







Epoll 的出现
想必能搜到这篇文章的,应该对 select/poll 有一些了解和认识,一般说 epoll 都会与 select/poll 进行一些对比,select、poll 和 epoll 都是一种 IO 多路复用机制。
select 的问题
select 的问题在于描述符的限制,能监控的文件描述符最大为 FD_SETSIZE,对于连接数很多的场景就无法满足;
另外select 还有一个问题是,每次调用 select 都需要从用户空间把描述符集合拷贝到内核空间,当描述符集合变大之后,用户空间和内核空间的内存拷贝会导致效率低下;
另外每次调用 select 都需要在内核线性遍历文件描述符的集合,当描述符增多,效率低下。
poll 的问题
由于 select 存在上面的问题,于是 poll 被提了出来,它能解决 select 对文件描述符数量有限制的问题,但是依然不能解决线性遍历以及用户空间和内核空间的低效数据拷贝问题。
epoll 是什么
select/poll 在互联网早期应该是没什么问题的,因为没有很多的互联网服务,也没有很多的客户端,但是随着互联网的发展,C10K 等问题的出现,select/poll 已经不能满足要求了,这个时候 epoll 上场了。
epoll 是 linux 内核 2.6 之后支持的,epoll 同 select/poll 一样,也是 IO 多路复用的一种机制,不过它避免了 select/poll 的缺点。下面详细讲解一下 epoll 反应堆的原理。
Epoll 反应堆
epoll 原理
要完整描述 epoll 的原理,需要涉及到内核、网卡、中断、软中断、协议栈、套接字等知识,本文尽量从比较全面的角度来分析 epoll 的原理。
上面其实讨论了 select/poll 几个缺点,针对这几个缺点,就需要解决以下几件事:
- 如何突破文件描述符数量的限制
- 如何避免用户态和内核态对文件描述符集合的拷贝
- socket 就绪后,如何避免线性遍历文件描述符集合
针对第一点:如何突破文件描述符数量的限制,其实 poll 已经解决了,poll 使用的是链表的方式管理 socket 描述符,但问题是不够高效,如果有百万级别的连接需要管理,如何快速的插入和删除就变得很重要,于是 epoll 采用了红黑树的方式进行管理,这样能保证在添加 socket 和删除 socket 时,有 O(log(n)) 的复杂度。
针对第二点:如何避免用户态和内核态对文件描述符集合的拷贝,其实对于 select 来说,由于这个集合是保存在用户态的,所以当调用 select 时需要屡次的把这个描述符集合拷贝到内核空间。所以如果要解决这个问题,可以直接把这个集合放在内核空间进行管理。没错,epoll 就是这样做的,epoll 在内核空间创建了一颗红黑树,应用程序直接把需要监控的 socket 对象添加到这棵树上,直接从用户态到内核态了,而且后续也不需要再次拷贝了。
针对第三点:socket就绪后,如何避免内核线性遍历文件描述符集合,这个问题就会比较复杂,要完整理解就得涉及到内核收包到应用层的整个过程。这里先简单讲一下,与 select 不同,epoll 使用了一个双向链表来保存就绪的 socket,这样当活跃连接数不多的情况下,应用程序只需要遍历这个就绪链表就行了,而 select 没有这样一个用来存储就绪 socket 的东西,导致每次需要线性遍历所有socket,以确定是哪个或者哪几个 socket 就绪了。这里需要注意的是,这个就绪链表保存活跃链接,数量是较少的,也需要从内核空间拷贝到用户空间。
从上面 3 点可以看到 epoll 的几个特点:
- 程序在内核空间开辟一块缓存,用来管理 epoll 红黑树,高效添加和删除
- 红黑树位于内核空间,用来直接管理 socket,减少和用户态的交互
- 使用双向链表缓存就绪的 socket,数量较少
- 只需要拷贝这个双向链表到用户空间,再遍历就行,注意这里也需要拷贝,没有共享内存
比较精炼的话可能反而理解起来不容易,那么接下来深入分析一下 epoll 的原理。
epoll api
如果要深入分析 epoll 的原理,那么可能需要结合到 epoll 的 api 来进行阐述。epoll api 较少,使用起来相对比较简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <sys/epoll.h> # open an epoll file descriptor # epoll_create1 可以理解为 epoll_create 的增强版(主要支持了 close-on-exec) int epoll_create(int size); int epoll_create1(int flags); # 往 epoll instance 上添加、删除、更改一个节点(socket) int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); # wait for events on epoll instance int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); # close and clear epoll instance int close(int fd); |
epoll 涉及到的 api 其实比较简单,掌握了这几个 api 其实就已经能够快速编写基于 epoll 的 tcp/udp socket 程序。可以参考:
https://github.com/smaugx/epoll_examples.git
接下来结合上面的几个 api 来详细分析以下背后的原理。
红黑树的创建和操作
前面提到,epoll 是一种 IO 多路复用机制,应用程序可以同时监控多个 socket,那么如何来存储和管理这些 socket 呢,epoll 使用的是一颗红黑树,可以随意的往这棵树上添加节点和删除节点(节点是一个结构体,包括 socket fd)。
我们使用:
1 | int epoll_create(int size); |
创建一个 epoll instance,实际上是创建了一个 eventpoll 实例,包含了红黑树以及一个双向链表。
可以直接查看 linux 源码:https://github.com/torvalds/linux/blob/master/fs/eventpoll.c#L181
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | /*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*/
struct eventpoll {
...
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
...
};
|
这个 eventpoll 实例是直接位于内核空间的。红黑树的叶子节点都是 epitem 结构体:
可以直接查看 linux 源码: https://github.com/torvalds/linux/blob/master/fs/eventpoll.c#L137
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | struct epitem {
...
union {
/* RB tree node links this structure to the eventpoll RB tree */
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* List header used to link this structure to the eventpoll ready list */
struct list_head rdllink;
/* The file descriptor information this item refers to */
struct epoll_filefd ffd;
/* The "container" of this item */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* wakeup_source used when EPOLLWAKEUP is set */
struct wakeup_source __rcu *ws;
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
...
};
|
关于各项的解释,注释里已经说的比较清楚了。我们关心的应该是,当往这棵红黑树上添加、删除、修改节点的时候,我们从(用户态)程序代码中能操作的是一个 fd,即一个 socket 对应的 file descriptor,所以一个 epitem 实例与一个 socket fd 一一对应。
另外还需要注意到的是 rdllink 这个变量,这个指向了上一步创建的 evnetpoll 实例中的成员变量 rdllist,也就是那个就绪链表。这里很重要,注意留意,后面会讲到。
当然,我们还需要关注的是 event 这个变量,代表了我们针对这个 socket fd 关心的事件,比如 EPOLLIN、EPOLLOUT。
通过上述的讲解应该大致明白了,当我们使用 socket() 或者 accept() 得到一个 socket fd 时,我们添加到这棵红黑树上的是一个结构体,与这个 socket fd 一一对应。
那么修改和删除呢?
也是类似的过程,使用 ffd 变量作为红黑树比较的 key,能够快速的查找和插入。具体我们使用的是:
1 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); |
如何触发事件
上面过程已经把我们关心的 socket 添加到 epoll instance 中了,那么当某个 socket 有事件触发时,epoll 是如何感知并通知(用户态)应用程序呢?
要完整的回答这个问题,会涉及到比较多的知识。不过为了了解 epoll 的原理,有一些知识需要提前了解。
内核收包路径
当一个包从网卡进来之后,是如何走到应用程序的呢?中间经过了哪些步骤呢?(本文会讲的比较简略一点)
包从硬件网卡(NIC) 上进来之后,会触发一个中断,告诉 cpu 网卡上有包过来了,需要处理,同时通过 DMA(direct memory access) 的方式把包存放到内存的某个地方,这块内存通常称为 ring buffer,是网卡驱动程序初始化时候分配的。
中断 的原理学过微机原理的应该都知道,表示处理器接收到来自硬件或者软件的信号,提示产生了某件事情,需要处理。
当 cpu 收到这个中断后,会调用中断处理程序,这里的中断处理程序就是网卡驱动程序,因为网络硬件设备网卡需要驱动才能工作。网卡驱动会先关闭网卡上的中断请求,表示已经知晓网卡上有包进来的事情,同时也避免在处理过程中网卡再次触发中断,干扰或者降低处理性能。驱动程序启动软中断,继续处理数据包。
然后 CPU 激活 NAPI 子系统,由 NAPI 子系统来处理由网卡放到内存的数据包。经过一些列内核代码,最终数据包来到内核协议栈。内核协议栈也就是 IP 层以及传输层。经过 IP 层之后,数据包到达传输层,内核根据数据包里面的 {src_ip:src_port, dst_ip:dst_port} 找到相应的 socket。
为了性能,内核应该是有一个四元组和 socket 句柄的一一映射关系。(这里不太确定,不过原理应该是类似的)
然后把数据包放到这个 socket 的接收队列(接收缓冲区)中,准备通知应用程序,socket 就绪。
从 socket 到应用程序
上面比较简略的描述了一个数据包从网卡到内核协议栈,再到 socket 的接收缓冲区的步骤,描述的比较简略,不影响对 epoll 原理的理解,这里只需要有这个概念就行。
那么当 socket 就绪后,也就是数据包被放到 socket 的接收缓冲区后,如何通知应用程序呢?这里用到的是等待队列,也就是 wait queue。关于 wait queue 的应用,在 linux 内核代码里有很多,具体可以看一下 wait queue 的定义:
https://github.com/torvalds/linux/blob/master/include/linux/wait.h
当我们通过 socket() 以及 accept() 获取到一个 socket 对象时,这个 socket 对象到底有哪些东西呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | /**
* struct socket - general BSD socket
* @state: socket state (%SS_CONNECTED, etc)
* @type: socket type (%SOCK_STREAM, etc)
* @flags: socket flags (%SOCK_NOSPACE, etc)
* @ops: protocol specific socket operations
* @file: File back pointer for gc
* @sk: internal networking protocol agnostic socket representation
* @wq: wait queue for several uses
*/
struct socket {
socket_state state;
short type;
unsigned long flags;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
struct socket_wq wq;
};
struct socket_wq {
/* Note: wait MUST be first field of socket_wq */
wait_queue_head_t wait;
struct fasync_struct *fasync_list;
unsigned long flags; /* %SOCKWQ_ASYNC_NOSPACE, etc */
struct rcu_head rcu;
} ____cacheline_aligned_in_smp;
|
可以看到,一个 socket 实例包含了一个 file 的指针,以及一个 socket_wq 变量。其中 socket_wq 中的 wait 表示等待队列,fasync_list 表示异步等待队列。
那么等待队列和异步等待队列中有什么呢?大致来说,等待队列和异步等待队列中存放的是关注这个 socket 上的事件的进程。区别是等待队列中的进程会处于阻塞状态,处于异步等待队列中的进程不会阻塞。
阻塞的概念学过操作系统的应该知道,阻塞是进程的一种状态,表示一个进程正在等待某件事情的发生而暂时停止运行;另外还有运行状态以及就绪状态。
当 socket 就绪后(接收缓冲区有数据),那么就会 wake up 等待队列中的进程,通知进程 socket 上有事件,可以开始处理了。
至此,一个数据包从网卡最终达到应用程序内部了。
再简单总结一下收包以及触发的过程:
- 包从网卡进来
- 一路经过各个子系统到达内核协议栈(传输层)
- 内核根据包的
{src_ip:src_port, dst_ip:dst_port}找到 socket 对象(内核维护了一份四元组和 socket 对象的一一映射表) - 数据包被放到 socket 对象的接收缓冲区
- 内核唤醒 socket 对象上的等待队列中的进程,通知 socket 事件
- 进程唤醒,处理 socket 事件(read/write)
epoll 的触发
上面其实是对内核收包以及事件触发的综合描述,涉及到 epoll 后,稍微有点差异。
上面其实提到了等待队列,每当我们创建一个 socket 后(无论是 socket()函数 还是 accept() 函数),socket 对象中会有一个进程的等待队列,表示某个或者某些进程在等待这个 socket 上的事件。
但是当我们往 epoll 红黑树上添加一个 epitem 节点(也就是一个 socket 对象,或者说一个 fd)后,实际上还会在这个 socket 对象的 wait queue 上注册一个 callback function,当这个 socket 上有事件发生后就会调用这个 callback function。这里与上面讲到的不太一样,并不会直接 wake up 一个等待进程,需要注意一下。
简单讲就是,这个 socket 在添加到这棵 epoll 树上时,会在这个 socket 的 wait queue 里注册一个回调函数,当有事件发生的时候再调用这个回调函数(而不是唤醒进程)。
下面简单贴一下 epoll 中关于注册这个回调函数的部分代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | /*
* This is the callback that is used to add our wait queue to the
* target file wakeup lists.
*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback); // 注册回调函数到等待队列上
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
|
那么这个回调函数做了什么事呢?
很简单,这个回调函数会把这个 socket 添加到创建 epoll instance 时对应的 eventpoll 实例中的就绪链表上,也就是 rdllist 上,并唤醒 epoll_wait,通知 epoll 有 socket 就绪,并且已经放到了就绪链表中,然后应用层就会来遍历这个就绪链表,并拷贝到用户空间,开始后续的事件处理(read/write)。
所以这里其实就体现出与 select 的不同, epoll 把就绪的 socket 给缓存了下来,放到一个双向链表中,这样当唤醒进程后,进程就知道哪些 socket 就绪了,而 select 是进程被唤醒后只知道有 socket 就绪,但是不知道哪些 socket 就绪,所以 select 需要遍历所有的 socket。
另外,应用程序遍历这个就绪链表,由于就绪链表是位于内核空间,所以需要拷贝到用户空间,这里要注意一下,网上很多不靠谱的文章说用了共享内存,其实不是。由于这个就绪链表的数量是相对较少的,所以由内核拷贝这个就绪链表到用户空间,这个效率是较高的。
我来来直接看一下 epoll_wait 做了什么事?epoll_wait 最终会调用到 ep_send_events_proc 这个函数,从函数名字也知道,这个函数是用来把就绪链表中的内容复制到用户空间,向应用程序通知事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 | static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
struct ep_send_events_data *esed = priv;
__poll_t revents;
struct epitem *epi, *tmp;
struct epoll_event __user *uevent = esed->events; # 这个就是在用户空间分配的一段内存指针,该函数会把 rdllist 拷贝到这块内存
struct wakeup_source *ws;
poll_table pt;
init_poll_funcptr(&pt, NULL);
esed->res = 0;
/*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop because ep_scan_ready_list() is
* holding "mtx" during this call.
*/
lockdep_assert_held(&ep->mtx);
list_for_each_entry_safe(epi, tmp, head, rdllink) {
if (esed->res >= esed->maxevents)
break;
/*
* Activate ep->ws before deactivating epi->ws to prevent
* triggering auto-suspend here (in case we reactive epi->ws
* below).
*
* This could be rearranged to delay the deactivation of epi->ws
* instead, but then epi->ws would temporarily be out of sync
* with ep_is_linked().
*/
ws = ep_wakeup_source(epi);
if (ws) {
if (ws->active)
__pm_stay_awake(ep->ws);
__pm_relax(ws);
}
list_del_init(&epi->rdllink);
/*
* If the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, ep_scan_ready_list()
* is holding ep->mtx, so no operations coming from userspace
* can change the item.
*/
revents = ep_item_poll(epi, &pt, 1);
if (!revents)
continue;
# 拷贝 rdllist 到 用户空间提供的一个内存指针
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
list_add(&epi->rdllink, head);
ep_pm_stay_awake(epi);
if (!esed->res)
esed->res = -EFAULT;
return 0;
}
esed->res++;
uevent++;
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, no one can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
return 0;
}
|
上面可以看到,这里确确实实是从内核复制 rdllist 到用户空间,非共享内存。应用程序调用 epoll_wait 返回后,开始遍历拷贝回来的内容,处理 socket 事件。
至此,从注册一个 file descriptor(socket fd) 到 epoll 红黑树,到这个 socket 上有数据包从网卡进来,再到如何触发 epoll,再到应用程序的用户空间,由应用程序开始 read/write 事件的整个过程就理顺了。不知道大家有没有理解了?
accept 事件
accept 事件属于可读事件的一种,这里单独提出来讲一下,是因为编程的时候针对 accept 有一些点需要注意,这里先大致讲一下,后面会有另外的博文展开讲。
当 socket 有可读事件达到后,epoll_wait 获取到就绪的 socket,应用程序开始处理可读事件,如果这个 socket 的 fd 等于 listen() 的 fd,说明有新连接到达,(server)开始调用 accept() 处理连接。
accept() 返回的新的 socket 对象,对应与 client 的一个新的连接,应用程序需要把这个新的 socket 对象注册到 epoll 红黑树上,并且添加关心的事件(EPOLLIN/EPOLLOUT…),然后开始 epoll 循环。
另外还有一点要注意的,accept 的惊群效应。
先解释一下什么是惊群,如果一个 socket 上有多个进程在同时等待事件,当事件触发后,内核可能会唤醒多个或者所有在等待的进程,然而只会有一个进程成功获取该事件,其他进程都失败,这种情况就叫惊群,会一定程度浪费 cpu,影响性能。如果用一个例子来解释的话就是,有一个鸡群,如果往这个鸡群里丢一粒米,那么会造成所有鸡(或者大多数鸡)一起来争抢这粒米,但是最终只会有一只鸡能抢到这粒米。
对于 accept() 来说,通常我们会使用多线程或者多进程的方式来监听同一个 listen fd,此时,就很可能发生惊群效应。
关于惊群效应,此处只简单提一下概念,后面开另外的博文深入探讨下惊群效应以及解决方案。
总结
上面深入的分析了 epoll 的底层实现原理,现在回到文章开头提到的与 select/poll 对比的几个优点,是不是能理解了呢?
简单总结一下:
- epoll 在内核开辟了一块缓存,用来创建 eventpoll 对象,并返回一个 file descriptor 代表 epoll instance
- 这个 epoll instance 中创建了一颗红黑树以及一个就绪的双向链表(当然还有其他的成员)
- 红黑树用来缓存所有的 socket,支持 O(log(n)) 的插入和查找,减少后续与用户空间的交互
- socket 就绪后,会回调一个回调函数(添加到 epoll instance 上时注册到 socket 的)
- 这个回调函数会把这个 socket 放到就绪链表,并唤醒 epoll_wait
- 应用程序拷贝就绪 socket 到用户空间,开始遍历处理就绪的 socket
- 如果有新的 socket,再添加到 epoll 红黑树上,重复这个过程
到这里应该能比较透彻的理解 epoll 的原理了,接下来会继续写几篇关于 epoll 的博文(先把坑埋下):
- epoll 入门例子 tcp server/client
- epoll 惊群(todo)
- epoll 源码分析(todo)
- 内核收发包路径(todo)
Blog:
2020-09-26 于杭州
By 史矛革
一:监听端口
(1.1)开启监听端口
二:epoll技术简介
(2.1)epoll概述
(1)I/O多路复用:epoll就是一种典型的I/O多路复用技术:epoll技术的最大特点是支持高并发;
传统多路复用技术select,poll,在并发量达到1000-2000,性能就会明显下降;
epoll,kquene(freebsd)
epoll,从linux内核2.6引入的,2.6之前是没有的;
(2)epoll和kquene技术类似:单独一台计算机支撑少则数万,多则数十上百万并发连接的核心技术;
epoll技术完全没有这种性能会随着并发量提高而出现明显下降的问题。但是并发没增加一个,必定要消耗一定的内存去保存这个连接相关的数据;
并发量总还是有限制的,不可能是无限的;
(3)10万个连接同一时刻,可能只有几十上百个客户端给你发送数据,epoll只处理这几十上百个客户端;
(4)很多服务器程序用多进程,每一个进程对应一个连接;也有用多线程做的,每一个线程对应 一个连接;
epoll事件驱动机制,在单独的进程或者单独的线程里运行,收集/处理事件;没有进程/线程之间切换的消耗,高效
(5)适合高并发,融合epoll技术到项目中,作为大家将来从事服务器开发工作的立身之本;
写小demo非常简单,难度只有1-10,但是要把epoll技术融合到商业的环境中,那么难度就会骤然增加10倍;
(2.2)学习epoll要达到的效果及一些说明
(1)理解epoll的工作原理;面试考epoll技术的工作原理;
(2)开始写代码
(3)认可nginx epoll部分源码;并且能复用的尽量复用;
(4)继续贯彻用啥讲啥的原则; 少就是多;
三:epoll原理与函数介绍:三个函数,理解好久等于掌握了epoll技术的工作原理,以下内容务必认真听讲
(3.1)课件介绍
https://github.com/wangbojing
a)c1000k_test这里,测试百万并发的一些测试程序;一般以main();
b)ntytcp:nty_epoll_inner.h,nty_epoll_rb.c
epoll_create();
epoll_ctl();
epoll_wait();
epoll_event_callback();
c)总结:建议学习完老师的epoll实战代码之后,再来学习 这里提到的课件代码,事半功倍;
(3.2)epoll_create()函数
格式:int epoll_create(int size);
功能:创建一个epoll对象,返回该对象的描述符【文件描述符】,这个描述符就代表这个epoll对象,后续会用到;
这个epoll对象最终要用close(),因为文件描述符/句柄 总是关闭的;
size: >0;
原理:
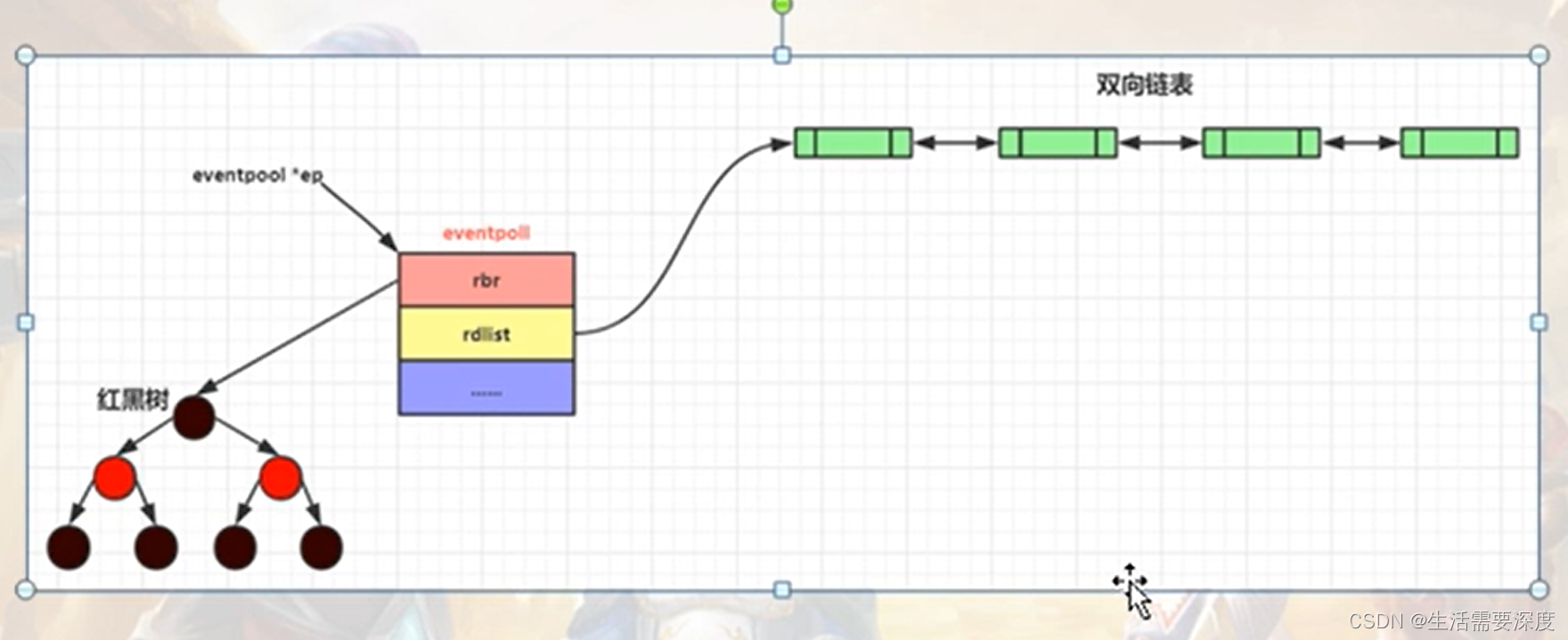
a)struct eventpoll *ep = (struct eventpoll*)calloc(1, sizeof(struct eventpoll));
b)rbr结构成员:代表一颗红黑树的根节点[刚开始指向空],把rbr理解成红黑树的根节点的指针;
红黑树,用来保存 键【数字】/值【结构】,能够快速的通过你给key,把整个的键/值取出来;
c)rdlist结构成员:代表 一个双向链表的表头指针;
双向链表:从头访问/遍历每个元素特别快;next。
d)总结:创建了一个eventpoll结构对象,被系统保存起来;
rbr成员被初始化成指向一颗红黑树的根【有了一个红黑树】;
rdlist成员被初始化成指向一个双向链表的根【有了双向链表】;
(3.3)epoll_ctl()函数
格式:int epoll_ctl(int efpd,int op,int sockid,struct epoll_event *event);
功能:把一个socket以及这个socket相关的事件添加到这个epoll对象描述符中去,目的就是通过这个epoll对象来监视这个socket【客户端的TCP连接】上数据的来往情况;
当有数据来往时,系统会通知我们;
我们把感兴趣的事件通过epoll_ctl()添加到系统,当这些事件来的时候,系统会通知我们;
efpd:epoll_create()返回的epoll对象描述符;
op:动作,添加/删除/修改 ,对应数字是1,2,3, EPOLL_CTL_ADD, EPOLL_CTL_DEL ,EPOLL_CTL_MOD
EPOLL_CTL_ADD添加事件:等于你往红黑树上添加一个节点,每个客户端连入服务器后,服务器都会产生 一个对应的socket,每个连接这个socket值都不重复
所以,这个socket就是红黑树中的key,把这个节点添加到红黑树上去;
EPOLL_CTL_MOD:修改事件;你 用了EPOLL_CTL_ADD把节点添加到红黑树上之后,才存在修改;
EPOLL_CTL_DEL:是从红黑树上把这个节点干掉;这会导致这个socket【这个tcp链接】上无法收到任何系统通知事件;
sockid:表示客户端连接,就是你从accept();这个是红黑树里边的key;
event:事件信息,这里包括的是 一些事件信息;EPOLL_CTL_ADD和EPOLL_CTL_MOD都要用到这个event参数里边的事件信息;
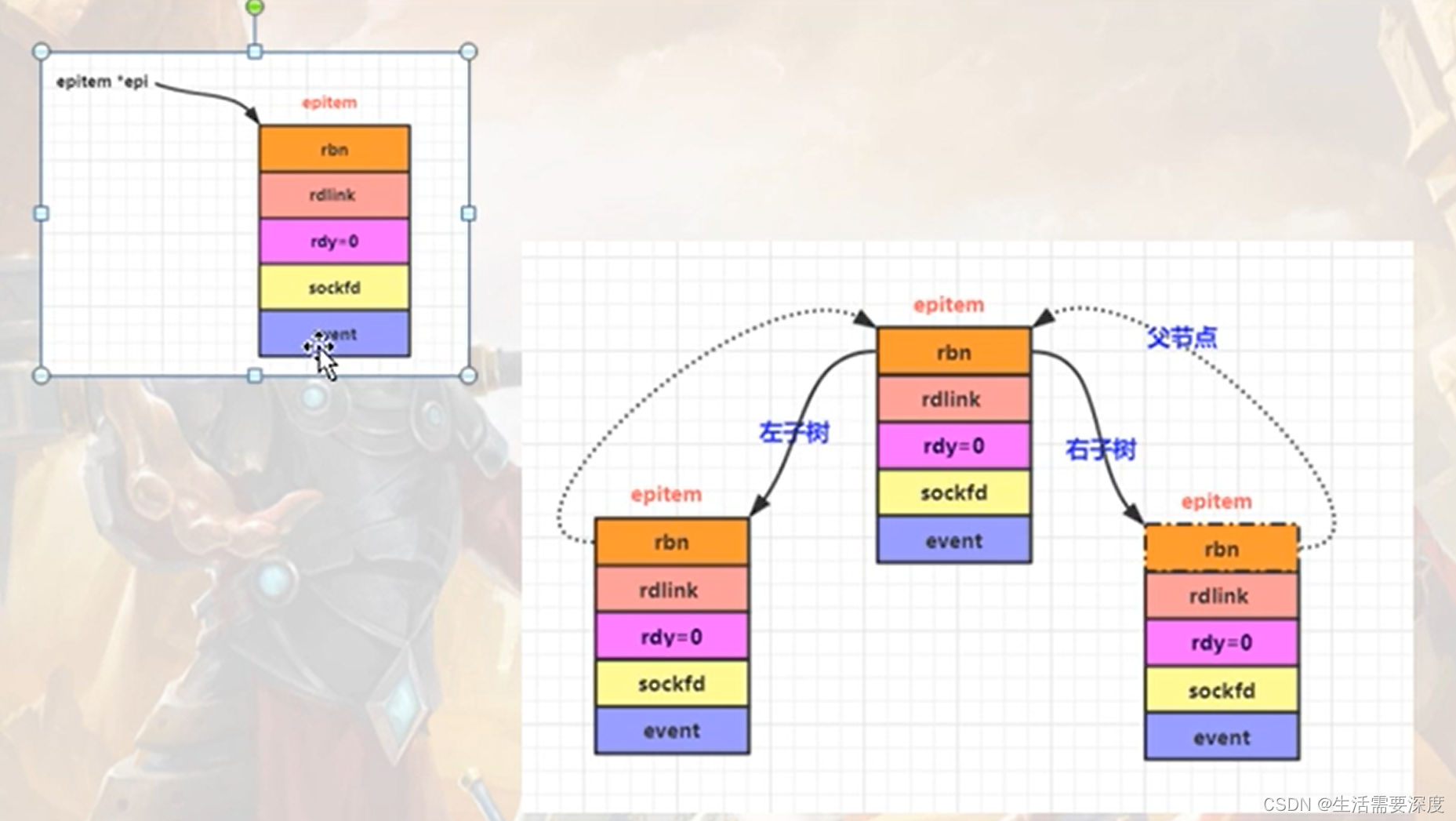
原理:
a)epi = (struct epitem*)calloc(1, sizeof(struct epitem));
b)epi = RB_INSERT(_epoll_rb_socket, &ep->rbr, epi); 【EPOLL_CTL_ADD】增加节点到红黑树中
epitem.rbn ,代表三个指针,分别指向红黑树的左子树,右子树,父亲;
epi = RB_REMOVE(_epoll_rb_socket, &ep->rbr, epi);【EPOLL_CTL_DEL】,从红黑树中把节点干掉
EPOLL_CTL_MOD,找到红黑树节点,修改这个节点中的内容;
红黑树的节点是epoll_ctl[EPOLL_CTL_ADD]往里增加的节点;面试可能考
红黑树的节点是epoll_ctl[EPOLL_CTL_DEL]删除的;
总结:
EPOLL_CTL_ADD:等价于往红黑树中增加节点
EPOLL_CTL_DEL:等价于从红黑树中删除节点
EPOLL_CTL_MOD:等价于修改已有的红黑树的节点
当事件发生,我们如何拿到操作系统的通知;
(3.4)epoll_wait()函数
格式:int epoll_wait(int epfd,struct epoll_event *events,int maxevents,int timeout);
功能:阻塞一小段时间并等待事件发生,返回事件集合,也就是获取内核的事件通知;
说白了就是遍历这个双向链表,把这个双向链表里边的节点数据拷贝出去,拷贝完毕的就从双向链表里移除;
因为双向链表里记录的是所有有数据/有事件的socket【TCP连接】;
参数epfd:是epoll_create()返回的epoll对象描述符;
参数events:是内存,也是数组,长度 是maxevents,表示此次epoll_wait调用可以手机到的maxevents个已经继续【已经准备好的】的读写事件;
说白了,就是返回的是 实际 发生事件的tcp连接数目;
参数timeout:阻塞等待的时长;
epitem结构设计的高明之处:既能够作为红黑树中的节点,又能够作为双向链表中的节点;

复杂设计的精华设计图片结果
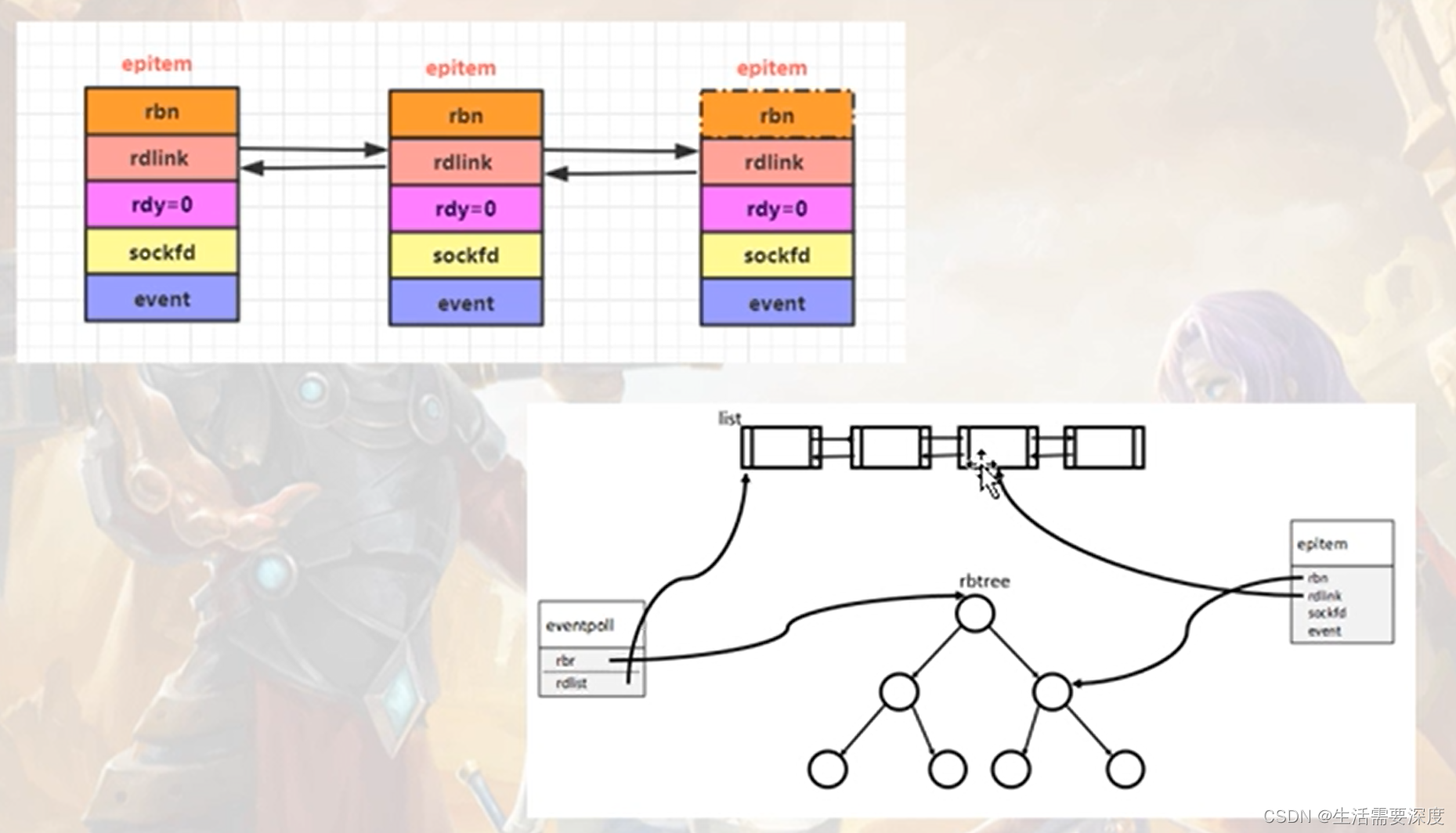
(3.5)内核向双向链表增加节点
一般有四种情况,会使操作系统把节点插入到双向链表中;
a)客户端完成三路握手;服务器要accept();
b)当客户端关闭连接,服务器也要调用close()关闭;
c)客户端发送数据来的;服务器要调用read(),recv()函数来收数据;
d)当可以发送数据时;服务武器可以调用send(),write();
e)其他情况;写实战代码再说;
(3.6)源码阅读额外说明
多线程多进程加锁进行数据保护















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









