







软件下载、安装
地址:http://blog.csdn.net/a819825294/article/details/51627083
注意:其中,jdk 1.8不能用,需要重新百度,然后下载
补充1:在添加spark-assembly-1.3.0-hadoop2.4.0.jar时,需要先点“java”:
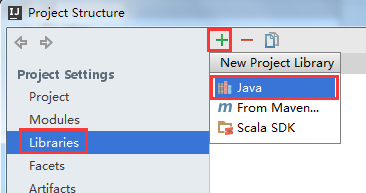
然后找到jar所在位置,添加进来
如果Scala SDK没有被自动识别,还需添加“Scala SDK”
补充2:在windows下还需要winstalls.exe,否则代码运行后会报错:
16/11/19 17:55:52 INFO SparkContext: Running Spark version 1.3.0
16/11/19 17:55:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/19 17:55:53 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:318)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:333)添加环境变量:
下载完后,右击“电脑”–>“属性”–>”高级环境设置”–>“环境变量”–>“系统变量”–>“新建”–>变量名:HADOOP_HOME,变量值:解压后文件中会有一个bin目录,该bin目录的上一级,例如 F:\hadoop-common-2.2.0-bin-master\
修改path:添加 %HADOOP_HOME%\bin
如果环境变量不奏效,可以在代码中加入以下语句:
System.setProperty("hadoop.home.dir", "F:/hadoop-common-2.2.0-bin-master")编写spark程序
File–>New–>Project–>
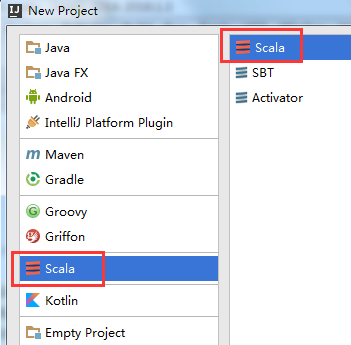
一定要注意版本选择,可以是2.10.3、也可以是2.10.4,而不能选择2.12.0、2.11.8等高版本,否则程序运行后会报错
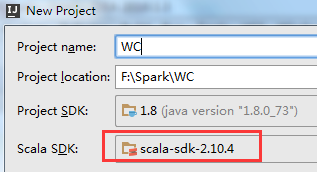
接下来,需要等比较长的时间,然后就会出现如下界面:
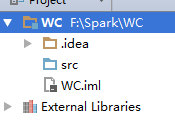
右击“src”–>New–>”Scala Class”
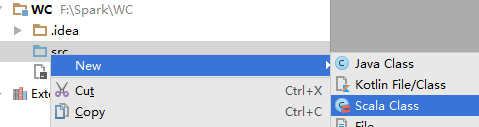
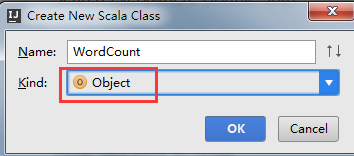
选择Object
接着在C盘下建立一个txt文件,写入一些以空格相隔的单词
然后在 新建的“WordCount”中写入:
import org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
System.setProperty("hadoop.home.dir", "F:/hadoop-common-2.2.0-bin-master")
def main(args: Array[String]): Unit ={
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("Wordcount")
val sc = new SparkContext(conf)
val data = sc.textFile("C://wc.txt") // 文本存放的位置
data.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
}
}
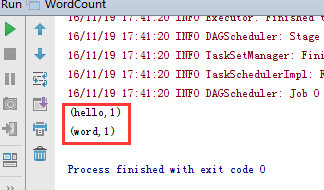
结果如下:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









