







 本文介绍了如何使用Python Scrapy框架实现自动多网页爬取,通过爬取个人csdn博客的文章标题、阅读人数和创建时间。文章详细讲解了两种方法:1) 使用普通Spider,从第一篇文章开始,通过提取下一页链接并使用yield和Request进行递归抓取;2) 使用CrawlSpider,利用Rule定义跟进链接的规则。代码示例展示了具体实现,并展示了爬取的20篇文章的信息与博客列表的对比。
本文介绍了如何使用Python Scrapy框架实现自动多网页爬取,通过爬取个人csdn博客的文章标题、阅读人数和创建时间。文章详细讲解了两种方法:1) 使用普通Spider,从第一篇文章开始,通过提取下一页链接并使用yield和Request进行递归抓取;2) 使用CrawlSpider,利用Rule定义跟进链接的规则。代码示例展示了具体实现,并展示了爬取的20篇文章的信息与博客列表的对比。
使用scrapy框架写爬虫时一般会在start_urls中指定我们需要爬虫去抓取的网页的url,但是如何让我们的爬虫像搜索引擎中使用的爬虫一样具备自动多网页爬取的功能呢?本文通过自动抓取个人csdn博客的所有文章标题、阅读人数、创建时间来进行一个简单的说明。文中使用了两种不同的方法来实现。
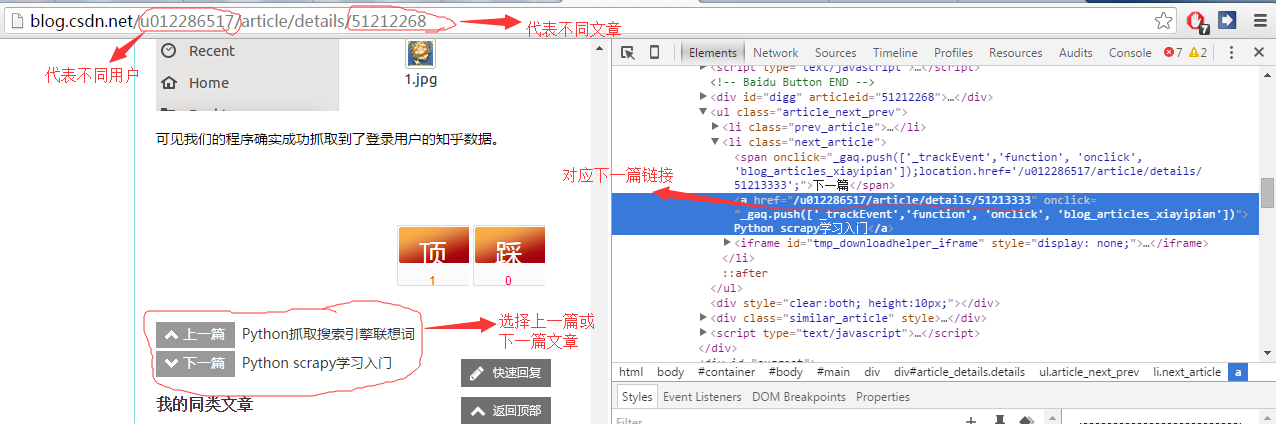
首先我们来分析cdsn中博客中文章的url,如图所示可以发现不同的文章页面的url只有url末尾对应的一串数字编号不同,而且在每篇文章的下面会有连接指向上一篇或者下一篇文章。因此我们可以提取这个链接实现网页的自动抓取。
在scrapy框架上编写爬虫整体流程和上一篇文章中的流程一样这里不再重复直接贴代码。
items.py
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title=scrapy.Field()
time=scrapy.Field()
readtimes=scrapy.Field()
article_url=scrapy.Field()
passpipelines.py
import codecs
import json
from scrapy import signals
class CsdnPipeline(object):
def __init__(self):
self.file=codecs.open('data.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item))+& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









