







前言
这段时间复习数据结构,从二叉树开始看,到后面是二叉排序树,平衡树,红黑树等,看完树还要看图,然后是排序和查找算法。今天把实现了的二叉树的代码总结一下,理理思路。
数据结构中,二叉树的遍历分为三种方式:前序,中序,后序。所谓前中后,我觉得就是根节点的遍历顺序,如果根节点第一个访问就是前序,第二个访问就是中序,最后一个访问就是后序。而遍历的手段有两种–递归和非递归。
我写的是java代码,在读懂别人的基础上自己实现。
思路
递归遍历
如果不死命的去想清楚每一次的调用的话(我曾经想破脑袋),递归理解起来非常简单,利用分治的思想,设置好递归结束的判断条件,这里是节点==null,在访问根节点的孩子节点的时候,又会访问到孩子节点的孩子节点,如果孩子节点的孩子节点还有孩子节点,就一直从上到下去访问,直到碰到了结束条件,即节点为空。然后就可以往回返结果了,一层层退回去,返回最初的入口。然后继续执行下面的语句。可以使用递归的原因是每个节点都可能是根节点,而且这些根节点的基本结构都是一样的。代码如下:
// 前序递归遍历
public void preOrder(TreeNode subTree){
if(subTree==null)
return;
else{
visit(subTree);
preOrder(subTree.leftChild);
preOrder(subTree.rightChild);
}
}
// 中序递归遍历
public void inOrder(TreeNode subTree){
if(subTree==null)
return;
else{
inOrder(subTree.leftChild);
visit(subTree);
inOrder(subTree.rightChild);
}
}
// 后序递归遍历
public void postOrder(TreeNode subTree){
if(subTree==null)
return;
else{
postOrder(subTree.leftChild);
postOrder(subTree.rightChild);
visit(subTree);
}
}非递归遍历
因为递归遍历是非常消耗内存而且耗时的操作,递归分为递,归两个步骤。递的时候要保存入口,方便归。所以最好还是使用非递归算法。非递归算法是用栈实现的,因为栈的特点是先进后出,这样从最上面的根节点开始压栈,然后是它的孩子节点压栈,一直到最下面。弹栈时候就可以先访问最下面的节点,即栈顶节点,一直弹栈直到最初放入的那个节点。这样就实现了和递归一样的功能,就是把路过的需要保存的节点都保存起来,然后往回走。这个也与树的结构有关系,因为树的结构就是每一个节点都可能是下面的一个分支的根节点,所以遍历的时候也是从最下面的开始,遍历完一个分支就完成了一个孩子节点的遍历。访问完三个这样的分支一个大的分支也就访问完了。
非递归前序遍历
前序遍历就是根,左,右的顺序。先从最顶端的根节点开始沿着左支压栈,每次压栈都访问,这样一路下来就遍历了根,左,只有右节点都还没有被访问,所以就开始弹栈,得到栈中根节点的右孩子,然后重复这个循环,因为每个根节点都要经历这个循环。代码如下:
//非递归前序遍历,用栈实现
public void nonRecPreOrder(TreeNode subTree){
Stack<TreeNode> stack=new Stack<>();
TreeNode p=subTree;
while(p!=null||stack.size()>0){
// 先把左节点全部入栈,这些左节点将作为根节点
while(p!=null){
visit(p);
stack.push(p);
p=p.leftChild;
}
// 没有左节点了,就弹栈,将弹出的节点的右孩子节点压栈
if(stack.size()>0){
p=stack.pop();
p=p.rightChild;
}
}
}非递归中序遍历
左,根,右的顺序,和前序的区别就是访问是在弹栈的时候,因为弹的时候是从最左开始。代码如下:
// 非递归中序遍历
public void nonRecInOrder(TreeNode subTree){
Stack<TreeNode> stack=new Stack<>();
TreeNode p=subTree;
while(p!=null || stack.size()>0){
while(p!=null){
stack.push(p);
p=p.leftChild;
}
if(stack.size()>0){
p=stack.pop();
visit(p);
p=p.rightChild;
}
}
}非递归后序遍历
这个就稍微复杂一些,因为访问顺序是左,右,根,这样左和根节点是不紧挨着访问的。实现的思路仍然是要先把节点从左边一直压栈,然后从最左开始访问,如果遇到了右孩子没有被访问的节点就把这个右节点当作一个新的根节点去压栈,然后从最左开始访问。这里面就是多了一个节点的右孩子节点是否为空的判断。代码如下:
// 非递归后序遍历
public void nonRecPostOrder(TreeNode subTree){
Stack<TreeNode> stack=new Stack<>();
TreeNode p=subTree;
TreeNode node=null;
while(p!=null){//处理一个根节点
// 把这个根节点的所有左孩子都压入栈中,从上到下
// 这里最后一个节点没有压栈
for(;p.leftChild!=null;p=p.leftChild)
stack.push(p);
// 开始依次处理栈中的根节点
// 当前节点不为空且没有右孩子或者右孩子已经访问过,根据后序遍历的定义,可以直接访问该根节点了
while(p!=null&&p.rightChild==null||p.rightChild==node){
visit(p);
// 记录一下,因为如果弹栈之后遇到了右孩子不为空的根节点,就会先把这个根节点再次压回栈中,然后把它的右孩子节点也压入栈中
// 这样,栈中,右孩子节点就在根节点的上面紧挨着根节点,访问的时候,也是访问完右孩子就直接访问它
// 所以,判断某个右孩子不为空的根节点孩子是否被访问过,就看node==rightChild与否
node=p;
if(stack.size()==0)
return;
// 栈不为空,继续弹出处理根节点
p=stack.pop();
}
// 这里的p是右孩子没有被访问过的根节点,把这个已经在while循环中弹出的根节点先压回栈中
stack.push(p);
// 然后得到它的右孩子,继续新的一支的压栈,弹栈,访问处理
// 处理完它的右孩子自然就会处理栈中刚刚压回的处于下一个位置的根节点
p=p.rightChild;
}
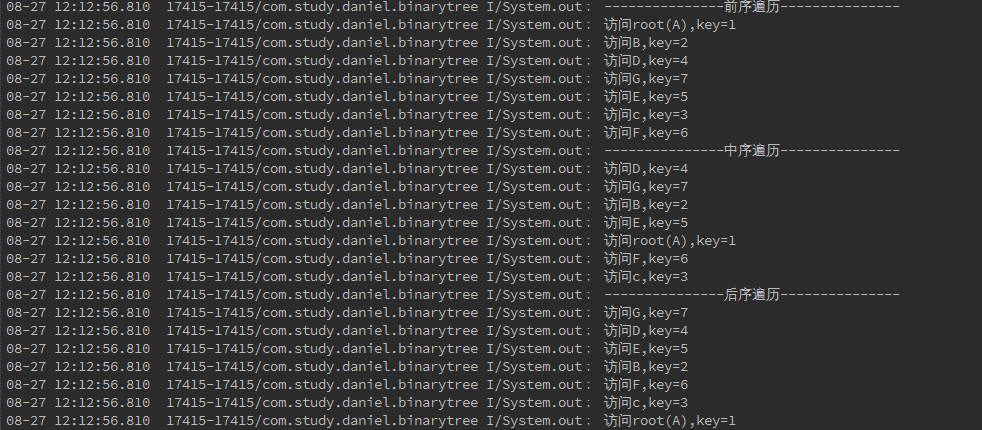
}运行结果:



代码:
代码上传至csdn,测试通过,大家自行下载:
http://download.csdn.net/detail/u012320459/9054521















 4660
4660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









