







1. 什么情况使用索引?
答: 当数据量在千条以上 , 不重复的值比重越大的时候使用索引效果越好.
测试不重复数据的比重的SQL语句 :
select count(distinct 字段名) / count from 表名
数值越接近1 越适合使用索引
2. 什么聚(集)簇索引,什么是非聚(集)簇索引? 分别对应什么引擎?
答 : 简单来理解,聚簇索引就是数据跟索引是在一起的,对应的是innodb存储引擎.,非集簇索引就是数据跟索引是分开的, 对应的是myisam.
验证 : 当数据表是innodb存储引擎的时候,默认的情况下 :
会在数据库目录下有一个表名.frm 表结构文件
数据跟索引保存在data目录下的ibdata1 文件下.
[补充 :设置 innodb_file_per_table=1这个属性,实现一个表对应一个数据跟索引文件, set global innodb_file_per_table =1; 查看属性值 innodb_file_per_table
(show variables like 'innodb_file_per_table')
就会在数据库目录下生成一个 表名.ibd
]
如果是myisam存储引擎,对应3个文件 ,分别是
表名.frm(表结构文件)
表名.MYD(数据文件)
表名.MYI(索引文件)
3.主键索引跟普通索引注意事项.
因为innodb是集簇索引,其主键索引是会进行排序,如果插入的数据不是有序的,那么这时候ID会去进行排序,后面的数据区就要进行数据区移动,数据量越大消耗的IO越大
innodb的普通索引下面的数据区保存的是主键的id,这些ID会在普通索引进行搜索的时候返回,再进行主键索引查找.所以普通索引的查询会出现2次遍历..
4.innodb 存储引擎跟 myisam的区别 ?
- 2者的数据结构不一样
- innodb支持事务, myisam不支持事务
- innodb支持外键,myisam不支持外键
- innodb 5.6才开始支持全文索引,myisam支持全文索引.
- innodb不支持压缩,myisam支持压缩(myisampack压缩 ,myisamchk 解压)
5.mysiam 压缩的注意事项 (知识补充)
通过mysql/bin/myisampack 进行压缩
例如 :
- /usr/local/mysql/bin/myisamchk 要压缩表的路径(不带后缀,即表名)
- 压缩完发现 索引文件坏掉了,重新生成索引文件
- myisamchk -rq 表的路径 [不带后缀,到表名]
- 注意: 压缩后的文件只能查询,不能修改 ,注意要刷新硬盘
- flush tables; 多刷新几次
- 通过 myisamchk 进行解压
- myisamchk --unpack 压缩表的绝对路径[不带后缀,到表名]
- 刷新硬盘,多刷新几次 flush tables;
6. 数据备份跟还原 (知识补充)
- 第一种,直接备份文件 cp -p 表文件 目标路径
- 还原时直接拷贝到指定数据库的目录下面,在mysql中使用flush tables;
- 第二种 : 通过工具软件备份mysqldump
- mysqldump -u 用户名 -p 库名 [表名] [-B 有创建数据库的语句] > 保存的绝对路径
- 还原 : 通过工具软件还原: mysql -u用户名 -p < 库文件的绝对路径
7. ip地址的转换
- PHP端的转换
- ip地址转换成整形 ip2long()
- 整形转换成ip地址 longip2()
- mysql的转换
- ip地址转换成整形: inet_aton();
- 整形转换成ip : inet_ntoa();
8.MySQL 查询语句的性能优化 explain(说明)
使用 : explain 查询语句
例如 : explain select * from innodb\G;
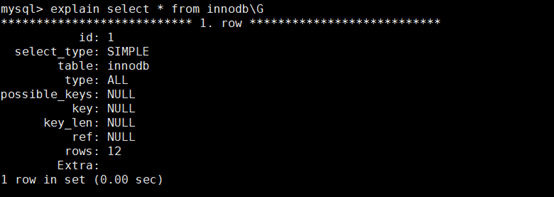
table : 表名
type
: 对数据的处理
const | ref | range | ndex | ALL
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
小 --------------------------------- 最大
- const : 扫描数据1行或者2行的时候
- ref : 这个的扫描范围比range小range: 这个扫描范围比 index 的小
- ALL : 硬盘数据的扫描 [ 如果出现,考虑优化SQL语句]
possible_keys
: 能会用到的索引
key : 实际用到的索引
key_len : 索引的的长度
rows : 扫描的行
9.百万级别的分页原理.
例如 $page 代表当前页码 $page_size 代表分页大小 $tb_name代表表名
PHP代码 : $ start = ($page-1)* $tb_name;
那么SQL代码如下
select * from $tb_name where id>(
select id from $tb_name limit $start,1
) limit $page_size
10. 千万级别的分页解决思路(不合格);还需探讨中
(有思路的伙伴们,希望给我留言)















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









