









之前一篇文章主要介绍了core dump的一些基本概念以及产生的基本原因,这篇文章主要聊一下程序出core之后如何进行最基本的定位。
一、简单的直观定位
有时候不用去具体分析core文件我们就能初步定位到代码问题。例如:在程序执行到每次某一功能时,就会现core dump。例如程序每次点击跳转页面、或者重新设置参数时。(根据具体出现问题时的操作,去定位程序相应的代码模块)
二、 使用日志或者printf输出信息定位
这种方式在代码开发期间自己调试经常会使用,省事且高效。
在程序的重要代码附近加上像printf这类输出信息,这样可以跟踪并打印出段错误在代码中可能出现的位置。可以使用条件编译指令#ifdef DEBUG和#endif把printf函数包起来。这样在程序编译时,如果加上-DDEBUG参数就能查看调试信息;否则不加该参数就不会显示调试信息。
三、 使用core文件和gdb进行定位 (命令:gdb [exec file] [core file])
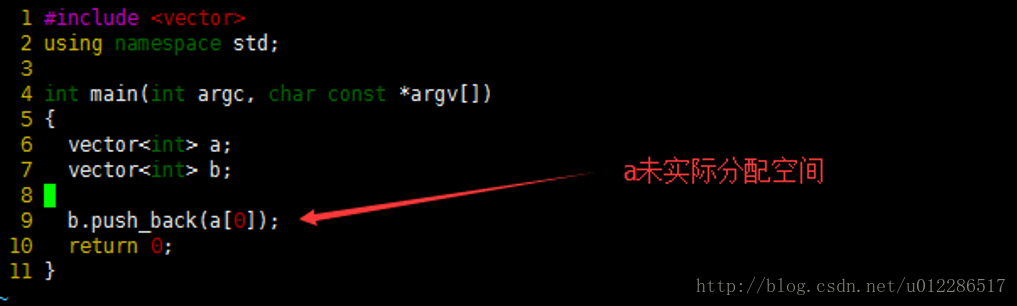
1、情形1:问题每次必现,或者复现比率非常高的case且堆栈信息未被破坏。看如下简单例子:
a.编译运行如下代码:

编译是能正常通过的,但在执行时出core:

b.使用gdb ./a.out core.a.out.22797 进行调试。使用bt查看堆栈信息,使用frame n调用具体的堆栈信息
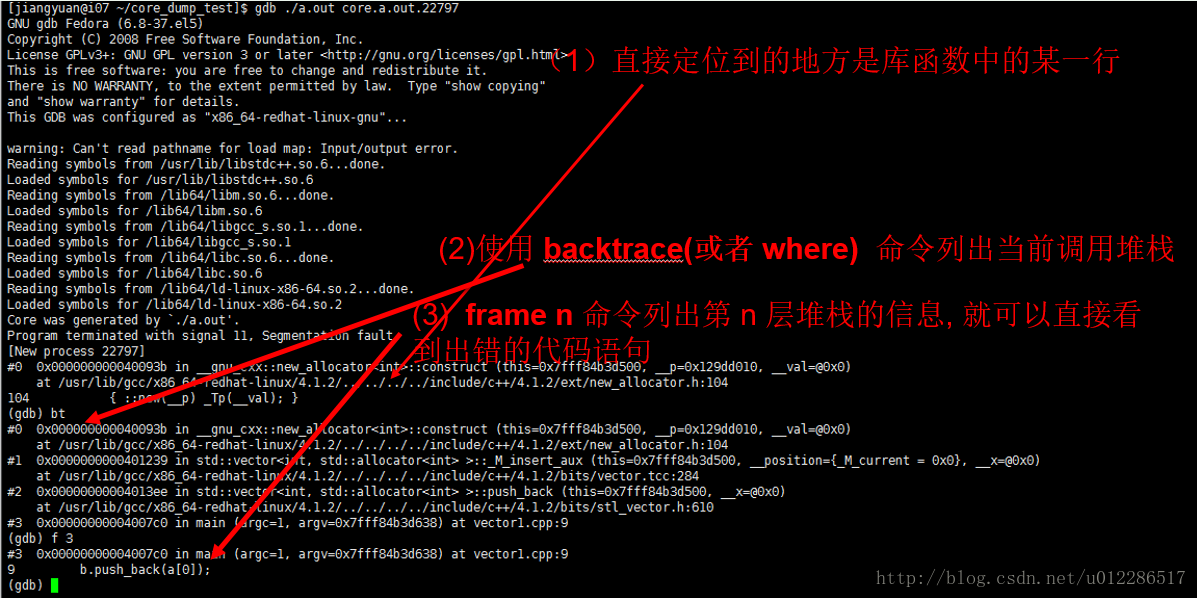
最后定位到出core代码位置在第9行,变量未分配空间。
2、情形2:问题不好复现!而且出现无符号和栈破坏情况下。
bt查看到堆栈信息被破坏。
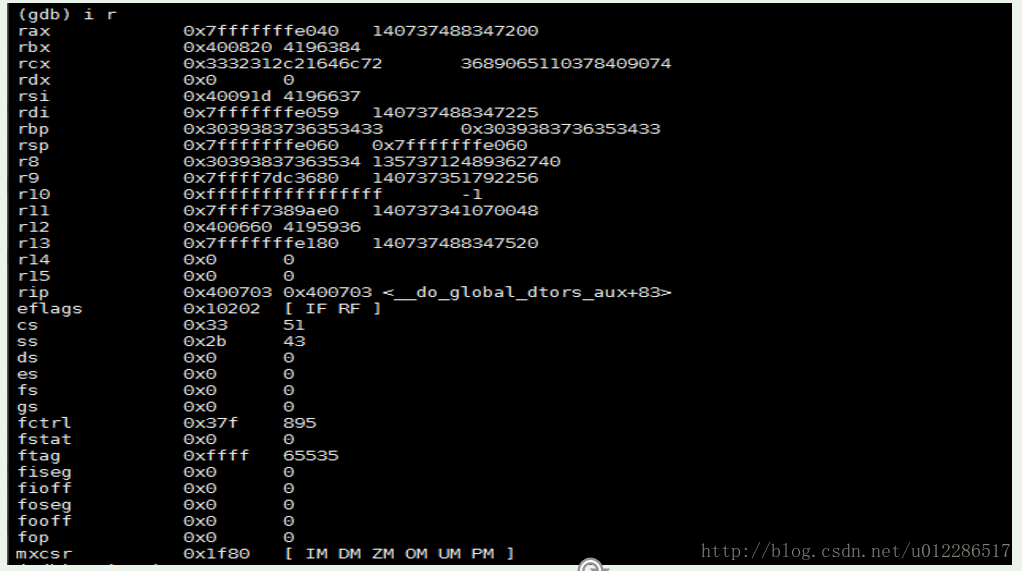
这种情况下,查看寄存器信息: rbp的值很奇怪,基本确定栈被破坏了(bt不正常,也应该看一下栈是否出问题了)。
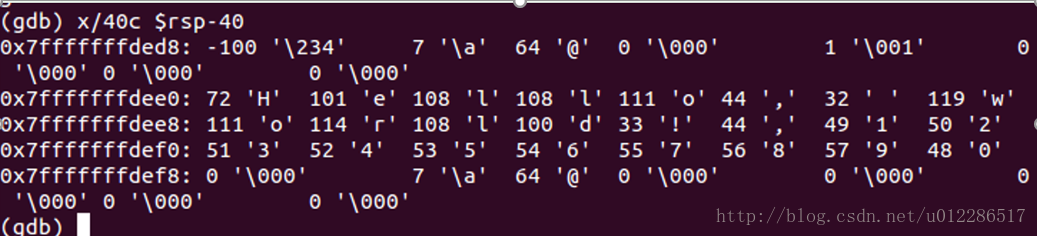
当RBP出现了问题,我们就可以通过RSP来手动获取调用堆栈。因为RSP是不会被破坏的,如下图看到了特殊的字符!,1234567890,推测可能是字符串"Hello,World!,1234567890“这个字符串溢出导致栈被破坏。
(rsp是栈指针寄存器64位,指向栈顶。相当于32位汇编里的esp,16位的sp)
四、使用辅助工具(valgrind )
Valgrind是一款用于内存调试、内存泄漏检测以及性能分析的软件开发工具在它的环境中运行你的程序来监视内存的使用情况。比如C 语言中的malloc和free或者C++中的new和 delete。使用Valgrind的工具包,你可以自动的检测许多内存管理和线程的bug,避免花费太多的时间在bug寻找上,使得你的程序更加稳固。

五、小结

二分调试就是通过某种特征(比如程序崩溃、某个变量的值/内存中的数据、是否出现某条日志、是否出现某个现象,以及任何有用的特征),加上一个能把问题可能出现的空间划分两半的一个点(一行assert、一个断点、一行打日志的代码、一个版本号、等等),二者结合就能把问题可能出现的范围缩小(比如能判断出错误代码出现在那行assert之前等之类),跟二分搜索一样。
Backtrace函数对长时间运行程序的分析,在程序出错时打印出函数的调用堆栈是非常有用的.















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









