的模型表现出更健壮的性能,因为基于成本的训练涵盖了更多的候选查询执行计划。

-
OBS-3:尽管OBS-1适用,但只有一小部分查询在其相应的最优策略的行为方面表现出成本和延迟之间的巨大差距。
我们训练两个值模型,成本和延迟作为各自的反馈,直到收敛,以研究差距的影响。然后,我们允许两个值模型作为贪心的基于成本和基于延迟的策略来生成查询执行计划。因此,与基于延迟的策略生成的计划相比,基于成本的策略生成的执行计划中只有不到5%会导致长时间运行的计划。这个结果证明基于成本的策略在延迟方面接近于最优策略。因此,与巨大的状态-动作空间相比,只需校准有限数量的成本信号就可以产生与延迟相同的最优策略。
框架概述
在OBS的基础上,我们提出了一个两阶段的基于RL的框架,即BASE。从概念上讲,BASE将RL从源(成本)域传输到目标(延迟)域。RL的术语,要解决的任务是两个MDPs, 即= (S, A, T,
, 𝛾)和
= (S, A, T,
, 𝛾),
和
分别表示cost-based和latency-based奖励函数。BASE的工作流程如图2所示。
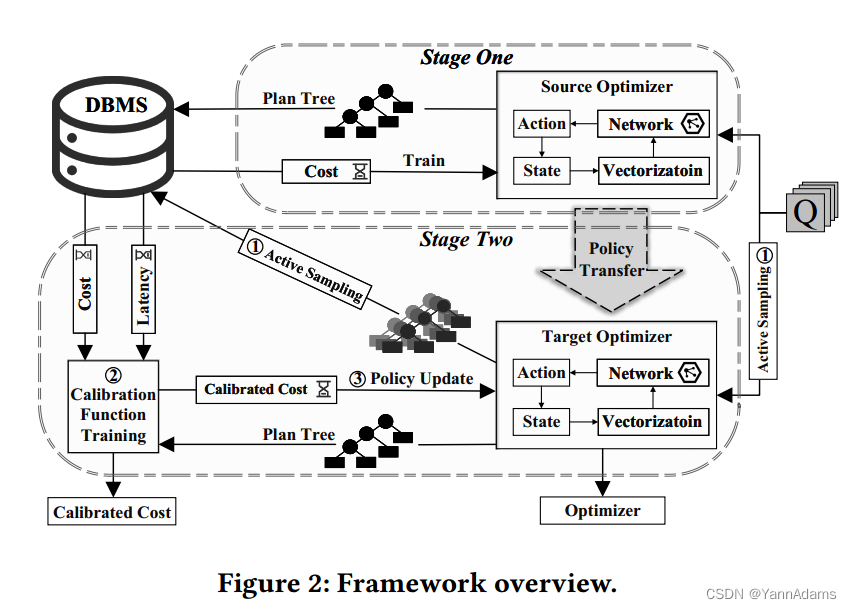
-
Stage 1
在第一阶段,BASE求解的最优策略
,我们采用奖励变换[14],将基于成本的奖励函数定义为:
=
,公式1(具体如下),其中𝑡 = 1, . . . , 𝑇 −1。

还值得注意的是,由于初始状态对应于一个空的计划,因此,C()= 0。为了求解
,我们可以学习它的最优策略,它的最优值函数,或者两者都学习,使用相应的RL算法,如现有的工作[6,11,21]。为了便于迁移,我们选择基于策略的算法来学习
的最优策略,因为它避免了明确地学习值函数
(s, a)。具体来说,我们使用一个深度策略网络来表示一个随机策略,从中我们可以对每个输入状态的动作进行采样:
(·|𝑠)。我们采用与Neo[11]相同的神经网络结构对每个输入状态进行编码。
-
Stage 2
在第二阶段,BASE从和
开始,以相互改进的方式转移到
和相应的最优策略
。最终,学习到的策略可以作为端到端查询优化器来应用,以优化延迟性能。我们在第5节中描述了第二阶段的细节。
奖励函数校准
5.1 Formulation
根据第4节的定义,和
的唯一区别在于它们的奖励函数。在BASE的第一阶段,
在式(1)中定义。
可以根据第2节进行简单定义,以鼓励最小化其生成计划的延迟的策略。然后研究了
和
产生相同最优策略的条件。
-
Lemma 1:表示最终状态的集合(例如,与完成执行计划相关联的状态),我们可以使用
从
开始遍历,
和
导致相同的最优政策,如果∀
。
在现实中,这种情况不能完美满足(见OBS-3)。在,
,但是
,有
。我们的目标是通过校准
来消除这种差异,从而使
和
相应轨迹的累积回报之间的关系与
保持一致。为此,我们建议通过将参数化的校准函数
(·)应用于成本信号C(·)并遵循Eq.(1)来表示校准后的奖励函数:
= 公式2,其中
: S→ℝ起成本模型校准的作用,为使
与
一致而需要学习。

请注意,我们的校准函数只会使校准后的成本信号和延迟信号更加相关(满足引理1),这比使预测准确更容易。这个目标与以前基于强化学习的学习查询优化器有根本的不同[11,20,21]。它们都将查询优化视为回归任务,即最小化值函数预测与实际延迟之间的均方误差。延迟预测将导致预训练模型发生巨大变化,因为成本和延迟具有不同的数值范围和基本统计信息。因此,它会导致查询优化性能的较大波动。这使得传递值函数和策略需要更多的训练样本和微调步骤。我们在6.3节和6.4节中展示了实验结果。
BASE作为IRL的一种变体,定义了和
之间定位和填充gap的过程。如图3所示,BASE保持
和
在转移开始时分别接近于
和
的状态。然后BASE利用该函数主动定位差异,更新
。并且,根据最新的
进行更新
。这些步骤交替地重复,直到
和
收敛。随着
和
之间的discrepancies逐渐消除,保证了其接近于
。

5.2 Algorithm
作为RL的转移,我们通过使用维持策略与
和
相互作用来收集经验。我们首先介绍如何整理收集到的经验。对于每个采样轨迹𝜏:
,
,…,
,
,我们保存每个三元组(
,
,
)到缓冲
。我们也计算累积奖励
(𝜏)和
(𝜏)基于该三元组和存储(𝜏,
(𝜏),
(𝜏))在缓冲
。对于任意两个收集轨迹𝜏和𝜏'∈
,如果(
(𝜏)−
(𝜏'))(
(𝜏)−
(𝜏'))< 0,即与引理1中的条件是违反,我们将轨迹对(𝜏,𝜏')作为一个discrepancy。否则,我们称(𝜏,𝜏')为一个preservation。然后我们定义
={(𝜏,𝜏',
(𝜏),
(𝜏'))|𝜏,𝜏'∈
,(𝜏,𝜏')是一个discrepancy},和其对应preservation
。为了便于讨论,我们假设对于
或
中的每个元组都是
(𝜏) <
(𝜏'),这样就避免了同时考虑(𝜏,𝜏')和(𝜏',𝜏)。
开始时,所有这些缓冲区初始化为空集合∅。采用预先训练好的策略作为初始化并进行更新,并将校准函数
初始化为任意输入状态为输出1左右,使得
(s, a) =
(s, a)。之后,BASE迭代地训练学习到的查询优化器,如图2所示。在每次迭代中,BASE包含三个步骤:①主动采样:我们首先使用我们的主动采样模块从训练工作负载和相应的执行计划中采样查询,其中采样标准基于当前策略的
。然后,我们通过执行选定的查询及其相应的执行计划来收集上述经验。②校准函数训练:然后我们根据
中收集到的经验
和
更新奖励函数
。通过最小化目标函数L来更新∅以鼓励
在保持preservation的同时消除discrepancy。③政策更新:最后,我们根据最新的奖励函数
对我们的策略
进行微调。直观地说,在每次迭代中,我们将维持的奖励函数
和策略
逼近
和
。我们在最多𝑀次迭代中重复这样的过程,其中任何收敛或提前停止规则都可以很容易地合并。
5.3 Active Sampling
在采样阶段,我们首先对训练工作负载𝑄中的查询进行采样,然后对采样的查询有价值的执行计划进行采样。我们定义了查询采样和计划采样的两个标准:informativeness和diversity。信息性有助于现行策略有效地定位discrepancy。我们用一个执行计划的轨迹𝜏来表示,定义如下信息得分:(𝜏) = 公式3,其中策略熵
表示在𝑠状态下选择一个动作的确定程度。采样查询和计划的多样性有助于稳定我们校准的奖励函数的学习动态,这将在后面解释。

-
Query Sampling
我们使用加权K-means算法[23]对查询进行抽样。具体来说,我们首先从将𝑞嵌入到潜在空间的中间层中,从而提取每个查询𝑞∈𝑄的嵌入表示。然后每个查询𝑞由其嵌入的聚类算法表示。为了保证查询的信息完备性,每个查询都是根据其由贪心生成的执行计划𝜏进行加权的。我们使用信息性得分
(𝜏)作为查询的权重。因为𝜏是由具有最大概率的
决定的,
(𝜏)为当前查询𝑞揭示了
的不确定度。为保证多样性,在将|𝑄|查询聚类为⌊𝑘% x |𝑄|⌋簇后,将选择最接近特定簇质心的每个查询。最后,⌊𝑘% x |𝑄|⌋选择的查询形成当前迭代中使用的小批处理。
-
Plan Sampling
为了保证多样性,我们使用蒙特卡罗dropout[13],将dropout层插入到中。我们的预训练策略往往是确定性的,这导致样本范围很窄,因此如果没有dropout机制,就无法有效地探索目标域。具体地说,对于每个采样查询,我们从一个drop-out层多次从
采样它的计划。dropout机制每次会随机关闭一些神经元,从而得到不同的结果。为了保证信息性,我们选择信息性得分最大的计划。
之后,我们将执行选定的查询执行计划,并获得每个相应轨迹𝜏: ,
,…,
,
,的成本和延迟反馈。因此,我们收集三元组(
,𝐶(
),𝐿(
))在
中。
存储轨迹和相应累积奖励(𝜏,
(𝜏),
(𝜏))。对于每一个新选择的轨迹𝜏,我们都会将其与现有的轨迹(即每个𝜏'∈
)进行比较。如果满足以下不等式:(
(𝜏) −
(𝜏′)) (
(𝜏) −
(𝜏′)) < 0,然后(𝜏,𝜏′)是一个discrepancy,我们把它加到
。不同查询的discrepancies使
能够从共享的部分计划中学习,这有助于其泛化。如果没有discrepancy,我们也想保持一致性,所以我们将这对值添加到
。
5.4 Calibration Function Training
在收集discrepancies和preservation之后,我们的目标是更新∅,使产生与
相同的最优策略。我们建议通过消除discrepancies来逐步调整我们的奖励函数,同时保持preservation。
对于discrepancies,我们的目标是更新𝜙,这样∀(𝜏,𝜏',(𝜏),
(𝜏'))∈
,
(𝜏)≤
(𝜏')。然而,作为一个参数化函数
(·),更新可能同时给其他状态-动作对带来“错误”的奖励值。
因此,对preservation,(·)也有期待与
保持一致。为此,我们将hinge loss定义为:
= 公式4,其中𝛿> 0是预指定的边界。在我们的实现中,我们使用
中的所有元素,并对
中最近添加的具有更高优先级的元素进行采样。

此外,随着我们策略的改进,对discrepancy的定位变得更加低效。为了进一步提高校准函数训练的样本效率,我们提出了以下命题来激励另一个目标函数。
-
Proposition 1:如果校正后的成本信号
(·)C(·)与延迟信号𝐿(·)呈线性正相关,则
与
因此,我们将另一个目标函数定义为: = 公式5,其中CorrCoef(·,·)为Pearson product-moment相关系数,用来衡量
(𝑠)𝐶(𝑠)和𝐿(𝑠)之间的线性关系。我们希望它尽可能接近于1。

我们将约束目标(Eq.(4))和线性关系目标(Eq.(5))结合起来作为最终目标L: = 公式6,其中,𝜆≥0是控制违反约束的样本惩罚的因子。我们在训练迭代过程中逐渐增加。在训练我们的校准函数时,我们通过最小化L(𝜙)来更新𝜙。

实验
6.1 Experiment Setup
-
two widely-used benchmarks:Join Order Benchmark (JOB) [7]、STACK [10]
-
Compared Methods:BASE、PG、Neo、Balsa、LO
-
Evaluation Metrics:Geometric Mean Relevant Latency (GMRL) [21]、Jumpstart Performance (JP) and Asymptotic Performance (AP)、Performance with Fixed Demonstration Amount (PA)、Transfer Ratio (TR)
为了研究将基于成本的预训练策略转移到基于延迟的更好策略的不同转移方法的效率,我们在第一阶段固定预训练的值/策略模型,并在第二阶段改变方法。我们将方法的第二阶段表示为BASE-Rfc。变体如下:
-
Direct Transfer
-
RTOS (Q-RTOS)
-
DQ (Q-DQ)
-
Classifier-Based Reward Function (P-Clf)
6.2 Overall Performance
为了展示整体性能,我们从延迟性能和训练效率两个方面对两个基准进行了端到端实验。
-
Latency Performance:为了测量延迟性能,表3显示了所有方法的GMRL。BASE优于所有其他方法
-
Training Efficiency:表4展示了学习优化器优于传统优化器PG所需的时间,即本实验中GMRL=1时。


6.3 Evaluation of Transfer Strategies
在成本训练的帮助下,学习后的优化器可以在第一阶段之后模仿传统的DBMS行为。为了检验学习优化器在第二阶段能在多大程度上超越传统的DBMS,我们将BASE-Rfc与以前的工作(第6.1节)中的五种迁移方法进行比较。为了公平的比较,在第一阶段,我们训练两种类型的学习优化器(即基于值的和基于策略的),直到收敛到在成本方面达到与PG相似的性能。然后对第一阶段模型进行迁移,使其适应延迟环境。所有方法都使用相同数量的查询执行来实现。我们在表5中显示了评估指标。

6.4 Evaluation of Design Choices
-
Calibration Function Training
为了测试BASE的可转移性,我们对在JOB工作负载上转移不同的预训练查询优化器进行了实证研究。我们将使用三个预训练的查询优化器:(i)随机初始化的查询优化器(Rand); (ii)由最小成本模型预训练的查询优化器(最小成本:来自PG的基数估计器);(iii)由专家成本模型预训练的查询优化器(专家成本:来自PG的默认成本模型)。在预训练阶段之后,我们在BASE中进行第二阶段:我们校准成本模型,并用成本模型逐步训练学习到的查询优化器。
-
图4(a)显示了不同学习到的查询优化器的训练曲线
-
图4(b)显示了不同成本模型的准确性

-
Active Sampling
为了证明计划采样在主动采样(AS)模块中的有效性,我们对主动学习方法进行了微基准测试。具体来说,我们重用在JOB上训练的优化器,然后在称为Ext-JOB的新工作负载上训练它[11]。我们使用不同的主动学习方法来选择有价值的训练查询和物理计划来收集到我们的经验缓冲区中。我们与以下方法进行比较:
-
LO:和之前的定义一样。
-
Uncertain [8]:选择不确定性得分最高的潜在训练查询和计划
-
Greedy:随机选择潜在的训练查询,然后根据当前查询优化策略贪婪地生成物理计划
-
UCB [5]:RL问题中常用的探索策略
-
RBMAL [2]:一种将不确定分数与每个样本数据到标记训练数据的加权距离相结合的SOTA主动学习方法。
-
图5(a)显示了用于训练学习的查询优化器的不同方法的训练曲线
-
图5(b)显示了在策略更新阶段的一个回合中唯一计划的平均数量
-
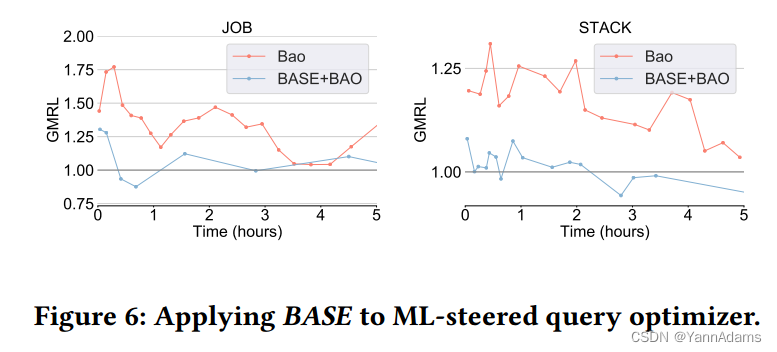
图6显示了我们在两个数据集上进行优化的训练过程

相关工作
Neo[11]构建了一个端到端查询优化器,生成完整的执行计划。
Rejoin[12]、DQ[6]、RTOS[21]等也有类似的工作,利用成本作为一种权衡来提高训练效率,然后将基于成本的预训练模型转移到能够适应延迟信号的新模型上。由于查询优化设置的源域和目标域的特征表示是相同的,DQ和RTOS利用归纳迁移学习方法[15]改变输出层的表示。
Bao[10]和QO-Advisor[22]通过调优提示集来引导传统的查询优化器。它们学习一个预测模型来估计查询优化器生成的计划的延迟。
BASE 不是从一个空的或随机填充的知识库中训练机器学习模型,而是通过将领域知识从成本转移到延迟来校准机器学习模型。
结论
在本文中,我们提出了BASE,这是一个基于两阶段强化学习的框架,它弥合了成本和延迟之间的gap,以学习具有令人满意延迟性能的端到端查询优化器。
我们在两个公共基准上进行了大量的实验,以证明BASE方法比SOTA方法具有更好的训练效率和可移植性。同时,BASE也适用于ML-steered优化器,以提高训练效率。














 2736
2736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









