








在设计和训练机器学习模型后,数据科学家会部署这些模型,以便应用程序可以使用。Amazon Lambda是一项让您在运行代码时无需预置或管理服务器的计算服务。Amazon Lambda的按请求付费、自动扩展和易用性使其成为数据科学团队的热门部署选择。
Amazon Lambda
https://aws.amazon.com/cn/lambda/
数据科学家可以使用更少的代码就能将模型转变为由Amazon Lambda支持的经济高效且可扩展的API终端节点。Amazon Lambda支持容器镜像、Advanced Vector Extensions 2(AVX2)和具有高达10GB内存的函数。使用这些函数,数据科学团队可以部署更大、更强的模型并提高性能。
要部署基于Amazon Lambda的应用程序,无服务器开发人员可以使用Amazon Serverless Application Model(Amazon SAM)。Amazon SAM基于模板创建和管理无服务器应用程序。它支持本地测试,旨在实现最佳实践,并可与流行的开发工具集成。它允许数据科学家使用YAML定义无服务器应用程序、安全权限和高级配置功能。
Amazon Serverless Application Model(Amazon SAM)
https://github.com/aws/serverless-application-model
Amazon SAM包含可让开发人员快速入门的预构建模板。本博客展示了如何使用机器学习模板部署基于Scikit-Learn的模型,该模型可以分类从0到9的手写数字图像。部署到Amazon Lambda后,您可以通过一个REST API访问模型。
示例会在亚马逊云科技账户中创建会产生成本的资源。为了最大限度地降低成本,请在完成示例内容后按照最后的清理部分说明删除资源。

???? 想要了解更多亚马逊云科技最新技术发布和实践创新,敬请关注在上海、北京、深圳三地举办的2021亚马逊云科技中国峰会!点击图片报名吧~上海站峰会已经圆满落幕,更多精彩内容,敬请期待北京、深圳分会吧!
概览
Amazon SAM机器学习模板可用于Scikit-Learn、PyTorch、TensorFlow和 XGBoost框架。每个模板都部署一个Amazon Lambda函数来管理Amazon API Gateway网管后面的模型,该网关作为前端并处理身份验证。下图显示了这个解决方案的架构:
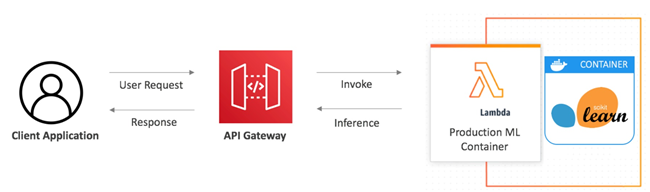
机器学习推理的无服务器架构
Amazon API Gateway网管
https://aws.amazon.com/cn/api-gateway/
创建容器化
Amazon Lambda函数
本节将使用Amazon SAM在Amazon Lambda上构建、测试和部署包含预先训练的数字分类器模型的Docker镜像:
更新或安装Amazon SAM,使用机器学习模板需要Amazon SAM CLI v1.24.1或更高版本。
在终端中,使用以下命令在Amazon SAM中创建新的无服务器应用程序:sam init
按照屏幕上的提示,选择Amazon快速入门模板作为模板来源。

Amazon SAM:选择模板来源
选择镜像作为打包类型。

Amazon SAM:选择封装类型
选择amazon/python3.8-base作为基础镜像。
Amazon SAM:选择运行时镜像
出现提示时,输入应用程序名称。Amazon SAM使用它对其创建的资源进行分组和打标签。

Amazon SAM:选择运行时镜像
从模板列表中选择所需的机器学习框架,本示例使用 Scikit-Learn 模板。

Amazon SAM:选择应用程序模板
Amazon SAM使用您的应用程序名称创建一个目录,切换到新目录并运行Amazon SAM生成命令:sam build
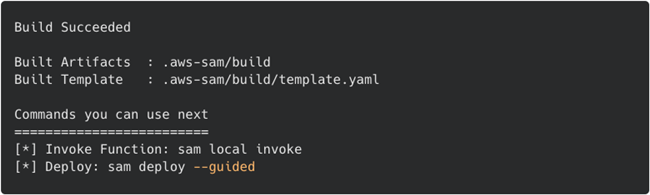
Amazon SAM:构建结果
由Amazon SAM生成的文件
选择模板后,Amazon SAM将在应用程序目录中生成以下文件:
Dockerfile:该应用程序使用Amazon Lambda提供的Python 3.8基础镜像。它已经安装了相关的依赖项并为Amazon Lambda执行环境定义了CMD变量以初始化处理程序。
FROM public.ecr.aws/lambda/python:3.8
COPY app.py requirements.txt ./
COPY digit_classifier.joblib /opt/ml/model/1
RUN python3.8 -m pip install -r requirements.txt -t .
CMD ["app.lambda_handler"]
app.py:这段Python代码在调用Amazon Lambda处理程序后运行,并会从Scikit-Learn模型中生成预测结果。通过在Amazon lambda_handler之外加载模型,可在多个Amazon Lambda调用中重复使用该模型。
import joblib
import base64
import numpy as np
import json
from io import BytesIO
from PIL import Image
from scipy.ndimage import interpolation
model_file = '/opt/ml/model'
model = joblib.load(model_file)
# Functions to pre-process images (we used same preprocessing when training)
def moments(image):
c0, c1 = np.mgrid[:image.shape[0], :image.shape[1]]
img_sum = np.sum(image)
m0 = np.sum(c0 * image) / img_sum
m1 = np.sum(c1 * image) / img_sum
m00 = np.sum((c0-m0)**2 * image) / img_sum
m11 = np.sum((c1-m1)**2 * image) / img_sum
m01 = np.sum((c0-m0) * (c1-m1) * image) / img_sum
mu_vector = np.array([m0,m1])
covariance_matrix = np.array([[m00, m01],[m01, m11]])
return mu_vector, covariance_matrix
def deskew(image):
c, v = moments(image)
alpha = v[0,1] / v[0,0]
affine = np.array([[1,0], [alpha,1]])
ocenter = np.array(image.shape) / 2.0
offset = c - np.dot(affine, ocenter)
return interpolation.affine_transform(image, affine, offset=offset)
def get_np_image(image_bytes):
image = Image.open(BytesIO(base64.b64decode(image_bytes))).convert(mode='L')
image = image.resize((28, 28))
return np.array(image)
# Lambda handler code
def lambda_handler(event, context):
image_bytes = event['body'].encode('utf-8')
x = deskew(get_np_image(image_bytes))
prediction = int(model.predict(x.reshape(1, -1))[0])
return {
'statusCode': 200,
'body': json.dumps(
{
"predicted_label": prediction,
}
)
}
完成这些步骤后,目录结构如下所示:

文件结构
测试Amazon SAM模板
对于基于容器镜像的Amazon Lambda函数,Amazon sam build会在本地Docker存储库中创建和更新容器镜像。它将模板复制到输出目录并更新新建镜像的位置。
您可以在amazon-sam目录下看到以下顶层目录树结构:

Amazon SAM构建构件目录结构
构建Docker镜像后,使用Amazon SAM的本地测试功能测试终端节点。有两种方法可以在本地测试应用程序:
本地调用 — 事件使用event.json中的模拟数据来调用函数并生成预测。手写数字的图像被编码为event.json文件中body属性中的base64字符串。使用event.json模拟数据进行测试:
sam local invoke InferenceFunction --event events/event.json
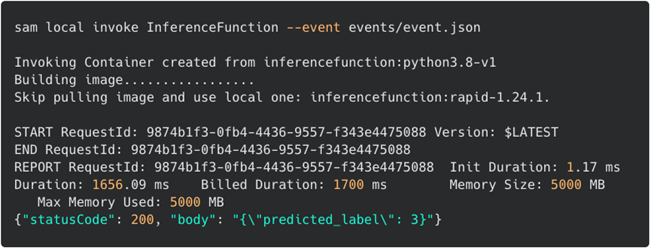
Amazon SAM本地调用结果
通过start-api命令启动一个模拟REST API终端节点的本地终端节点。它会下载一个在本地运行API Gateway和Amazon Lambda函数的执行容器。使用API Gateway模拟器调用:sam local start-api
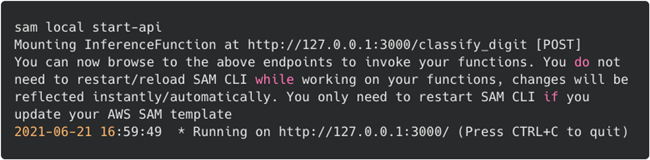
Amazon SAM本地start-api监控
要测试本地端点,请使用Postman等REST API客户端向/classify_digit终端节点发送POST请求。
Postman
https://www.postman.com
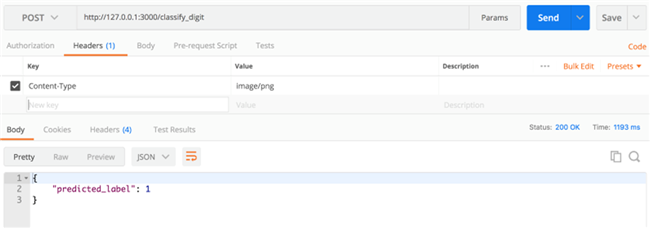
用Postman进行测试
在本地测试时,请使用小于100 KB的图像。如果文件较大,请求会失败并显示状态代码502,错误信息为“argument list too long”(参数列表过长)。但是在部署到Amazon Lambda之后,您可以使用更大的图像。
部署应用程序到
Amazon Lambda
在本地测试模型后,使用Amazon SAM引导式部署流程打包和部署应用程序:
要基于容器镜像部署Amazon Lambda函数,必须将容器镜像推送到Amazon Elastic Container Registry(ECR)。运行以下命令以检索身份验证令牌并使用ECR注册表对Docker客户端进行身份验证。将region和accountID占位符替换为您的区域和亚马逊云科技账户ID:
aws --region <region> ecr get-login-password | docker login --username AWS --password-stdin <accountID>.dkr.ecr.<region>.amazonaws.com
Amazon Elastic Container Registry(ECR)
https://aws.amazon.com/cn/ecr/

登录成功
使用Amazon CLI创建一个名为classifier-demo的ECR存储库:
aws ecr create-repository \
--repository-name classifier-demo \
--image-tag-mutability MUTABLE \
--image-scanning-configuration scanOnPush=true
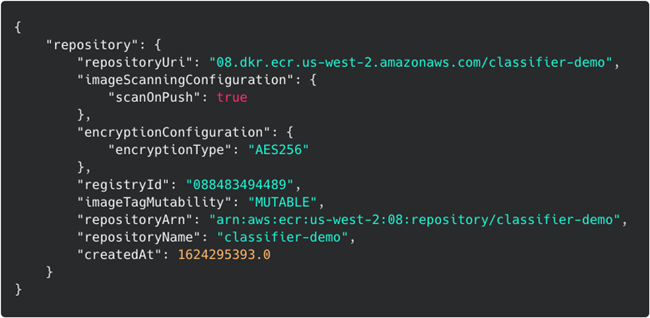
创建ECR存储库结果
从输出中复制repositoryUri,我们在下一步中将会用到。使用deploy命令启动Amazon SAM引导式部署:sam deploy --guided
按照屏幕上的提示进行操作。要接受互动体验中提供的默认选项,请按Enter键。当系统提示输入ECR存储库时,请使用在上一步中创建的Amazon ECR存储库。
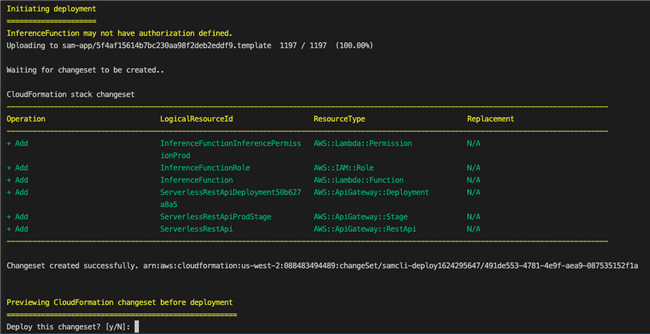
CloudFormation更改集验证截图
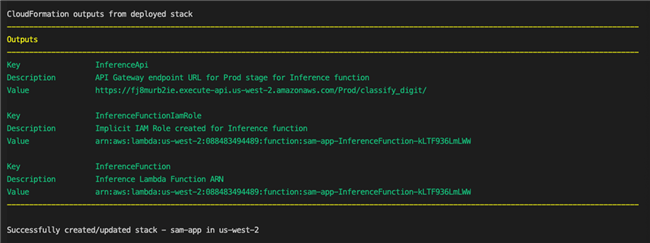
CloudFormation输出
Amazon SAM将应用程序打包并部署为带有版本控制的实体。部署后,生产API终端节点就可以使用了。该模板会生成多个输出,在“Outputs”部分的“HelloWorldAPI”键中可以找到终端节点的URL。
找到URL后,使用REST客户端测试实时终端节点:
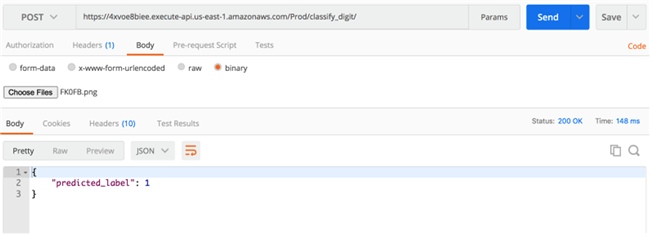
用Postman进行测试
优化性能
部署Amazon Lambda函数后,您可以针对延迟和成本进行优化。为此,请调整函数的内存分配设置,这也会线性更改分配的vCPU(要了解更多信息,请阅读亚马逊云科技新闻博客)。
亚马逊云科技新闻博客
https://aws.amazon.com/cn/blogs/aws/new-for-aws-lambda-functions-with-up-to-10-gb-of-memory-and-6-vcpus/
数字分类器模型使用5GB内存(约3个vCPU)进行了优化。超过5GB的任何收益都相对较小。每个模型对vCPU和内存的变化的响应不同,因此最佳做法是通过实验来确定这一点。这部分有开源工具可用于自动调整性能。
开源工具
https://github.com/alexcasalboni/aws-lambda-power-tuning
可以通过编译源代码以利用AVX2指令进行进一步优化。AVX2允许Amazon Lambda在每个时钟周期运行更多操作,从而减少了模型生成预测所需的时间。
利用AVX2指令
https://aws.amazon.com/cn/blogs/compute/creating-faster-aws-lambda-functions-with-avx2/
清理
上述示例创建了Amazon Lambda函数、API Gateway终端节点和ECR存储库。这些资源会产生费用,因此建议清理资源以避免产生额外的成本。要删除ECR存储库,请运行:
aws ecr delete-repository --registry-id <account-id> --repository-name classifier-demo --force
要删除剩余资源,请导航到亚马逊云科技管理控制台中的Amazon CloudFormation,然后选择用于示例的区域。选择Amazon SAM创建的堆栈(默认为“sam-app”),然后选择Delete(删除)。
Amazon CloudFormation
https://aws.amazon.com/cn/cloudformation/
结论
对于数据科学家来说,要部署基于CPU的机器学习模型进行推理,Amazon Lambda是一种经济高效、可扩展且可靠的方式。凭借对更大的函数大小、AVX2指令集和容器镜像的支持,Amazon Lambda现在可以部署更复杂的模型,同时保持低延迟。
欢迎使用Amazon SAM中新的机器学习模板,在数分钟内部署您的第一个无服务器机器学习应用程序吧。我们期待看到您在Amazon Lambda上构建的激动人心的机器学习应用程序。
有关更多无服务器学习资源,请访问Serverless Land。
Serverless Land
https://serverlessland.com
本篇作者
Sean Wilkinson
亚马逊云科技机器学习专家解决方案架构师
Newton Jain
亚马逊云科技Amazon Lambda高级产品经理

听说,点完下面4个按钮
就不会碰到bug了!
















 8683
8683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









