







同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,我先限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。本文最重要的参考文献是Richard Stevens的“UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking ”,6.2节“I/O Models ”,Stevens在这节中详细说明了各种IO的特点和区别,如果英文够好的话,推荐直接阅读。Stevens的文风是有名的深入浅出,所以不用担心看不懂。本文中的流程图也是截取自参考文献。
* blocking IO
* nonblocking IO
* IO multiplexing
* signal driven IO
* asynchronous IO
由signal driven IO在实际中并不常用,所以主要介绍其余四种IO Model。
再说一下IO发生时涉及的对象和步骤。对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO模型的区别就是在两个阶段上各有不同的情况。
1、阻塞IO(blocking IO )
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
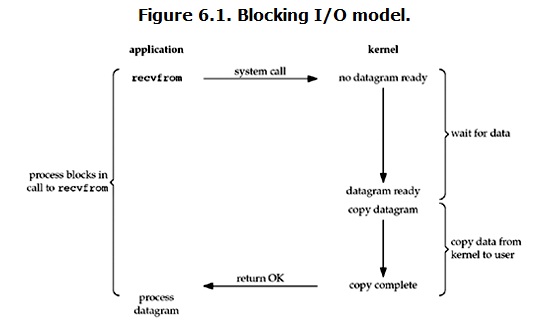
图1 阻塞IO
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
几乎所有的程序员第一次接触到的网络编程都是从listen()、send()、recv() 等接口开始的,这些接口都是阻塞型的。使用这些接口可以很方便的构建服务器/客户机的模型。下面是一个简单地“一问一答”的服务器。

图2 简单的一问一答的服务器/客户机模型
我们注意到,大部分的socket接口都是阻塞型的。所谓阻塞型接口是指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
实际上,除非特别指定,几乎所有的IO接口 ( 包括socket接口 ) 都是阻塞型的。这给网络编程带来了一个很大的问题,如在调用send()的同时,线程将被阻塞,在此期间,线程将无法执行任何运算或响应任何的网络请求。
一个简单的改进方案是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。具体使用多进程还是多线程,并没有一个特定的模式。传统意义上,进程的开销要远远大于线程,所以如果需要同时为较多的客户机提供服务,则不推荐使用多进程;如果单个服务执行体需要消耗较多的CPU资源,譬如需要进行大规模或长时间的数据运算或文件访问,则进程较为安全。通常,使用pthread_create ()创建新线程,fork()创建新进程。
我们假设对上述的服务器 / 客户机模型,提出更高的要求,即让服务器同时为多个客户机提供一问一答的服务。于是有了如下的模型。

图3 多线程的服务器模型
在上述的线程 / 时间图例中,主线程持续等待客户端的连接请求,如果有连接,则创建新线程,并在新线程中提供为前例同样的问答服务。
很多初学者可能不明白为何一个socket可以accept多次。实际上socket的设计者可能特意为多客户机的情况留下了伏笔,让accept()能够返回一个新的socket。下面是 accept 接口的原型:
int accept(int s, struct sockaddr *addr, socklen_t *addrlen);
输入参数s是从socket(),bind()和listen()中沿用下来的socket句柄值。执行完bind()和listen()后,操作系统已经开始在指定的端口处监听所有的连接请求,如果有请求,则将该连接请求加入请求队列。调用accept()接口正是从 socket s 的请求队列抽取第一个连接信息,创建一个与s同类的新的socket返回句柄。新的socket句柄即是后续read()和recv()的输入参数。如果请求队列当前没有请求,则accept() 将进入阻塞状态直到有请求进入队列。
上述多线程的服务器模型似乎完美的解决了为多个客户机提供问答服务的要求,但其实并不尽然。如果要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而线程与进程本身也更容易进入假死状态。
很多程序员可能会考虑使用“线程池”或“连接池”。“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。这两种技术都可以很好的降低系统开销,都被广















 5740
5740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









