







(1)程序控制输入输出方式。完全由CPU控制的输入输出方式,外围设备每发送或接收一个数据都要由CPU执行相应的指令才能完成;与CPU异步工作;适合于连接低速外围设备。 (2)中断输入输出方式。当出现来自系统外部,机器内部,甚至处理机本身的任何例外的,或者虽然是事先安排的,但出现在现行程序的什么地方是事先不知道的事件时,CPU暂停执行现行程序,转去处理这些事件,等处理完成后再返回来继续执行原先的程序;与CPU并行工作;数据的输入和输出都要经过CPU;一般用于连接低速外围设备。 (3)直接存储器访问方式(DMA)。外围设备与主存储器之间建立直接数据通路,传输数据不需要CPU干预;计算机系统以主存储器为中心,主存储器既可以被CPU访问,也可以被外围设备访问;在外围设备与主存储器之间传送数据不需要执行程序;主要用来连接高速外围设备
1. DMA
DMA全称Direct Memory Access,即直接存储器访问。CPU完成传输配置后,即可不在参与传输过程,由DMA控制器将数据从一个地址空间复制到另外一个地址空间。DMA详细硬件配置和基本处理流程参考文档。
CPU设置好三要素(源、目的、大小)后,由DMA控制器将内存块A的内容拷贝到内存块B中。这是普通DMA传输,那么,PCIe设备是如何完成DMA传输的呢?

PCIe设备理想的DMA传输过程如图1.2所示,主机端(主片)对PCIe设备(从片)上DMA控制器配置后,由DMA控制将主机内存块A上数据搬运自身内存块B上。这里就有两个疑问了:
- 为什么是PCIe设备(从片)上的DMA控制器?
- 为什么是主机端(主片)来配置DMA控制器?
带着两个问题往下看。实际上PCIe总线上DMA过程如图1.3所示。
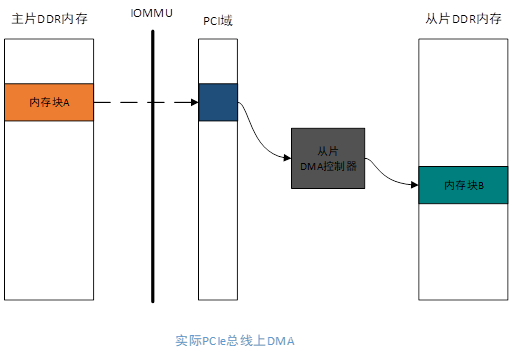
图1.3
真实的数据搬运过程需要透过IOMMU(ARM架构为SMMU)并跨越PCI域,才能到达从片内存上。
先回答第一个问题。一般情况X86平台的PCI控制器是不带DMA控制器的,普通的DMA只能完成本地总线上的数据搬运,而将本端数据搬运到从片上需要跨过PCI域,这是一般DMA控制器做不到的,所以使用从片上特殊的DMA控制器来完成这个过程。ARM平台虽然PCI控制器会带DMA控制器,但经常出现一主多从情况,所以为了提高传输效率和资源利用率,也多使用从片上的DMA。
我们知道一般X86架构在没有开启IOMMU前,主片主存储域地址与PCI域地址是平行映射的,但开启IOMMU后就没有确定的映射关系了。比如,内存块A地址为0x100,平行映射后也是0x100,但开启IOMMU后,映射后的地址可能是0x900,也可能是0x200,即没有确定的映射地址。
从片上DMA控制器想要把主片内存块A上数据搬运到从片内存块B上,就需要知道内存块A通过IOMMU映射后的地址,而这是从片无法知道的,所以一般都是由主片来配置从片DMA控制器,这便是第二个问题答案。
另外从片也可能存在IOMMU,但PCIe设备要么是作为主片,要么作为从片,只有作为主片时才会会开启IOMMU。
我们知道,DMA控制器所看到的都是物理地址,搬运的数据需要在连续的物理地址上,那么问题来了:如果内存紧张无法申请出连续的物理地址怎么办?
由这个问题引出本文第二部分——链式DMA!
2. 链式DMA
为了更好讲解链式DMA传输过程,以某个PCIe的DMA过程为例。
主片申请一块4k对齐的内存空间存放数据,一般使用posix_memalign函数。如图2.1所示,可以看见虚拟内存连续,但物理内存离散,只有物理页D、E相邻。获取这段虚拟内存对应的物理页,将它们的描述结构保存在pages数组中,同时pin住这些物理页,避免存放数据的内存被系统换页到硬盘中,导致数据搬运过程中DMA控制器读取内存不是用户所预期的。

图2.1
若虚拟页已映射物理页,则调用 find_vma_intersection、follow_pfn和 pfn_to_page 函数。若未映射,则调用 get_user_pages_fast 函数。从而获取以用户虚拟地址开始的5个虚拟页对应的物理页,将它们的描述结构保存在pages数组中。
调用sg_alloc_table_from_pages 函数,传入上面获取的pages 数组,即可得到一个sg_tabel散列表,即图2.2右侧4个条目合起来称为sg_tabel散列表。

图2.2
在填充sg_tabel散列表时,还会将相邻的物理页合并成一个条目,也就是物理页D与物理页E合并为条目DE。sg_table表对应结构体为:

图2.3
每个块物理页对应一个条目scatterlist结构,其描述结构体为:

图2.4
也就是说,现在这个sg_tabel散列表描述着这些物理页,其中dma地址是映射后的PCI域上地址,但这里还未得到。


未开启IOMMU 开启IOMMU
图2.5
调用pci_map_sg 函数完成离散映射,同时填充sg_table表中每个条目的dma地址,过程如图2.5所示,分为两种情况,在未开启IOMMU时,映射是平行映射,在开启IOMMU后,将会把离散的物理页映射成连续的PCI域空间,但并不会改变条目个数。至此sg_tabel离散映射表中即可准确描述数据内存在PCI域上地址。

图2.6
如图2.6所示(未开启IOMMU)使用sg_tabel散列表填充从片的DMA描述子(与从片约定好的),也就是图2.6中间task块,其结构如下:

图2.7
结构内部包含源地址、目标地址、大小及下一个task结构所在地址,就如同链表一样串在一块,所以称为链式DMA(需硬件支持)。
让从片的BARX窗口映射从片特定地址,然后主片通过ioremap将BARX空间映射到虚拟内存空间,最后将填充好的DMA任务描述子拷贝到BARX虚拟空间,进而通过TLP总线事务传输至从片特定DDR地址上,过程如图2.6所示。

图2.8
配置从片的DMA控制寄存器,从特定DDR地址上拿到DMA任务描述列表,即可开始数据搬运,如图2.8所示(未开启IOMMU)。注:从片上内存块依旧是连续物理内存块。
至此,链式DMA讲解结束,接下来讲解的是基于PCI域上链式DMA技术的RDMA技术。
3. RDMA
本部分只解释核心名词和概念,尽量简化不必要内容,方便理解。
3.1 RDMA技术简介
3.1.1 RDMA优劣势及应用场景
RDMA是Remote Direct Memory Access的缩写,即远程直接数据存取。使用RDMA的优势如下:
零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
既然RDMA技术这么好,为什么没能大规模普及?这就不能不说RDMA技术的劣势了,主要有两个:
网络要求苛刻:RDMA为了达到高性能低延时的目标,使得RDMA对网络有苛刻的要求,就是网络不能丢包,否则性能下降会很大,这对底层网络硬件提出更大的挑战,同时也限制了rdma的网络规模;相比而言,tcp对于网络丢包抖动的容忍度就大很多。
成本高:RDMA通过硬件实现高带宽低时延,降低了CPU的负载,但代价是需要特定的硬件,硬件成本较高。软件上,RDMA技术的应用接口是全新的,大多数现有程序都需要作移植适配及优化,有一定挑战,人工成本高。
目前,RDMA技术有三个比较好的应用方向,即存储、HPC(高性能计算)及数据中心,简要描述如下:
为存储系统和计算系统加速,充分利用高带宽低延迟以及释放CPU通信处理。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。
为GPU异构计算通信加速,充分利用Zero Copy的特性,减少数据通路中的拷贝次数,大大降低GPU之间的传输延迟。
数据中心会存在大量的分布式计算集群,但大量并行程序的通讯延迟,则会极大影响整个计算过程的效率。使RDMA网络和传统数据中心融合,将会有很好的收益。
3.1.2 RDMA协议
RDMA有三种协议,如下图所示:
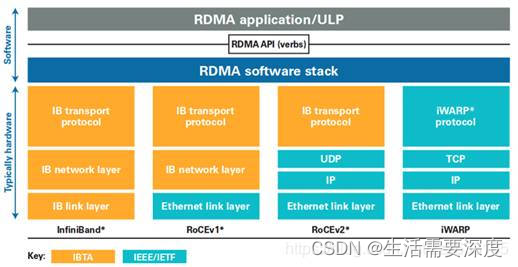
图3.0
图3.0较为直观的反映三种协议之间差异,再简单介绍一下它们。
Infiniband
2000年由IBTA(InfiniBand Trade Association)提出的IB协议是当之无愧的核心,其规定了一整套完整的链路层到传输层(非传统OSI七层模型的传输层,而是位于其之上)规范,但是其无法兼容现有以太网,除了需要支持IB的网卡之外,企业如果想部署的话还要重新购买配套的交换设备。
RoCE
RoCE从英文全称就可以看出它是基于以太网链路层的协议,v1版本网络层仍然使用了IB规范,而v2使用了UDP+IP作为网络层,使得数据包也可以被路由。RoCE可以被认为是IB的“低成本解决方案”,将IB的报文封装成以太网包进行收发。由于RoCE v2可以使用以太网的交换设备,所以现在在企业中应用也比较多,但是相同场景下相比IB性能要有一些损失。
iWARP
iWARP协议是IETF基于TCP提出的,但是因为TCP是面向连接的协议,而大量的TCP连接会耗费很多的内存资源,另外TCP复杂的流控等机制会导致性能问题,所以iWARP相比基于UDP的RoCE v2来说并没有优势(IB的传输层也可以像TCP一样保证可靠性),所以iWARP相比其他两种协议的应用不是很多。
需要注意的是,上述几种协议都需要专门的硬件(RDMA网卡)支持。后续内容以RoCEv2协议进行讲解,但由于本部分只讲解原理,并不涉及底层实现,因此差异不大。
3.1.3 RDMA原理简介
用一张图描述RDMA过程,如图3.1所示
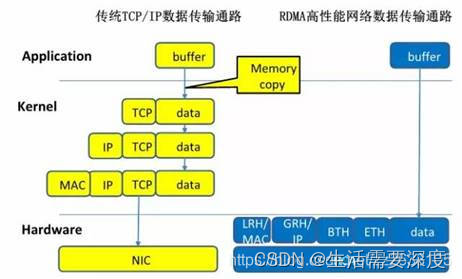
图3.1
HCA是宿主通道适配器,即RDMA网卡。相比于TCP/IP数据传输,RDMA传输可直接将本端用户态虚拟内存数据传输到对端用户态内存中,而不需要陷入内核!
这是如何实现的?通过本文前两部分讲解,我们知道带DMA引擎的PCI设备能够直接读写宿主机内存,如下图3.2所示。

图3.2
如果DMA引擎从内存块A读取的数据不是放到内存块B,而是通过某种方法传递出去会怎样?如下图3.3所示。
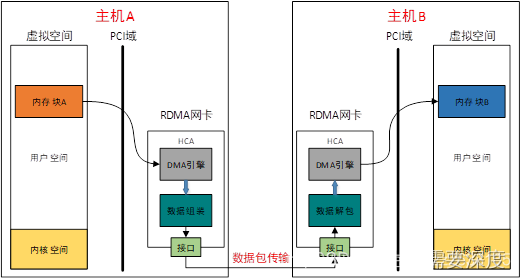
图3.3
原理:
1.HCA是带DMA引擎的PCI设备,具有读写主机DDR能力。
2.HCA是特殊网卡,除了普通网卡功能外,内部支持IB传输协议。
HCA(RDMA网卡)读取本端数据后,在内部将数据按某些格式组包,再通过硬件接口传输到对端HCA上,由对端HCA解包后写入对端内存。值得注意的是,内存块A、B都是连续的虚拟内存,对应的物理内存可不一定连续。
HCA硬件上天然支持RDMA传输,但软件上实现可不容易,先看下图。

图3.4
先简单介绍一下图3.4中模块:
libibverbs.so:rdma-core核心库
libmlx5.so:用户态驱动,也是个动态链接库,实现厂商的驱动逻辑
ib_uverbs.ko:uverbs驱动
ib_core.ko:RDMA子系统核心模块
mlx5_ib.ko:RDMA硬件驱动程序(PCI设备驱动),负责直接和硬件交互
图3.4中有两条路径,为后续描述方便,称右侧路径为准备路径,称左侧路径为工作路径。可以看到,准备路径需要陷入内核态,而工作路径将绕过内核直接操作硬件,后续的讲解将从这两部分说明。上面说到,硬件天然支持RDMA传输,而软件的工作简要概括就是,通过某种方法告诉硬件三要素——源、目的、大小。
3.2 准备阶段
准备阶段的部分工作就是获取三要素(源、目的、大小),但在此之前还需解决一个问题,在用户态下,用什么方法绕过内核,直接告诉硬件三要素?
3.2.1 获取通知方法
以X86架构为例,我们知道BOIS启动阶段会在主机上为每个PCI设备分配BAR空间,如图3.5主存储域上橘黄色块,就是RDMA网卡的BAR空间。

图3.5
RDMA设备驱动(如mlx5_ib.ko)匹配上设备后,会执行一系列初始化动作,同时保存设备BAR空间在主存储域上的地址。
用户空间进程调用mmap函数分配一块虚拟内存,同时将调用到RDMA设备驱动的mmap函数,进而将主存储域上设备BAR空间映射到所申请的虚拟内存!所以在用户空间操作bar虚拟空间,即可操作RDMA网卡的某些寄存器或内存。
在这块虚拟内存中,比较重要的是Doorbell,其实就是门铃的意思,是一种通知机制,当用户准备好工作请求之后,向Doorbell的地址中写一下数据,就等于敲了一下门铃,硬件就知道可以开始干活了。这便是用户态下的通知方法。
3.2.2 获取源
通知方法有了,现在还需获取三要素,先来说源怎么获取,需要说明一下,这个源是一个集合,不仅仅是数据源地址。
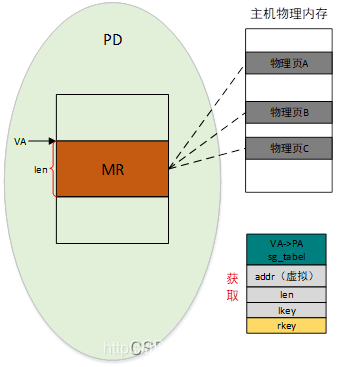
图3.6
如图3.6所示,用户申请一块长度为len的虚拟内存,执行RDMA注册函数,将会得到一个映射表,包含两部分,一个是sg_table记录着物理地址到pci域地址的转换关系,另一个是VA->PA映射表,记录着VA到PA的转换关系。VA->PA映射表很容易理解,sg_tabel获取过程和本文第二部分中描述类似,同样也会pin主内存,这里不再赘述。除此之外,还会获得lkey和rkey,一个是本端操作秘钥,另一个是本端赋予远端的操作秘钥。秘钥由两部分组成,低字节部分是真正的钥匙,高字节部分是本MR的映射表在缓存区的索引。
每注册一个MR都会生成映射表和秘钥,这一系列映射表将放一个硬件知道的缓存区中,由秘钥的高字节索引。
还有一个比较重要的东西,叫QP工作队列对,由SQ发送队列和RQ接收队列组成。QP是软件向硬件“发号施令”的媒介,由用户调用特定函数将其创建,如下图3.7所示。
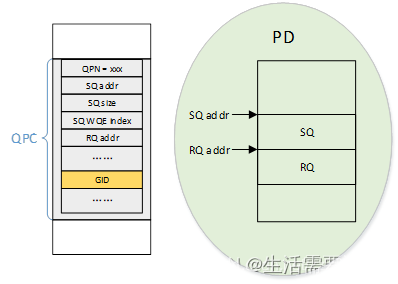
图3.7
除了创建QP外,还会创建QP的上下文QPC,即描述QP属性的一个结构,这个结构放在硬件知道的一段缓存区里,由QP号(QPN)索引,也就是说,可以有很多个QP,它们之间由QPN区分。值得注意的是,QPC中有一个GID存储区域,这个是存储对端GID的。
GID是一个全局ID,由MAC地址和IP地址转换得来,根据GID就可以找到局域中唯一宿主机。调用专用函数可以获取本端的GID序列号。
至此,源集合已准备好,有MR addr、len、lkey、QPN,再看看如何获取目的集合。
3.2.3 获取目的
本端是无法直接获得对端基本信息的,所以需要通过某些方式,让两端建立通信交换基本信息。有两种方式:TCP/IP和RDMA CM,如下图3.8所示。
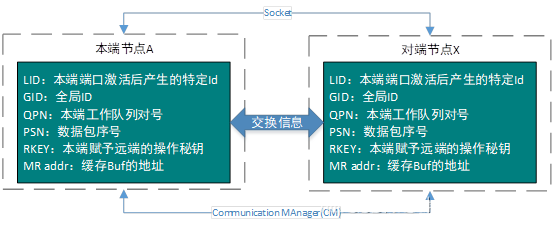
图3.8
以socket交换方式为例,双方约定号消息格式,将需要传递的信息通过socket交换就好了。图3.8中LID是本端RDMA适配器激活后分配的ID,在本端唯一,而PSN是本端发送到对端第一个数据包序号,可以随机指定。信息交换完毕后即可关闭上述连接。
至此,目的集合已经准备好,有raddr、rkey、rGID、rQPN,加r表示远端(对端)的意思。万事具备只欠东风。
3.3 工作阶段
3.3.1 下发工作请求
本端在下发工作请求前,还需要处理rQPN和rGID,这里以RC链接(类似于TCP链接)为例。本端需要将QP(节点A)与对端QP(节点x)绑定,在QPC中填入对端QPN,同时又因为是RC链接(点到点),还需在QPC中填入rGID。
现在可以填写工作请求了,这个请求结构称为WQE,即工作请求元素,主要由三部分组成,控制头,远端地址和远端秘钥,本端地址、本端秘钥、数据大小,如下图3.9所示。

图3.9
结合图3.5,将控制头拷贝到bar虚拟内存的Doorbell地址中(此处有防竞态机制),通过TLP总线事务传输到RDMA网卡内部,即敲响门铃,硬件就可以开始工作了。
硬件通过控制头信息(QPN)找到对应的QPC,从而找到SQ中的WQE,通过DMA控制器把WQE搬运到内部解析,再通过lkey找到对应的映射表,然后将laddr转换获得数据所在物理页,最终从物理页取得数据组包,如下图3.10所示。

图3.10
硬件还会在数据包中添加对端raddr和rkey,再从QPC中取得对端rGID,这样数据包才能到对端宿主机。对端接收到数据包后,根据rkey找到映射表,将raddr翻译,最后将数据写入对应离散物理页中,注意,这个过程对端的cpu是不知道的(需要本端主动通知对端),完全由RDMA网卡完成,不需要内核参与,在对端的app侧看来,就是有人往某块连续的虚拟内存写了数据。
3.3.2 write流程简介
在两方完成准备阶段并交换信息后,操作流程如下图3.11所示。

图3.11
将发送write请求的这侧称为请求端,另一侧称为响应端;
①请求端A下发write请求的WQE(src_addr、len、dst_addr、r_key),里面包含双方地址信息及秘钥;
②请求端A硬件(RDMA网卡)从SQ队列中取得WQE,获取源-目的-长度,这三要素;
③请求端A硬件(RDMA网卡)从内存src_addr地址取得长度为len的数据并组装成数据报文;
④请求端A硬件(RDMA网卡)将数据报文发送至响应端B;
⑤响应端B硬件检查秘钥无误后,根据rkey查找到映射表,将数据写至dst_addr地址对应的物理页中;
⑥响应端B硬件向请求端A硬件返回操作结果;
⑦请求端A硬件根据响应端B的反馈结果上报工作完成CQE,操作成功或失败,失败有错误码;
⑧请求端A的APP查看CQE获取工作完成情况。
其中CQ完成队列,存放的CQE是完成队列元素。
文章讲解完毕,觉得博主讲解不错就点个赞呗。
————————————————
版权声明:本文为CSDN博主「caodongwang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zz2633105/article/details/119519952
DMA与cache内存一致性
dma_alloc_coherent(),dma_map_sg()两个接口说明
DMA应该多多少少知道点吧。DMA(Direct Memory Access)是指在外接可以不用CPU干预,直接把数据传输到内存的技术。这个过程中可以把CPU解放出来,可以很好的提升系统性能。那么DMA和Cache有什么关系呢?这也需要我们关注?
需要解决什么问题
我们知道DMA可以帮我们在I/O和主存之间搬运数据,且不需要CPU参与。高速缓存是CPU和主存之间的数据交互的桥梁。而DMA如果和cache之间没有任何关系的话,可能会出现数据不一致。例如,CPU修改了部分数据依然躺在cache中(采用写回机制)。DMA需要将数据从内存搬运到设备I/O上,如果DMA获取的数据是从主存那里,那么就会得到旧的数据。导致程序的不正常运行。这里告诉我们,DMA通过总线获取数据时,应该先检查cache是否命中,如果命中的话,数据应该来自cache而不是主存。但是是否先需要检查cache呢?这取决于硬件设计。

总线监视技术
还记得《Cache组织方式》文章提到的PIPT Cache吗?它是操作系统最容易管理的Cache。PIPT Cache也很容易实现总线监视技术。什么是总线监视技术呢?其实就是为了解决以上问题提出的技术,cache控制器会监视总线上的每一条内存访问,然后检查是否命中。根据命中情况做出下一步操作。我们知道DMA操作的地址是物理地址,既然cache控制器可以监视总线操作,说明系统使用的cache必须是支持物理地址查找的。而PIPT完全符合条件。VIVT是根据虚拟地址查找cache,所以不能实现总线监视技术。VIPT可以吗?没有别名的VIPT也可以实现总线监视,但是有别名的情况的VIPT是不行的(当然硬件如果强行检查所有可能产生别名的cache line,或许也可以)。总线监视对于软件来说是透明的,软件不需要任何干涉即可避免不一致问题。但是,并不是所有的硬件都支持总线监视,同时操作系统应该兼容不同的硬件。因此在不支持总线监视的情况下,我们在软件上如何避免问题呢?
最简单的方法(nocahe)
当我们使用DMA时,首先是配置。我们需要在内存中申请一段内存当做buffer,这段内存用作需要使用DMA读取I/O设备的缓存,或者写入I/O设备的数据。为了避免cache的影响,我们可以将这段内存映射nocache,即不使用cache。映射的最小单位是4KB,因此在内存映射上至少4KB是nocahe的。这种方法简单实用,但是缺点也很明显。如果只是偶尔使用DMA,大部分都是使用数据的话,会由于nocache导致性能损失。这也是Linux系统中dma_alloc_coherent()接口的实现方法。
软件维护cache一致性
为了充分使用cache带来的好处。我们映射依然采用cache的方式。但是我们需要格外小心。根据DMA传输方向的不同,采取不同的措施。
- 如果DMA负责从I/O读取数据到内存(DMA Buffer)中,那么在DMA传输之前,可以invalid DMA Buffer地址范围的高速缓存。在DMA传输完成后,程序读取数据不会由于cache hit导致读取过时的数据。
- 如果DMA负责把内存(DMA Buffer)数据发送到I/O设备,那么在DMA传输之前,可以clean DMA Buffer地址范围的高速缓存,clean的作用是写回cache中修改的数据。在DMA传输时,不会把主存中的过时数据发送到I/O设备。
注意,在DMA传输没有完成期间CPU不要访问DMA Buffer。例如以上的第一种情况中,如果DMA传输期间CPU访问DMA Buffer,当DMA传输完成时。CPU读取的DMA Buffer由于cache hit导致取法获取最终的数据。同样,第二情况下,在DMA传输期间,如果CPU试图修改DMA Buffer,如果cache采用的是写回机制,那么最终写到I/O设备的数据依然是之前的旧数据。所以,这种使用方法编程开发人员应该格外小心。这也是Linux系统中流式DMA映射dma_map_single()接口的实现方法。
DMA Buffer对齐要求
假设我们有2个全局变量temp和buffer,buffer用作DMA缓存。初始值temp为5。temp和buffer变量毫不相关。可能buffer是当前DMA操作进程使用的变量,temp是另外一个无关进程使用的全局变量。
int temp = 5;
char buffer[64] = { 0 };假设,cacheline大小是64字节。那么temp变量和buffer位于同一个cacheline,buffer横跨两个cacheline。

假设现在想要启动DMA从外设读取数据到buffer中。我们进行如下操作:
- 按照上一节的理论,我们先invalid buffer对应的2行cacheline。
- 启动DMA传输。
- 当DMA传输到buff[3]时,程序改写temp的值为6。temp的值和buffer[0]-buffer[60]的值会被缓存到cache中,并且标记dirty bit。
- DMA传输还在继续,当传输到buff[50]的时候,其他程序可能读取数据导致temp变量所在的cacheline需要替换,由于cacheline是dirty的。所以cacheline的数据需要写回。此时,将temp数据写回,顺便也会将buffer[0]-buffer[60]的值写回。
在第4步中,就出现了问题。由于写回导致DMA传输的部分数据(buff[3]-buffer[49])被改写(改写成了没有DMA传输前的值)。这不是我们想要的结果。因此,为了避免出现这种情况。我们应该保证DMA Buffer不会跟其他数据共享cacheline。所以我们要求DMA Buffer首地址必须cacheline对齐,并且buffer的大小也cacheline对齐。这样就不会跟其他数据共享cacheline。也就不会出现这样的问题。
Linux对DMA Buffer分配的要求
Linux中,我们要求DMA Buffer不能是从栈和全局变量分配。这个主要原因是没办法保证buffer是cacheline对齐。我们可以通过kmalloc分配DMA Buffer。这就要求某些不支持总线监视的架构必须保证kmalloc分配的内存必须是cacheline对齐。所以linux提供了一个宏,保证kmalloc分配的object最小的size。例如ARM64平台的定义如下:
#define ARCH_DMA_MINALIGN (128)
ARM64使用的cacheline大小一般是64或者128字节。为了保证分配的内存是cacheline对齐,取了最大值128。而x86_64平台则没有定义,因为x86_64硬件保证了DMA一致性。所以我们看到x86_64平台,slub管理的kmem cache最小的是kmalloc-8。而ARM64平台,slub管理的kmem cache最小的是kmalloc-128。其实ARM64平台分配小内存的代价挺高的。即使申请8字节内存,也给你分配128字节的object,确实有点浪费。
1. 出现内存不一致的原因
CPU写内存的时候有两种方式:
- write through: CPU直接写内存,不经过cache。
- write back: CPU只写到cache中。cache的硬件使用LRU算法将cache里面的内容替换到内存。通常是这种方式。
DMA可以完成从内存到外设直接进行数据搬移。但DMA不能访问CPU的cache,CPU在读内存的时候,如果cache命中则只是在cache去读,而不是从内存读,写内存的时候,也可能实际上没有写到内存,而只是直接写到了cache。
这样一来,如果DMA从将数据从外设写到内存,CPU中cache中的数据(如果有的话)就是旧数据了,这时CPU在读内存的时候命中cache了,就是读到了旧数据;CPU写数据到内存时,如果只是先写到了cache,则内存里的数据就是旧数据了。这两种情况(两个方向)都存在cache一致性问题。例如,网卡发包的时候,CPU将数据写到cache,而网卡的DMA从内存里去读数据,就发送了错误的数据。
1. 之前谈到内存空间的时候,我们知道内存空间包括 内存 和 寄存器空间。
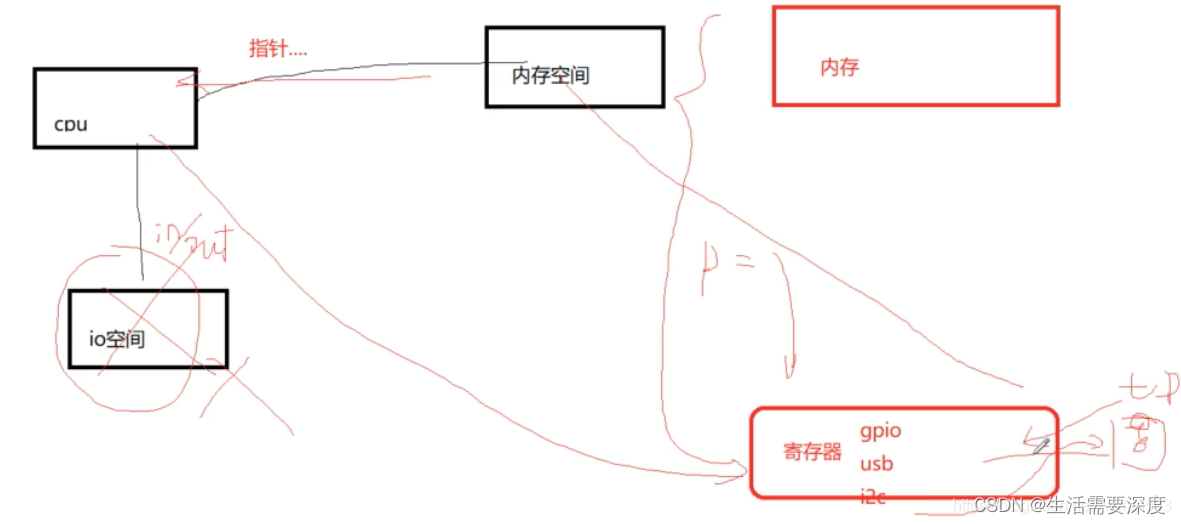
2、CPU 、cache、内存、外设 之间的关系。以及 cache 一致性 是如何导致的
CPU写内存的时候有两种方式:
1. write through: CPU直接写内存,不经过cache。
2. write back: CPU只写到cache中。cache的硬件使用LRU算法将cache里面的内容替换到内存。通常是这种方式。
我们假设MEM里面有一块红色的区域,并且CPU读过它,于是红色区域也进CACHE: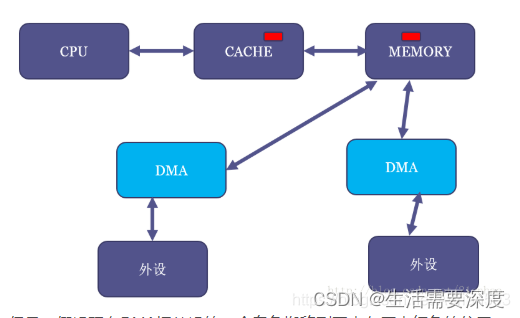
但是,假设现在DMA把外设的一个白色搬移到了内存原本红色的位置:
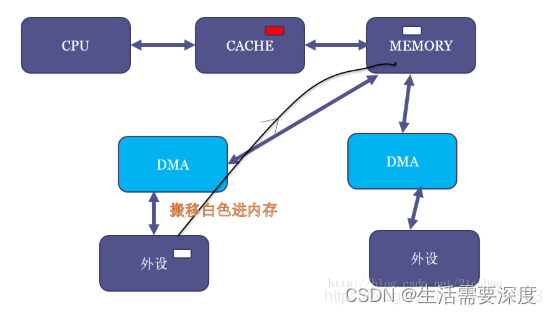
这个时候,内存虽然白了,CPU读到的却还是红色,因为CACHE命中了,这就出现了cache的不coherent。
当然,如果是CPU写数据到内存,它也只是先写进cache(不一定进了内存),这个时候如果做一个内存到外设的DMA操作,外设可能就得到错误的内存里面的老数据。
所以cache coherent的最简单方法,自然是让CPU访问DMA buffer的时候也不带cache。事实上,缺省情况下,dma_alloc_coherent()申请的内存缺省是进行uncache配置的。
但是,由于现代SoC特别强,这样有一些SoC里面可以用硬件做CPU和外设的cache coherence,如图中的cache coherent interconnect:
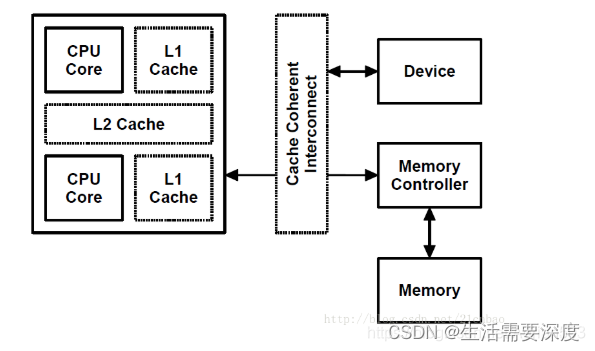
这些SoC的厂商就可以把内核的通用实现overwrite掉,变成dma_alloc_coherent()申请的内存也是可以带cache的。这部分还是让大牛Arnd Bergmann童鞋来解释:
来自:https://www.spinics.net/lists/arm-kernel/msg322447.html
Arnd Bergmann:
dma_alloc_coherent() is a wrapper around a device-specific allocator,
based on the dma_map_ops implementation. The default allocator
from arm_dma_ops gives you uncached, buffered memory. It is expected
that the driver uses a barrier (which is implied by readl/writel
but not __raw_readl/__raw_writel or readl_relaxed/writel_relaxed)
to ensure the write buffers are flushed.
If the machine sets arm_coherent_dma_ops rather than arm_dma_ops,
the memory will be cacheable, as it's assumed that the hardware
is set up for cache-coherent DMAs.
当我grep内核源代码的时候,我发现部分SoC确实是这样实现的:
所以 dma_alloc_coherent()申请的内存 也是可以带cache的,这个要看硬件的,看厂商的,不过一般默认是不带cache的。
2 如何解决一致性问题
所以要解决 cache的不一致性 一般有三种方法。
1、一种是硬件方案,例如上面介绍的在SoC中集成了叫做“Cache Coherent interconnect”的硬件,它可以做到让DMA踏到CPU的cache或者帮忙做cache的刷新。这样的话,dma_alloc_coherent()申请的内存就没必要是非cache的了。
2、一种是软件上禁用 cache (kernel 机制 ------ 一致性映射)
3、一种是 DMA Streaming Mapping (kernel 机制 ------ 流式映射)
下面主要介绍一下后面两种情况~
工程中一般有两种情况,会导致 cache的不一致性,不过kernel都有对应的机制。
(1)操作寄存器地址空间。
寄存器是CPU与外设交流的接口,有些状态寄存器是由外设根据自身状态进行改变,这个操作对CPU是不透明的。有可能这次CPU读入该状态寄存器,下次再读时,该状态寄存器已经变了,但是CPU还是读取的cache中缓存的值。但是寄存器操作在kernel中是必须保证一致的,这是kernel控制外设的基础,IO空间通过ioremap进行映射到内核空间。ioremap在映射寄存器地址时页表是配置为uncached的。数据不走cache,直接由地址空间中读取。保证了数据一致性。
这种情况kernel已经保证了data的一致性,应用场景简单。
(2)DMA申请的内存空间。
DMA操作对于CPU来说也是不透明的,DMA导致内存中数据更新,对于CPU来说是完全不可见的。反之亦然,CPU写入数据到DMA缓冲区,其实是写到了cache,这时启动DMA,操作DDR中的数据并不是CPU真正想要操作的。
这种情况是,CPU 和DMA 都可以异步的对mem 进行操作,导致data不一致性。
对于cpu 和 dma 都能访问的mem ,kernel有专业的管理方式,分为两种:
1. 给DMA申请的内存,禁用 cache ,当然这个是最简单的,不过性能方面是有影响的。
2. 使用过程中,通过flush cache / invalid cache 来保证data 一致性。
通用DMA层主要分为2种类型的DMA映射:
(1)一致性映射,代表函数:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle);
一般驱动使用多,申请一片uncache mem ,这样无需考虑data 一致性。代码流程:对page property,也就是是kernel页管理的页面属性设置成uncache,在缺页异常填TLB时,该属性就会写到TLB的存储属性域中。保证了dma_alloc_coherent映射的地址空间是uncached的。
dma_alloc_coherent首先对分配到的缓冲区进行cache刷新,之后将该缓冲区的页表修改为uncached,以此来保证之后DMA与CPU操作该块数据的一致性。
对于通常的硬件平台(不带硬件cache 一致性的组件),dma_alloc_coherent 内存操作,CPU 直接操作内存,没有cache 参与。
但是也有例外,有的CPU 很强,dma_alloc_coherent 也是可以申请到 带 cache的内存的。
2.流式DMA映射(DMA Streaming Mapping),
实际工程中,我们自己写的驱动,当然可以使用 dma_alloc_coherent 申请一致性的内存,但是实际工程中,我们并不能使用dma_alloc_coherent, 我们很难控制内存是自己申请的,举个例子:
dma_addr_t dma_map_single(struct device *dev, void *cpu_addr, size_t size, enum dma_data_direction dir)
void dma_unmap_single(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir)
void dma_sync_single_for_cpu(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir)
void dma_sync_single_for_device(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir)
int dma_map_sg(struct device *, struct scatterlist *, int, enum dma_data_direction);
void dma_unmap_sg(struct device *, struct scatterlist *, int, enum dma_data_direction);
相关接口为 dma_map_sg(), dma_unmap_sg(),dma_map_single(),dma_unmap_single()。
一致性缓存的方式是内核专门申请好一块内存给DMA用。而有时驱动并没这样做,而是让DMA引擎直接在上层传下来的内存里做事情。
例如从协议栈里发下来的一个包,想通过网卡发送出去。
但是协议栈并不知道这个包要往哪里走,因此分配内存的时候并没有特殊对待,这个包所在的内存通常都是可以cache的。传过来的socket的 buffer 并不是你申请的,而且不是 dma_alloc_coherent 申请的一致性内存,这个时候你要把 buffer的内容发出去,或者把收到的报文扔到这个 buffer里面去,那这个时候怎么办呢?
这时,内存在给DMA使用之前,就要调用一次dma_map_sg()或dma_map_single(),取决于你的DMA引擎是否支持聚集散列(DMA scatter-gather),支持就用dma_map_sg(),不支持就用dma_map_single()。DMA用完之后要调用对应的unmap接口。
由于协议栈下来的包的数据有可能还在cache里面,调用dma_map_single()后,CPU就会做一次cache的flush,将cache的数据刷到内存,这样DMA去读内存就读到新的数据了。
dma_map_single (做一遍cache的flush ,将cache的内容flush到内存)
dma 发报文 (由于做过flush ,发的就是正确的包)
dma_unmap_single
dma_map_single (做一遍cache的invalid,将cache的内容无效,重新读取内存)
dma 发报文 (由于做过invalid ,收到的就是正确的包)
dma_unmap_single
dma_map_single 是有一个方向的参数的,来决定是invalid 还是 flush
注意,在map的时候要指定一个参数,来指明数据的方向是从外设到内存还是从内存到外设:
从内存到外设:CPU会做cache的flush操作,将cache中新的数据刷到内存。
从外设到内存:CPU将cache置无效 invalidate,这样CPU读的时候不命中,就会从内存去读新的数据。
(CPU读取cache 都是自动硬件完成的,软件不能干预,但是可以控制cache,可以invalid 可以 flush)
还要注意,这几个接口都是一次性的,每次操作数据都要调用一次map和unmap。并且在map期间,CPU不能去操作这段内存,因此如果CPU去写,就又不一致了。
同样的,dma_map_sg()和dma_map_single()的后端实现也都是和硬件特性相关。
其他方式
上面说的是常规DMA,有些SoC可以用硬件做CPU和外设的cache coherence,例如在SoC中集成了叫做“Cache Coherent interconnect”的硬件,它可以做到让DMA踏到CPU的cache或者帮忙做cache的刷新。这样的话,dma_alloc_coherent()申请的内存就没必要是非cache的了。
主要靠两类APIs:
2.1 一致性DMA缓存(Coherent DMA buffers)
DMA需要的内存由内核去申请,内核可能需要对这段内存重新做一遍映射,特点是映射的时候标记这些页是不带cache的,这个特性也是存放在页表里面的。
上面说“可能”需要重新做映射,如果内核在highmem映射区申请内存并将这个地址通过vmap映射到vmalloc区域,则需要修改相应页表项并将页面设置为非cache的,而如果内核从lowmem申请内存,我们知道这部分是已经线性映射好了,因此不需要修改页表,只需修改相应页表项为非cache即可。
相关的接口就是dma_alloc_coherent()和dma_free_coherent()。dma_alloc_coherent()会传一个device结构体指明给哪个设备申请一致性DMA内存,它会产生两个地址,一个是给CPU看的,一个是给DMA看的。CPU需要通过返回的虚拟地址来访问这段内存,才是非cache的。至于dma_alloc_coherent()的内部实现可以不关注,它是和体系结构如何实现非cache(如mips的kseg1)相关,也可能与硬件特性(如是否支持CMA)相关。
还有一个接口dma_cache_sync(),可以手动去做cache同步,上面说dma_alloc_coherent()分配的是uncached内存,但有时给DMA用的内存是其他模块已经分配好的,例如协议栈发包时,最终要把skb的地址和长度交给DMA,除了将skb地址转换为物理地址外,还要将CPU cache写回(因为cache里可能是新的,内存里是旧的)。
贴出一种实现:
void dma_cache_sync(struct device *dev, void *vaddr, size_t size,
enum dma_data_direction direction)
{
void *addr;
addr = __in_29bit_mode() ?
(void *)CAC_ADDR((unsigned long)vaddr) : vaddr;
switch (direction) {
case DMA_FROM_DEVICE: /* invalidate only */
__flush_invalidate_region(addr, size);
break;
case DMA_TO_DEVICE: /* writeback only */
__flush_wback_region(addr, size);
break;
case DMA_BIDIRECTIONAL: /* writeback and invalidate */
__flush_purge_region(addr, size);
break;
default:
BUG();
}
}
调用这个函数的时刻就是上面描述的情况:因为内存是可cache的,因此在DMA读内存(内存到设备方向)时,由于cache中可能有新的数据,因此要先将cache中的数据写回到内存;在DMA写内存(设备到内存方向)时,cache中可能还有数据没有写回,为了防止cache数据覆盖DMA要写的内容,要先将cache无效。注意这个函数的vaddr参数接收的是虚拟地址。
例如在发包时将协议栈的skb放进ring buffer之前,要做一次DMA_TO_DEVICE的flush。对应的,在收包后为ring buffer中已被使用的skb数据buffer重新分配内存后,要做一次DMA_FROM_DEVICE的flush(invalidate的时候要注意cache align)。
还有一种针对可cache的内存做一致性的方式,就是流式DMA映射。
2.2 流式DMA映射(DMA Streaming Mapping),
相关接口为 dma_map_sg(), dma_unmap_sg(),dma_map_single(),dma_unmap_single()。
一致性缓存的方式是内核专门申请好一块内存给DMA用。而有时驱动并没这样做,而是让DMA引擎直接在上层传下来的内存里做事情。例如从协议栈里发下来的一个包,想通过网卡发送出去。
但是协议栈并不知道这个包要往哪里走,因此分配内存的时候并没有特殊对待,这个包所在的内存通常都是可以cache的。
这时,内存在给DMA使用之前,就要调用一次dma_map_sg()或dma_map_single(),取决于你的DMA引擎是否支持聚集散列(DMA scatter-gather),支持就用dma_map_sg(),不支持就用dma_map_single()。DMA用完之后要调用对应的unmap接口。
由于协议栈下来的包的数据有可能还在cache里面,调用dma_map_single()后,CPU就会做一次cache的flush,将cache的数据刷到内存,这样DMA去读内存就读到新的数据了。
注意,在map的时候要指定一个参数,来指明数据的方向是从外设到内存还是从内存到外设:
从内存到外设:CPU会做cache的flush操作,将cache中新的数据刷到内存。
从外设到内存:CPU将cache置无效,这样CPU读的时候不命中,就会从内存去读新的数据。
还要注意,这几个接口都是一次性的,每次操作数据都要调用一次map和unmap。并且在map期间,CPU不能去操作这段内存,因此如果CPU去写,就又不一致了。
同样的,dma_map_sg()和dma_map_single()的后端实现也都是和硬件特性相关。
2.3其他方式
上面说的是常规DMA,有些SoC可以用硬件做CPU和外设的cache coherence,例如在SoC中集成了叫做“Cache Coherent interconnect”的硬件,它可以做到让DMA踏到CPU的cache或者帮忙做cache的刷新。这样的话,dma_alloc_coherent()申请的内存就没必要是非cache的了。
文章知识点与官方知识档案匹配,可进一步学习相关知识
另外一片文章
概述
DMA的操作是需要物理地址的,但是在linux内核中使用的都是虚拟地址,如果想要用DMA对一段内存进行操作,如何得到这一段内存的物理地址和虚拟地址的映射呢?dma_alloc_coherent这个函数实现了这种机制。
1、函数原型: void *dma_alloc_coherent( struct device *dev, size_t size,dma_addr_t *dma_handle,gfp_t gfp);
2、调用
A = dma_alloc_writecombine(B,C,D,GFP_KERNEL);
含义:
A: 内存的虚拟起始地址,在内核要用此地址来操作所分配的内存
B: struct device指针,可以平台初始化里指定,主要是dma_mask之类,可参考framebuffer
C: 实际分配大小,传入dma_map_size即可
D: 返回的内存物理地址,dma就可以用。
所以,A和D是一一对应的,只不过,A是虚拟地址,而D是物理地址。对任意一个操作都将改变缓冲区内容。
此函数的理解是,调用此函数将会分配一段内存,D将返回这段内存的实际物理地址供DMA来使用,A将是D对应的虚拟地址供操作系统调用,对A和D的的任意一个进行操作,都会改变这段内存缓冲区的内容。
DMA映射
一个DMA映射是要分配的DMA缓冲区与为该缓冲区生成的、设备可访问地址的组合。
DMA映射建立了一个新的结构类型---dma_addr_t来表示总线地址。
dma_addr_t类型的变量对驱动程序是不透明的,唯一允许的操作是将它们传递给DMA支持例程以及设备本身。
根据DMA缓冲区期望保留的时间长短,PCI代码有两种DMA映射:
1)一致性映射
2)流式DMA映射(推荐)
建立一致性DMA映射
void *dma_alloc_coherent(struct device *dev,size_t size, dma_addr_t *dma_handle,int flag);
该函数处理了缓冲区的分配和映射。
前两个参数是device结构和所需缓冲区的大小。
函数在两处返回结果:
1) 函数的返回值时缓冲区的内核虚拟地址,可以被驱动程序使用。
2) 相关的总线地址则保存在dma_handle中。
向系统返回缓冲区
void dma_free_coherent(struct device *dev,size_t size, void *vaddr,dma_addr_t dma_handle);
DMA池
————————————————
版权声明:本文为CSDN博主「leoufung」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/leoufung/article/details/121551933
关于dma_alloc_coherent的用法
关于dma_alloc_coherent的用法-CSDN博客
DMA缓存共享机制
一、共享的DMA缓存
应用:1.将视频流解码成适合图像渲染和显示的缓存格式。
2.相机捕获到适合编码和渲染的缓冲区。
要求:
1.支持添加到现存的内核子系统。
2.有允许将常见像素格式和页映射到多设备的硬件。
二、为什么要用DMA缓存共享机制
在不同设备和子系统间共享DMA缓存的统一机制目前还没有形成
不同的解决方案:
1.V4l2拥有“USERPTR”机制,对于不同的设备的内存的访问需要进行用户空间进行映射。
2.同样,wayland和x11拥有他们自己的机制,不过仅仅是在 client and compositor之间共享缓存。
3.其他的SoC提供商,框架和子系统也有他们自己的共享缓存的方法。
存在的问题:
1.在V4l2中,用户空间映射可能是必须的,但是这可能会因为内核空间和用户空间的来回震荡造成overkill。
2.目前还没有统一的共享API,因此没有统一的共享方式。
三、什么是 dma_buf API
用于共享缓冲区的通用内核级框架。
定义新的缓冲区对象,该对象提供导出和使用共享缓冲区的机制。
提供统一的API,允许与缓冲区共享相关的各种操作。
四、dma_buf中定义的operations
attach()
这是一个可选的op,它可以允许导出器收集有关连接设备的信息,它们对缓冲区的需求(如支持存储约束等),然后相应地做出决定。
如果导出器无法满足请求设备的需要,也可以用于返回错误。
detach()
这是一个可选的op,它可以允许导出器决定是否需要迁移后备存储,以及根据仍然连接的设备的更新需求对缓冲区做出类似的决定。
map_dma_buf()
强制性dma_buf_op。
导入设备用于向导出器指示启动DMA访问的请求。
返回已分配的分散页面列表,映射到设备地址空间中。
在调用map_dma_buf()之前,必须至少调用一个attach。
应该增加这个缓冲区的引脚数。
unmap_dma_buf()
强制性dma_buf_op。
导入设备用于向出口商指示DMA访问的结束。
应减少此缓冲区的使用次数。
可能取消固定缓冲区(允许它在内存中移动,换出等)…虽然出于性能原因预计导出器不会不必要地迁移缓冲区。
一旦所有当前用户都放弃了访问权限,导出器可能会决定在平台上根据需要和可能迁移缓冲区存储
五、Buffer Exporter
实现和管理缓冲区上的所有操作
允许其他用户使用dma_buf共享API共享缓冲区
管理内存后备存储的实际分配
可选地,如果可能,在平台上,如果需要,负责散布列表的迁移。
六、Buffer Importer (user)
是一个(可能很多)共享缓冲区的用户。
不关心缓冲区分配的情况和方法。
需要一种机制来访问构成内存中此缓冲区的分散列表,以便它可以访问它。
七、API
dma_buf_export():
●用于宣布导出缓冲区的愿望
●连接导出器的缓冲区私有元数据,此缓冲区的缓冲区操作实现以及关联文件的标志。
●返回dma_buf对象的句柄以及上述所有相关信息。
dma_buf_fd():
●返回与dma_buf对象关联的FD。
●然后,用户空间将FD传递给参与共享此dma_buf对象的其他设备/子系统。
dma_buf_get():
由导入设备用于获取与FD关联的dma_buf对象
dma_buf_attach():
导入设备可以使用dma_buf对象附加自身。
在dma_buf对象共享开始时调用一次。
如果由出口商提供,可以调用attach()dma_buf_op。
返回struct dma_buf_attachment ptr
dma_buf_map_attachment():
由导入设备用于请求访问缓冲区,以便它可以执行DMA。
内部调用exporter提供的map_dma_buf()dma_buf_op。
返回一个sg_table,其中包含映射在导入设备地址空间中的分散列表。
dma_buf_unmap_attachment():
DMA访问完成后,设备会告诉导出器当前
通过调用此API完成请求的访问。
内部调用导出器提供的unmap_dma_buf()dma_buf_op。
dma_buf_detach():
在需要访问此dma_buf对象时,导入器设备会告诉导出器其意图从当前共享中“分离”。
如果出口商提供,可以调用detach()dma_buf_op。
dma_buf_put():
调用dma_buf_detach()后,通过调用dma_buf_put()减少此缓冲区的引用计数。
八、dma_buf usage flow

————————————————
版权声明:本文为CSDN博主「stoneboy_z」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/stoneboy_z/article/details/88615561
番外篇
我们在思维上,一定要想到 dma_alloc_coherent 的接口,只是一个前端,它具体的实现是和硬件有关系的,是和平台有关系的。
(1) 下面的例子是 CPU 内部有 保证 cache 一致性的组件,所以dma_alloc_coherent 也是可以申请到 带 cache的内存的。

(2) DMA scatter-gather (DMA引擎是否支持聚集散列) -- 不需要物理内存连续 ,流式映射。
DMA scatter-gather (DMA引擎是否支持聚集散列)
Scatter:离散(不连续)
Gather:聚合 (连续)
这个时候 DMA的内存就可以是物理不连续的了,可以将 连续的内存中的数据 搬移 到 不连续的内存。 可以将不连续的内存 搬移到 连续的内存。
硬件上可以连续传送多个buffer ,不需要物理内存的连续。
这个时候,如果要进行流式映射,要用到 dma_map_sg() , 会将 多个不连续的 内存,都从 cache 上 flush一下,或者 invalid cache。
(3) 带 MMU 的 DMA引擎 (叫IOMMU 或者 SMMU)
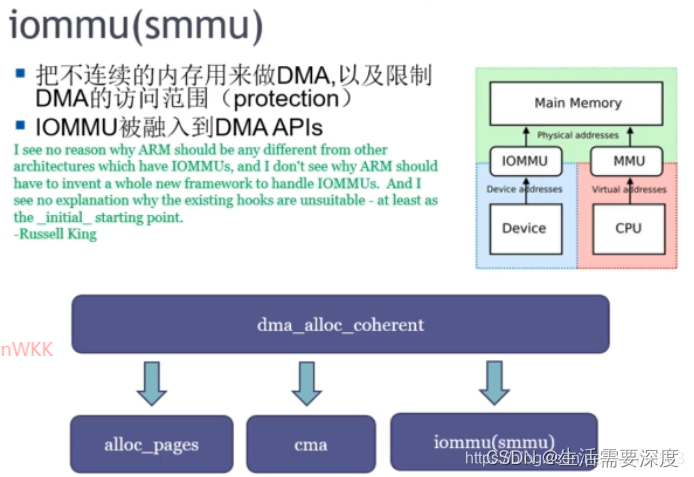
dma_alloc_coherent 只是一个前端,后端直接可以跟 buddy 要内存,也可以跟CMA要内存,也可以通过 IOMMU / SMMU。
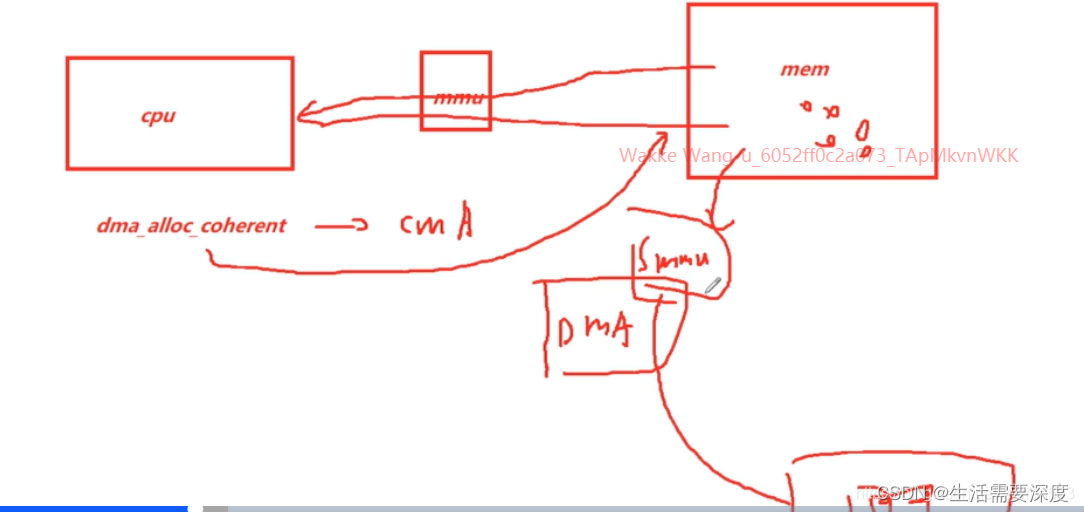
IOMMU 或者 SMMU 会 将不连续的物理地址,通过页表映射的方式,统一变成虚拟地址连续的地址,然后给到DMA使用。
这些都是硬件来做的。所以 dma_alloc_coherent 申请到的物理内存是可以不连续的。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/Adrian503/article/details/115536886















 1284
1284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









