







Apriori算法:
如果小的项集比较频繁,那么由它组成的大的项集也可能是频繁的;
如果小的项集不频繁,那么由它组成的大的项集必然不频繁。
所以,可以先排除小的不频繁项集,减少搜索空间。
#include "iostream"
#include "vector"
#include "set"
#include "string"
#include "map"
#include "algorithm"
using namespace std;
//准备数据集
set< set<char> > loadDataSet()
{
set< set<char> > s;
char s1[] = {'1', '3', '4'};
char s2[] = {'2', '3', '5'};
char s3[] = {'1', '2', '3', '5'};
char s4[] = {'2', '5'};
set<char> ss1(s1, s1 + sizeof(s1) / sizeof(char));
set<char> ss2(s2, s2 + sizeof(s2) / sizeof(char));
set<char> ss3(s3, s3 + sizeof(s3) / sizeof(char));
set<char> ss4(s4, s4 + sizeof(s4) / sizeof(char));
s.insert(ss1);
s.insert(ss2);
s.insert(ss3);
s.insert(ss4);
return s;
}
//构造长度为1的侯选集
//data为原始数据库
set< set<char> > createC1(set< set<char> > &data)
{
set< set<char> > C1;
set<char> s;
set< set<char> >::iterator it1;
set<char>::iterator it2;
for(it1 = data.begin(); it1 != data.end(); it1++)
{
for(it2 = (*it1).begin(); it2 != (*it1).end(); it2++)
{
s.insert(*it2);
}
}
set<char>::iterator it;
for(it = s.begin(); it != s.end(); it++)
{
set<char> tmp;
tmp.insert(*it);
C1.insert(tmp);
}
return C1;
}
//从候选集Ck中删除支持度小的项
//data为原始数据库
//Ck为侯选集
//suportData为输出向
set< set<char> > scanD(set< set<char> > &data, set< set<char> > &Ck, double minSupport)
{
//得到每个候选项的支持量
int n = data.size();
map< set<char>, int> ssCnt;
set< set<char> >::iterator it, it1;
for(it=Ck.begin(); it != Ck.end(); it++)
ssCnt[*it] = 0;
for(it=data.begin(); it != data.end(); it++)
{
for(it1=Ck.begin(); it1 != Ck.end(); it1++)
{
vector<char> tmp;
set_difference((*it1).begin(), (*it1).end(), (*it).begin(), (*it).end(), back_inserter(tmp));
if(tmp.size() == 0) //如果当前侯选项在dataset[i]中
{
ssCnt[(*it1)] += 1;
}
}
}
//用支持量/原始数据条目数,得到支持度
set< set<char> > retList;
map< set<char>, int>::iterator it2;
for(it2 = ssCnt.begin(); it2 != ssCnt.end(); it2++)
{
double sup = (double)(it2->second) / (double)n;
if(sup >= minSupport)
{
retList.insert(it2->first);
}
}
return retList;
}
//创建Ck,也就是将Lk中的元素组合,得到更大的侯选集Ck,Ck中的每个项长度为k
set< set<char> > aprioriGen(set< set<char> > &Lk, int k)
{
set< set<char> > retList;
int lenLk = Lk.size();
set< set<char> >::iterator it, it1;
for(it=Lk.begin(); it != Lk.end(); it++)
{
for(it1=it; it1 != Lk.end(); it1++)
{
if(it != it1)
{
vector<char> tmp;
set_union((*it).begin(), (*it).end(),(*it1).begin(),(*it1).end(), back_inserter(tmp));
set<char> L(tmp.begin(), tmp.end());
retList.insert(L);
}
}
}
return retList;
}
//输出所有的频繁项集
vector< set< set<char> > > Apriori(set< set<char> > &dataset, double minSupport)
{
vector< set< set<char> > > L;
set< set<char> > C1 = createC1(dataset); //生成长度为1的候选项集
set< set<char> > L1;
L1 = scanD(dataset, C1, minSupport); //生成长度为1的频繁项集
L.push_back(L1);
int k = 2;
while(L[k-2].size() > 0)
{
set< set<char> > Ck = aprioriGen(L[k-2], k); //生成长度为k的候选项集
set< set<char> > Lk = scanD(dataset, Ck, minSupport); //生成长度为k的频繁项集
L.push_back(Lk);
k++;
}
return L;
}
int main()
{
set< set<char> >::iterator it;
set<char>::iterator it1;
set< set<char> > data = loadDataSet();
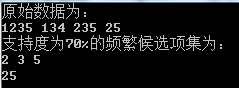
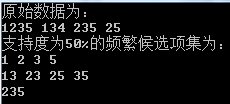
cout << "原始数据为:\n";
for(it = data.begin(); it != data.end(); it++)
{
for(it1 = (*it).begin(); it1 != (*it).end(); it1++)
cout << *it1;
cout << " ";
}
cout << endl;
vector< set< set<char> > > L = Apriori(data, 0.7);
cout << "支持度为70%的频繁候选项集为:\n";
for(int k=0; k<L.size(); k++)
{
for(it = L[k].begin(); it != L[k].end(); it++)
{
for(it1 = (*it).begin(); it1 != (*it).end(); it1++)
cout << *it1;
cout << " ";
}
cout << endl;
}
cout << endl;
return 0;
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









