








在刚刚圆满落幕的亚马逊云科技中国峰会上海站,FreeWheel的Tech Lead曹宇先生和大家分享了现代化应用和无服务器的奥秘。点击下方视频,一探究竟。
今天,我们为大家带来FreeWheel首席工程师杨敏关于软件分层设计的思考和见解,以下为全文:
*本文2021年7月29日首发于微信公众号“架构头条”
在日常开发中,经常听到大家说一句话“任何需求都可以通过一个间接的中间层来解决”。今天,通过几个case就“分层”话题梳理下自己的思考,其中,有些case比较直观,而有些不那么直观,甚至有些微妙,需要我们自己多品味。这意味着学习过程需要我们不断将新知识与旧知识进行关联,形成自己的知识体系,而非一个个知识孤岛。

???? 想要了解更多亚马逊云科技最新技术发布和实践创新,敬请关注2021亚马逊云科技中国峰会!点击图片报名吧~
什么是分层设计?
它有何好处?
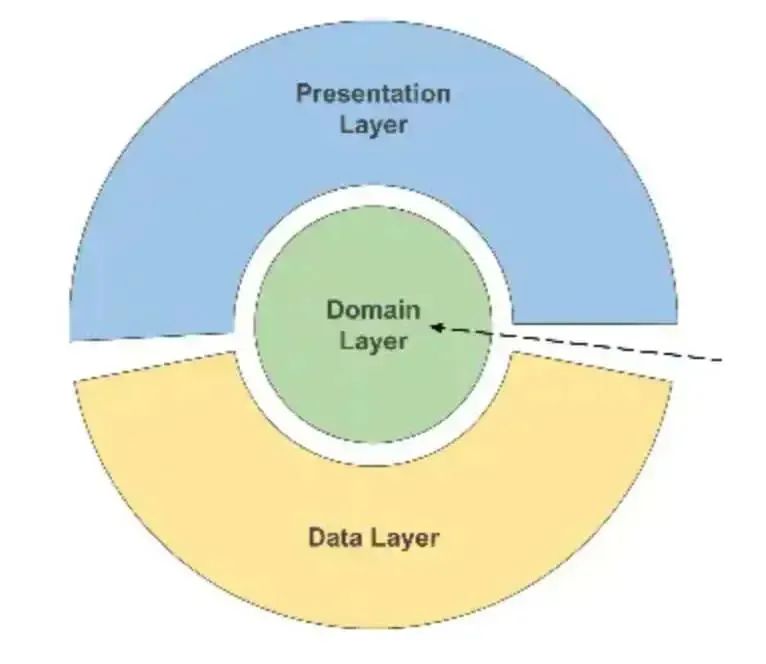
分层设计将软件划分成若干层,每一层只解决一部分问题,通过所有层的协作来完成整体目标。一个复杂问题通过分解成一个个系统子问题,这样就有效的降低了每个子问题的规模与复杂度。
分层设计带来的好处:
降低了系统软件的复杂度,将一个复杂问题通过分解,分而治之
功能的复用和封装
计算机语言的发展
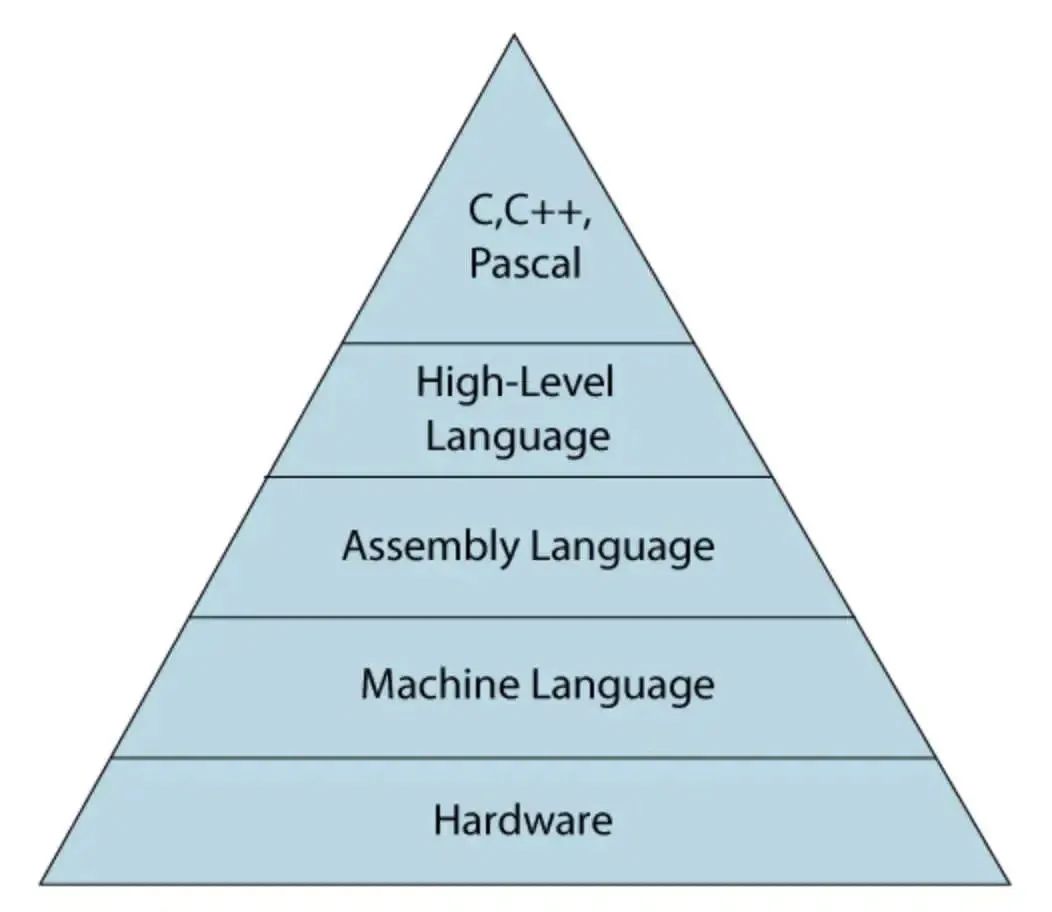
机器语言
早期,软件开发是机器语言,直接用二进制0和1表示机器可以识别的指令和数据,看起来像这样:
0010000100100011
这就是计算机CPU唯一可以理解的语言。对人类来说,二进制的程序是不可读的。
汇编语言
为了解决语言可读性的问题,汇编程序诞生了。汇编程序是人类可读的机器代码。它又被称为“符号语言”,使用助记符来代替机器的操作码。
汇编语言是二进制的文本形式,与CPU的指令是一一对应的关系。而我们不同的CPU体系结构(比如PC的 X86、嵌入式的ARM)是不同的,面向机器的语言带来的问题就是:对于不同的CPU体系架构,就需要不同的汇编语言。
高级语言
为了解决语言对机器的无关性,高级语言诞生了。一条高级语言通常由若干条机器语言实现的,并且不具有对应性。
高级语言让开发者不需要关注底层CPU体系结构与指令,只关注业务即可。
计算机语言的发展就是不断的抽象,只有通过抽象,将一个复杂的的系统变成一层层的接口集合,让我们每次只需要考虑关注当前层集合内的逻辑,而不用去考虑当前层次以上或者以下的复杂度,才有可能让我们从复杂系统中解放出来,逐步理解以及构造一个复杂系统。
Linux内核
内核功能层与内核硬件层
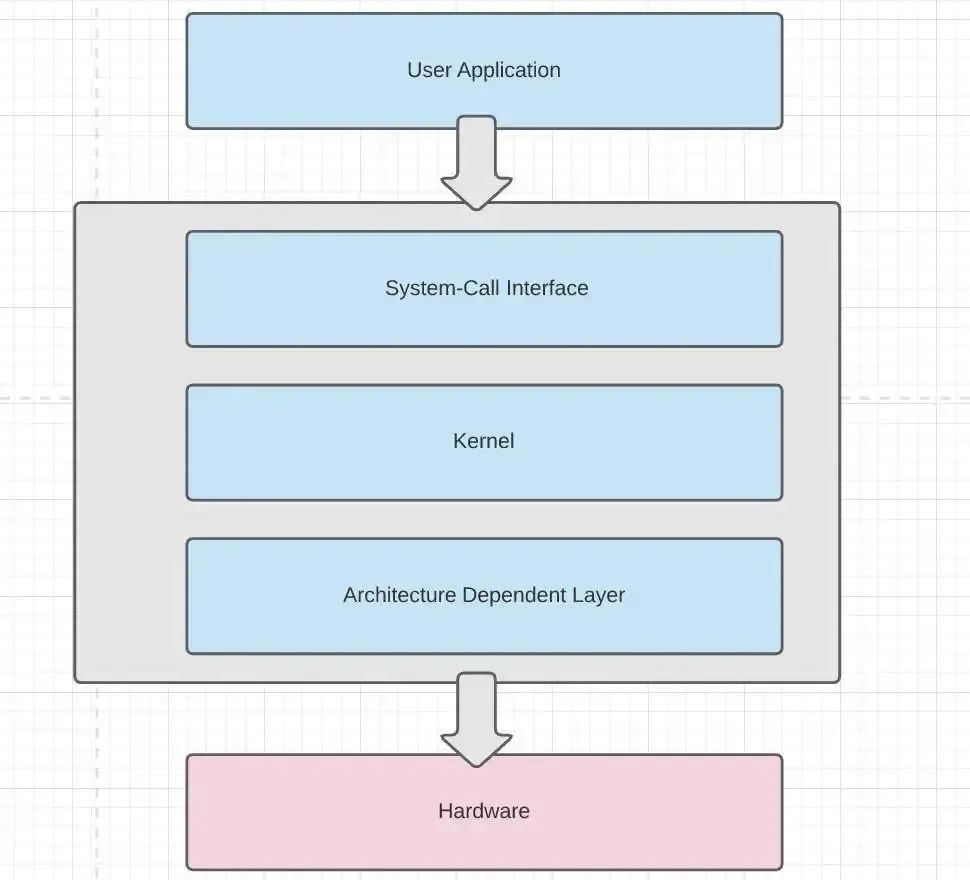
操作系统内核,可以简化理解成三大层:
内核接口层:向上对用户态应用程序提供一套接口子集,开发者使用的系统调用APIs。
内核功能层:这一层完成各种实际的功能,我们知道OS主要负责资源管理、内存、进程这些资源,物理内存如何申请、释放,进程如何调度。具体来说进程管理、内存管理、中断管理、设备管理。
内核硬件层:分离硬件的相关性,我们知道一个OS可以运行不同的指令集,也就是运行在不同的硬件平台。
不管是ARM体系结构,还是X86,选择一个进程调度的算法是可以相同的,需要改变的进程切换相关代码,因为不同的硬件平台的上下文是不同的,CPU的寄存器也不同。这时候最好的设计是分层,当操作系统运行在不同的硬件平台时,就只需要修改硬件平台相关层代码,实现操作系统的高可移植性。
操作系统有两个关键设计:
内核接口层区分用户态与内核态,来保护硬件资源受限访问。
内核硬件层分离多种硬件平台相关性。这种分层的架构,极大提升了系统的稳定性和扩展性。
MMU抽象层
操作系统负责管理物理内存,而用户进程使用虚拟内存。操作系统呈现给用户进程的是连续的虚拟空间,但不一定是连续的物理空间。因为物理内存被整个OS共享。
什么是MMU呢?它是硬件,即内存管理单元,它对CPU发出的访存地址进行映射与检查,可以让处理器发出的访存地址访问不同的物理内存单元。
如果将计算机上有限的物理内存分配给多个应用程序使用,如果让应用程序直接访问物理内存,如果没有MMU这层抽象呢?带来的问题是每个应用程序地址空间不隔离,内存使用率低,程序运行地址也无法固定。
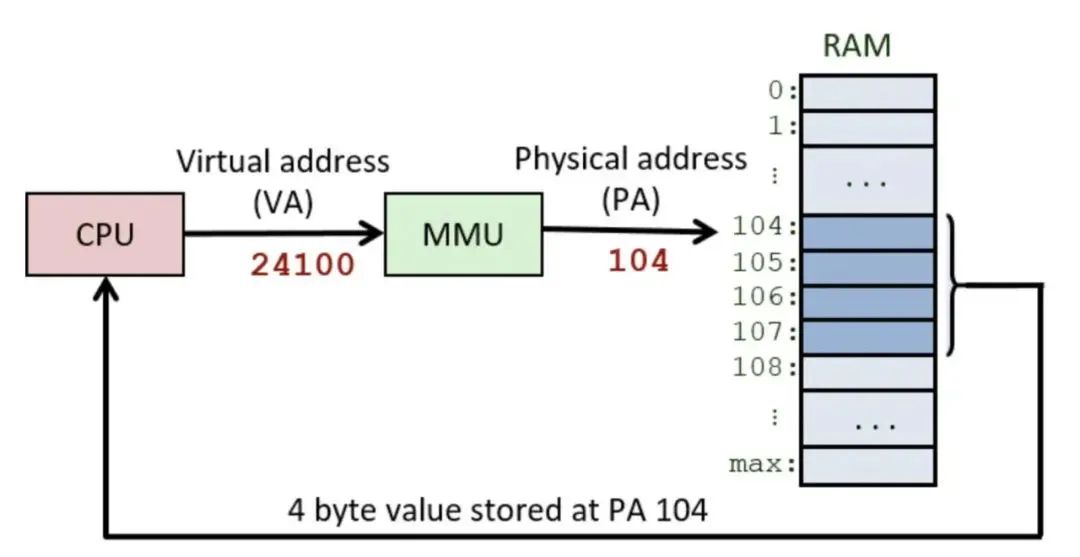
解决的问题:虚拟内存VA与物理内存PA的映射——通过在CPU与内存之间加入MMU抽象层,让CPU在运行指令时发出的VA虚拟地址通过 MMU 转换后变成PA物理地址,然后再去访问物理内存。
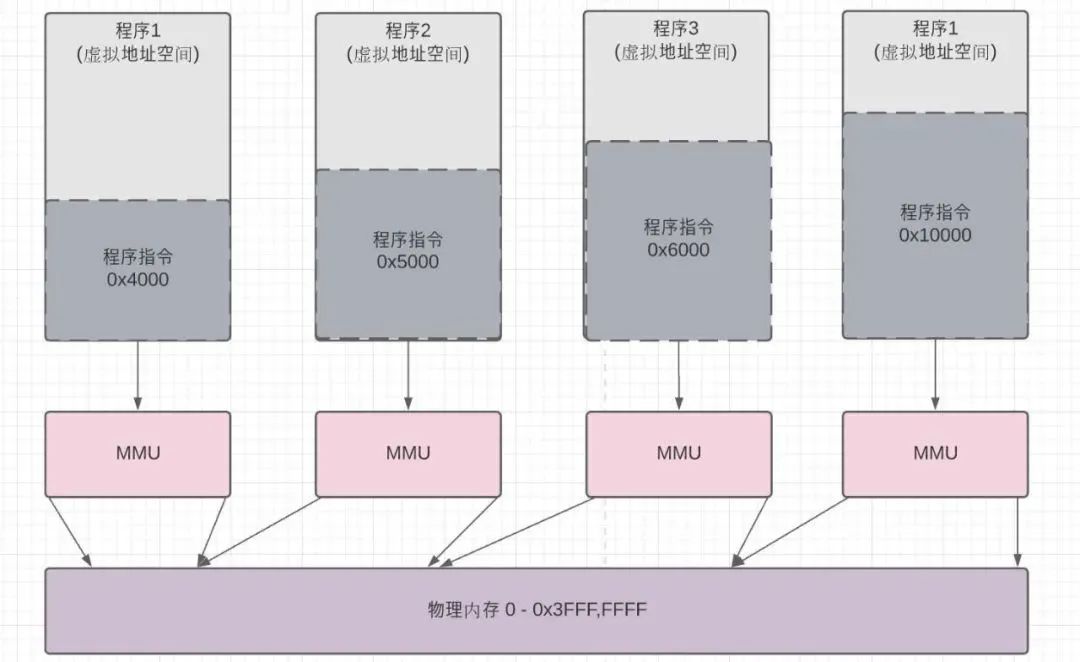
MMU引入带来的好处:
权限控制。可以对一些虚拟地址进行访问控制,比较代码段为只读,用户程序代可写。
提升内存使用率:物理内存按需申请。fork子进程的对应的物理空间是能过写时复制才进行真正的物理内存分配。
不同进程之间可以使用相同的虚拟内存地址空间,而进程的物理内存又可以隔离。
系统运行多个进程,所分配的内存之和可以大于实际物理内存大小。
这是我认为最经典、最本质、最受启发的中间抽象层的设计。
CPU与外设的通信
CPU访问外设有两种方法;
IO与内存统一编址
IO与内存的独立编址
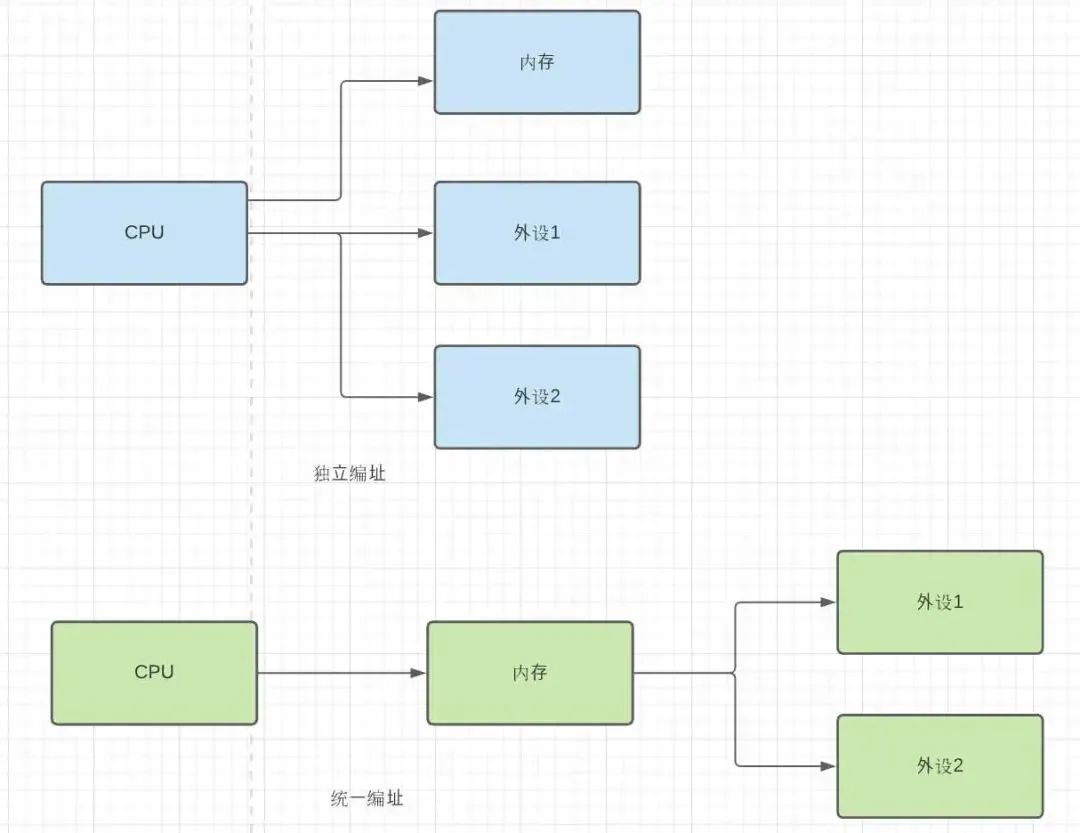
外设接口中的IO寄存器(即IO端口)与主存单元一样看待,每个端口占用一个存储单元的地址,将主存的一部分划分出来用作IO的地址空间。
把外设的寄存器当做是一个内存地址,从而CPU以类似访问内存相同的方式来操作外设。
对IO外设的端口映射到一个物理内存单元地址,在CPU与外设之间的“内存”抽象层,带来好处是访问内存一样去访问外设。
小结
Linux中的内核硬件层设计、MMU、CPU与IO外设通信设计处处体现了分层/中间层的设计思想。
TCP/IP网络协议堆栈
从最底层的物理链路层层层向上封装抽象,解决了复杂的网络通信的问题。同样的,任何复杂的问题,通过分层最终总能够回归最本质、最简单。这个分层架构,对所有开发者而言,再熟悉不过,它的引入是想与后续介绍的 Netty 形成对比。这里先卖个关子,后面解开谜底。
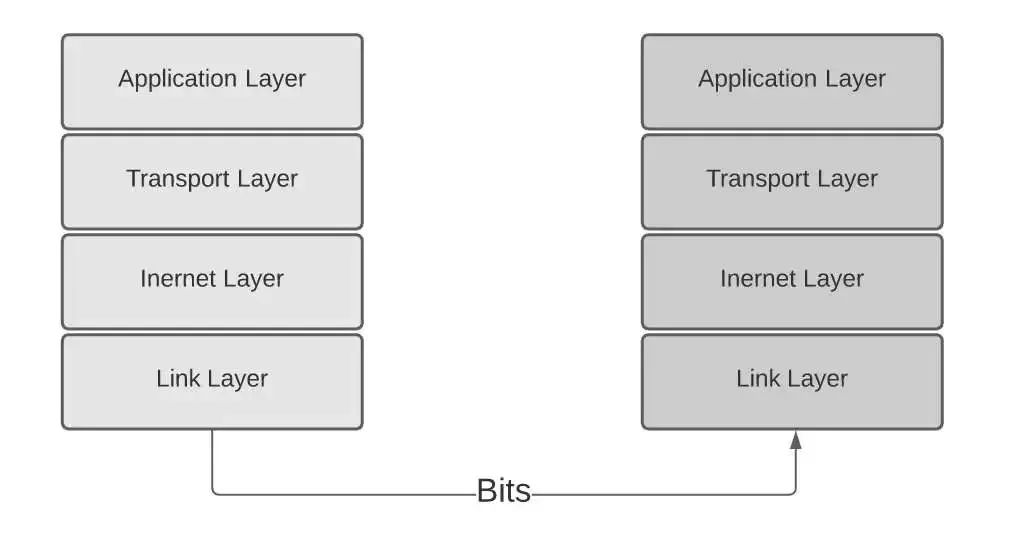
举例说明:
来自杭州西湖区某个小区的商务人士来京出差后,被确诊新冠肺炎,实施在京隔离措施,同时北京将此报告先发给浙江省,接着浙江省发给杭州市政府,然后市政府再向西湖区发送,最后到达某小区。这个发送报告过程也是分层报告思想。
DNS 中间层
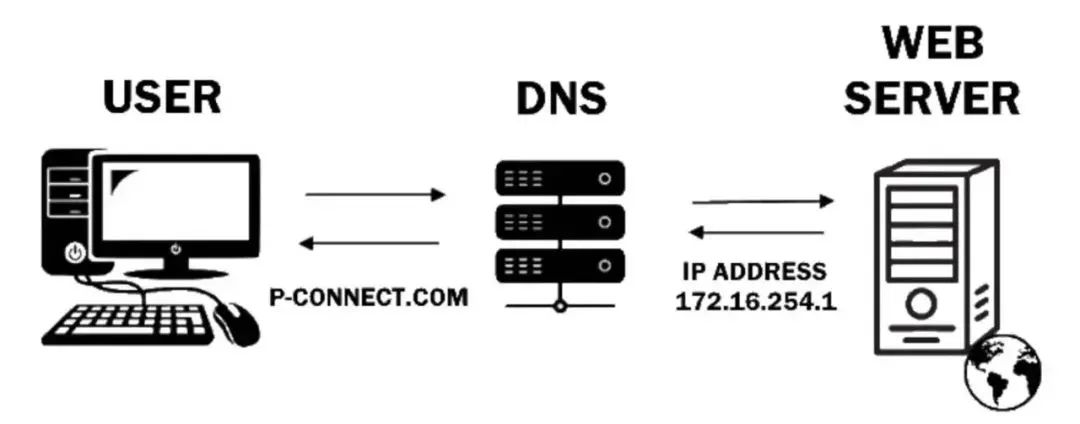
DNS(domain name system)是域名系统,是用来将主机转换为IP地址的服务。我们有至少三种方式在互联网上标识一台主机、主机名、IP地址以及MAC地址。为什么有引入DNS中间抽象层呢? 主要是主机名便于记忆,而IP地址方便于在计算机网络设备的处理,因此需要设计出一个DNS协议(中间层)来做主机名到IP地址的转换。
ARP中间层
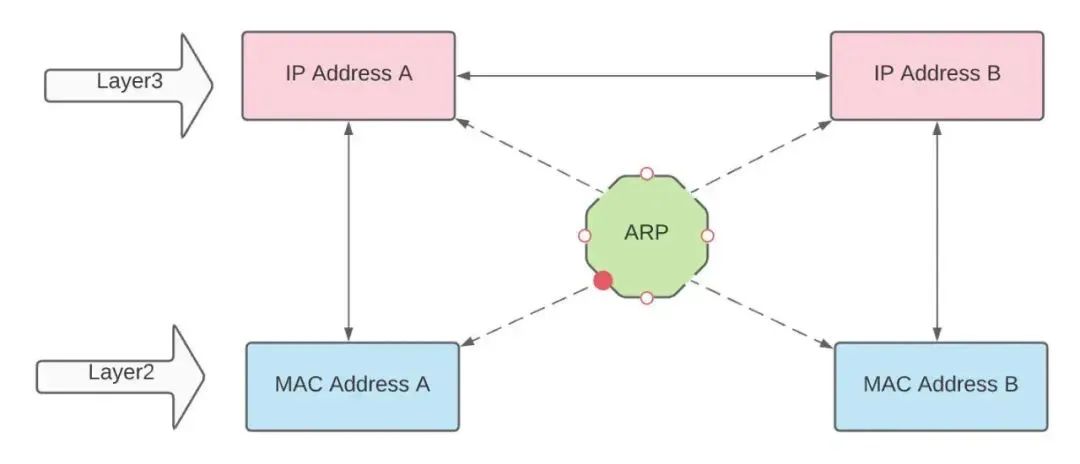
ARP(address resolution protocol)是地址解析协议,它根据IP地址来获取物理地址。上面也谈到,MAC与IP都可以用来标识一台主机。那二者区别是什么?
同一个局域网中的一台主机和另一台主机通信的时候,需要通过 MAC 地址进行定位,之后才能进行数据包的传送。
而在网络层和传输层中,主机之间是通过IP地址来定位的,对应的数据包中必须携带目标主机的IP地址, 而没有MAC地址。
因此,ARP协议(中间层)用来实现从IP到MAC地址的转换。
Netty
Netty提供了异步的,基于事件驱动的网络应用程序框架。目前分布式搜索引擎,Spark框架底层是扩展使用Netty框架。Netty本身的架构理解有些曲线,为了讲清楚,我还是希望循序渐进方式,通过它的发展历史来一步步介绍。先铺垫再介绍,大家需要一些耐心。
传统阻塞IO服务模型
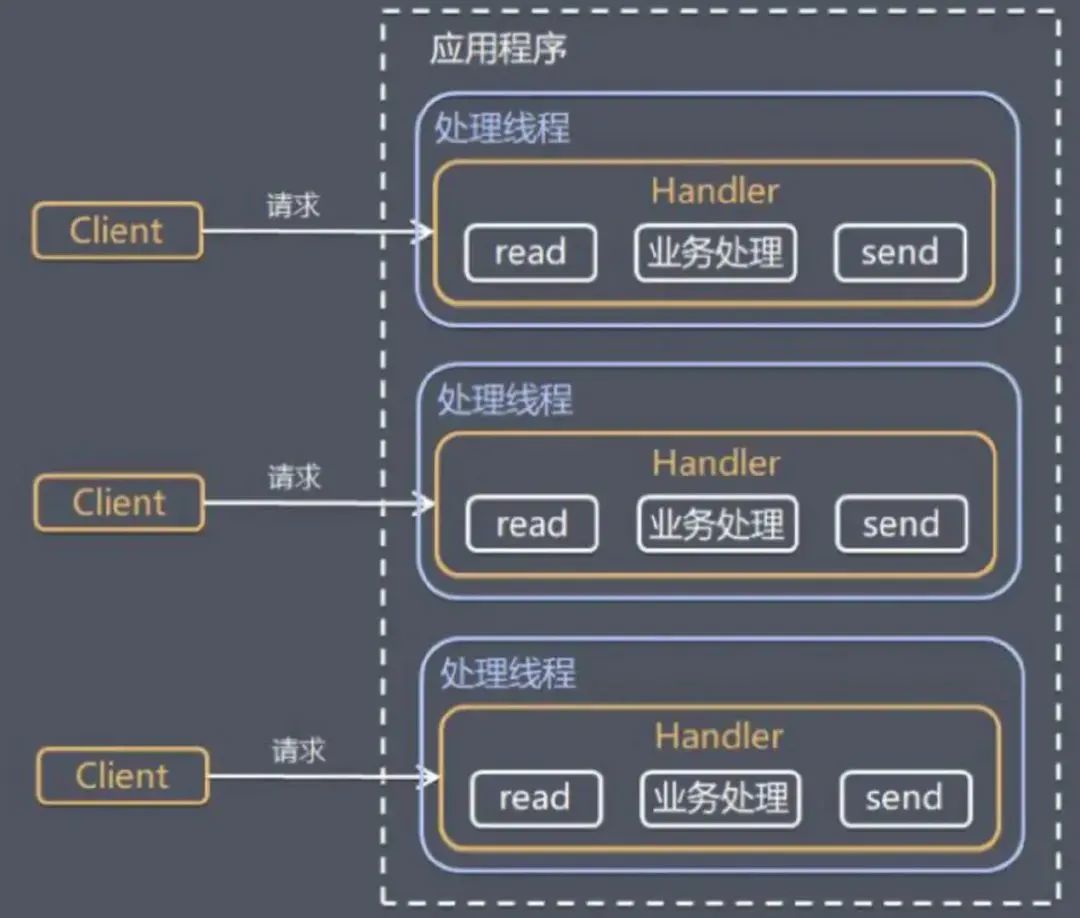
思路:
采用阻塞IO模式获取输入数据
每个连接都需要独立的线程完成数据的输入,业务的处理和数据返回
问题:
当并发数很大时,就会创建大量的线程,占用了很大的系统资源。
连接创建后,如果当前线程没有数据可读,这个线程会阻塞在read方法上,造成资源浪费。
单Reactor单线程
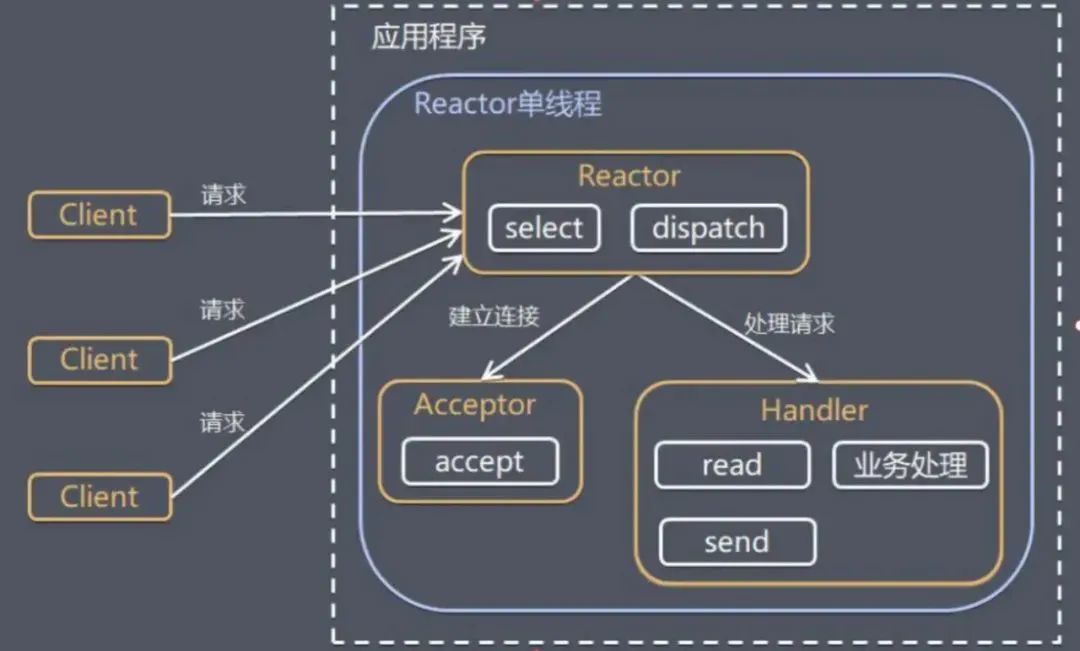
思路:
通过引入selector事件选择器来监听多路连接的请求。
Reactor对象通过selector监控客户端请求事件后,通过Dispatch进行分发。
如果建立连接请求事件,则由 Acceptor负责建立一个连接,然后创建一个Handler对象处理连接完成后的业务处理。
问题:
模型简单,没有多线程,资源竞争的问题。所以工作在一个线程完成。
性能问题,一个线程,无法发挥多核CPU的性能。
可靠性问题,线程crash,会导致整个系统不可用。
主从Reactor多线程
主React处理所有socket连接事件的监听和响应,而从React处理所有socket的读写事件的监听与响应。主从React都在多线程中运行。
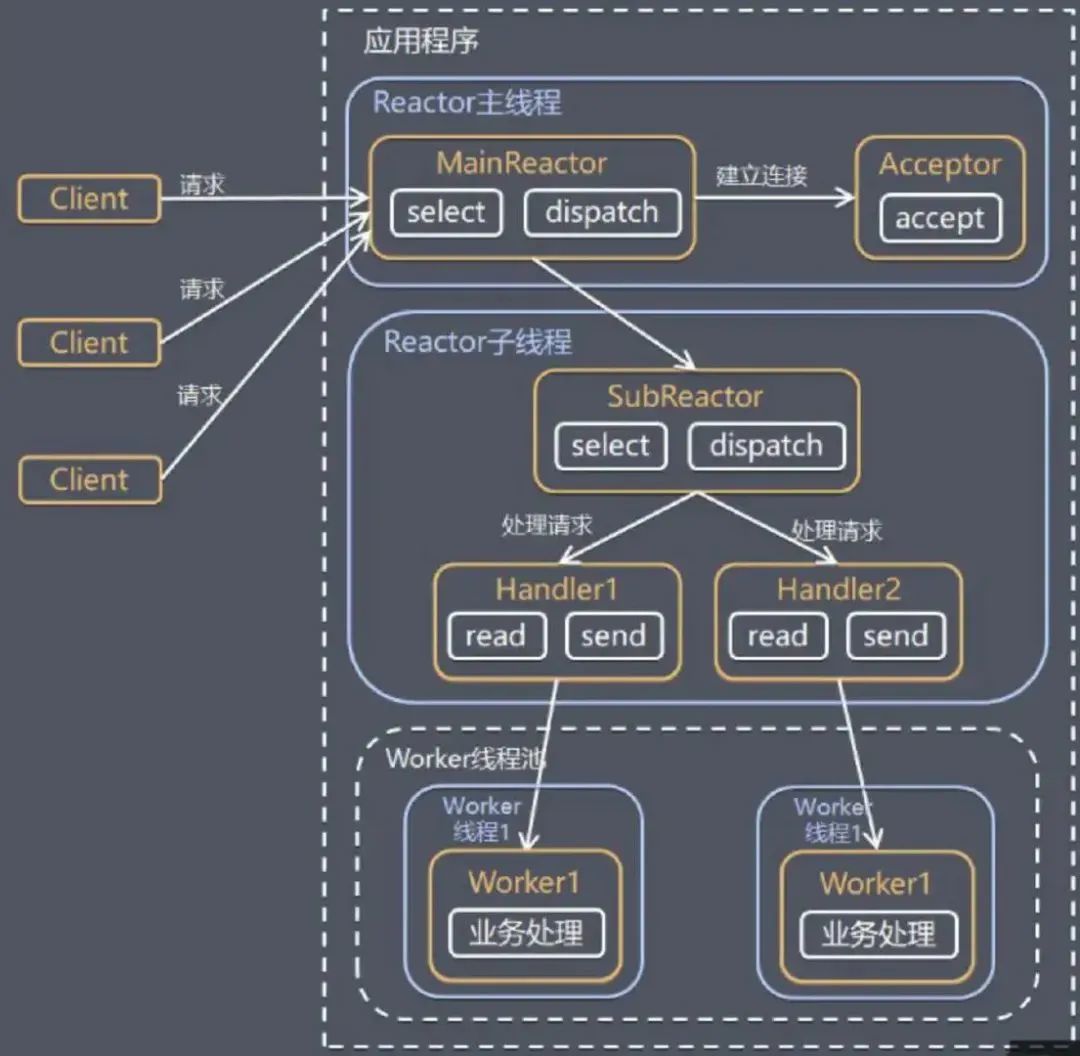
Netty模型
Netty主要基于主从Reactor多线程模型发展出来的。
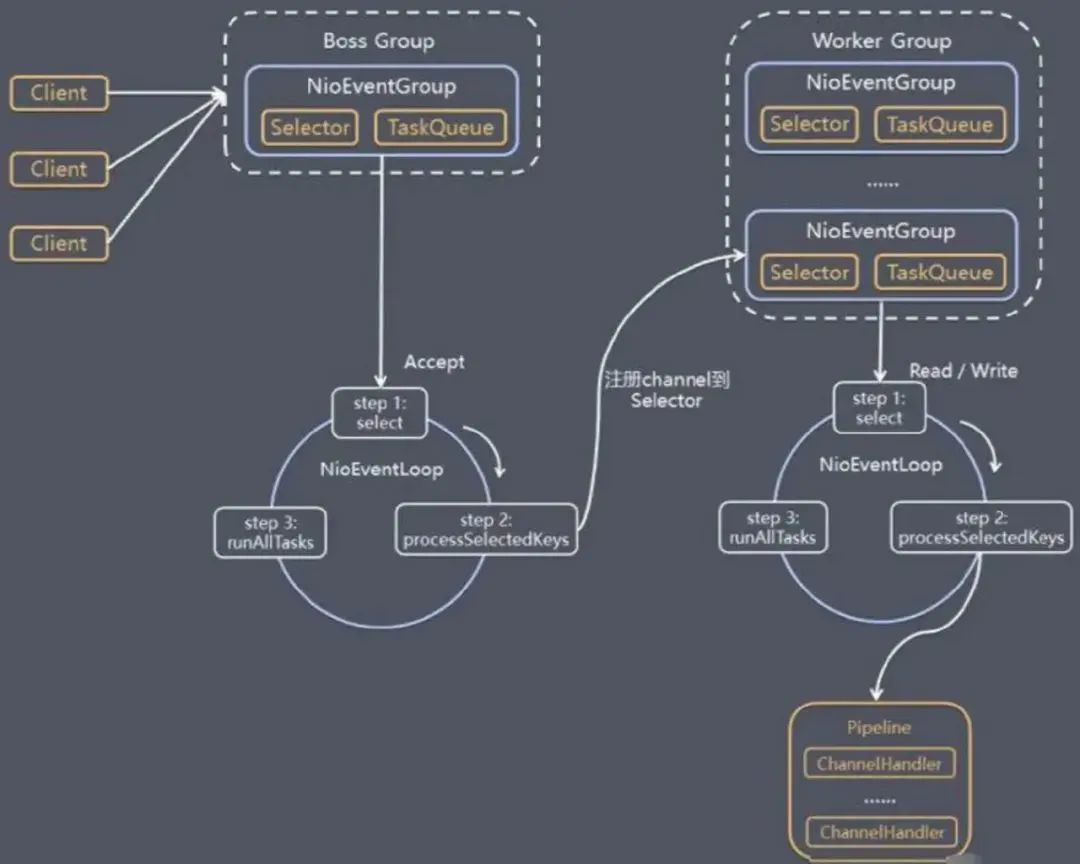
Netty逻辑架构
前面Netty的发展阶段都是铺垫,Nettty逻辑架构为典型网络分层架构设计,从下到上分别为网络通信层、事件调度层、服务编排层。
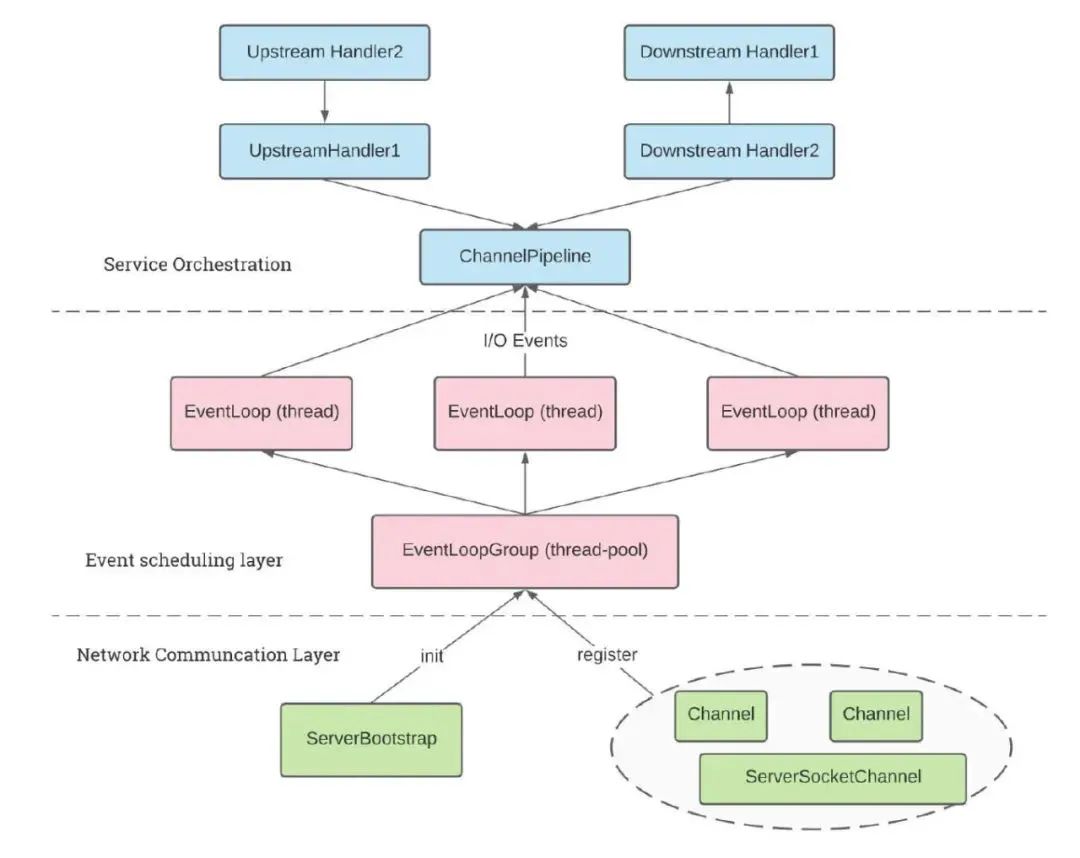
网络通信层:它执行网络I/O操作,核心组件包含BootStrap、ServerBootStrap、Channel。——Channel通道,提供了基础的API用于操作网络IO,比如bind、connect、read、write、flush等等。它以JDK NIO Channel为基础,提供了更高层次的抽象,同时屏蔽了底层Socket的复杂性。Channel有多种状态,比如连接建立、数据读写、连接断开。随着状态的变化,Channel处于不同的生命周期,背后绑定相应的事件回调函数。
事件调度层:它的核心组件包含 EventLoopGroup、EventLoop。——EventLoop本质是一个线程池,主要负责接收Socket I/O请求,并分配事件循环器来处理连接生命周期中所发生的各种事件。
服务编排层:它的职责实现网络事件的动态编排和有序传播——ChannelPipeline 基于责任链模式,方便业务逻辑的拦截和扩展;本质上它是一个双向链表将不同的 ChannelHandler链接在一块,当I/O读写事件发生时,会依次调用 ChannelHandler对Channel(Socket) 读取的数据进行处理。
ChannelPipeline私有协议栈vs.TCP/IP协议栈

前面铺垫这么久,就是为了自然过渡到上面的图,请务必与TCP/IP协议栈进行对比。
socket。read经过TCP/IP协议栈后,进入netty的网络通信层,事件调度层,最后来到服务编排层。而服务编排层的channelPipeline的设计也是一个upstream/downstream的stack,一进一出的二个pipeline。负责处理流入/流出的数据包。
上面的stack就非常类似TCP/IP协议栈。根据公司组织的需要可以定制分层的私有协议栈,比如从authentication-handler、message-validation-handler、message-encode-handler、message-decoder-handler。
微服务分层
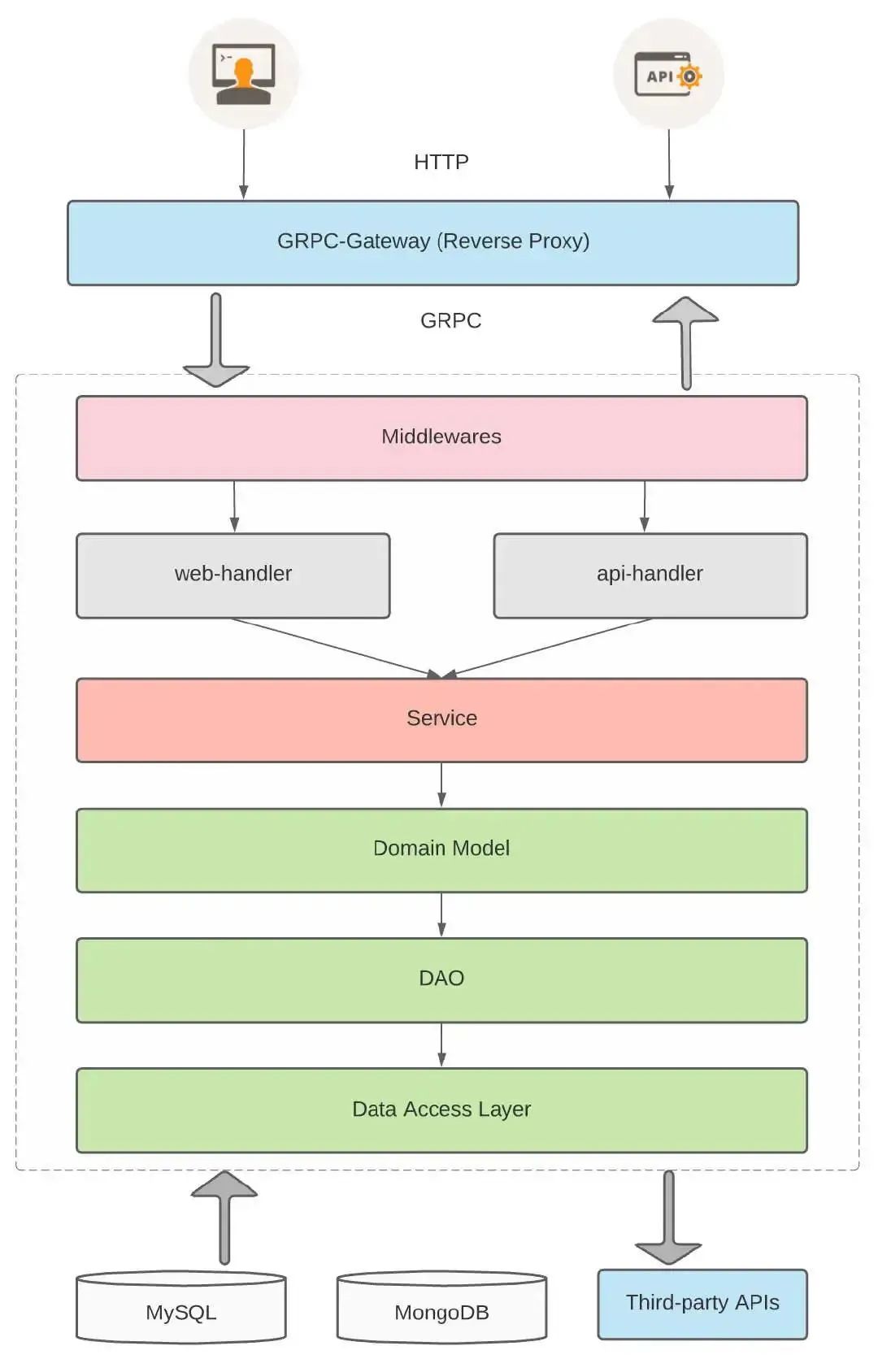
grpc-gateway——它是一个开源框架,读取protobuf接口定义并生成一个反向代理服务器,此服务器一步将 restful http API转换成grpc服务.
middleware——实现鉴权功能, 比如哪些URL需要权限检验
handler通用处理层——参数检验: handler层负责执行与客户端约定参数的检验, 检验通过后再组装成后端服务需要的数据结构发往后端;接口聚合/组合服务: handler层可以根据业务需要, 调用多个后端服务的endpoint 来组合实现一个新的接口,同时将下层返回的数据进行聚合处理.
service/model业务逻辑层——对业务逻辑的封装, 负责将多个DAO数据结构转换和封装成一个有逻辑意义的模型;可以引入缓存策略,优化数据存取效率.
DAO层——数据访问层,主要负责操作DB中某张表并映射到内存中某个DAO 模型;与数据表结构一一对应,通过DAO内存模型向上层传递数据源的对象.
数据访问层DAL——对底层的数据源做统一的抽象, 屏蔽数据库.如果没有DAL的存在,那么几乎所有的业务逻辑层都会去与具体的数据库存储强挷定.耦合性就很高.
还有一个补充点:
业务逻辑层中的服务在实际场景中不可避免的会出现互相调用的场景,这种情况往往需要将耦合/公共的功能进行下沉,比如数据请求下沉为数据访问层服务,而业务下沉为稳定的通用业务服务,被其它服务稳定依赖。
Rails On Rack
熟悉Ruby On Rails Web应用框架的开发者,肯定知道Rack是如何成为应用容器(webserver)和应用框架之间的桥梁的。
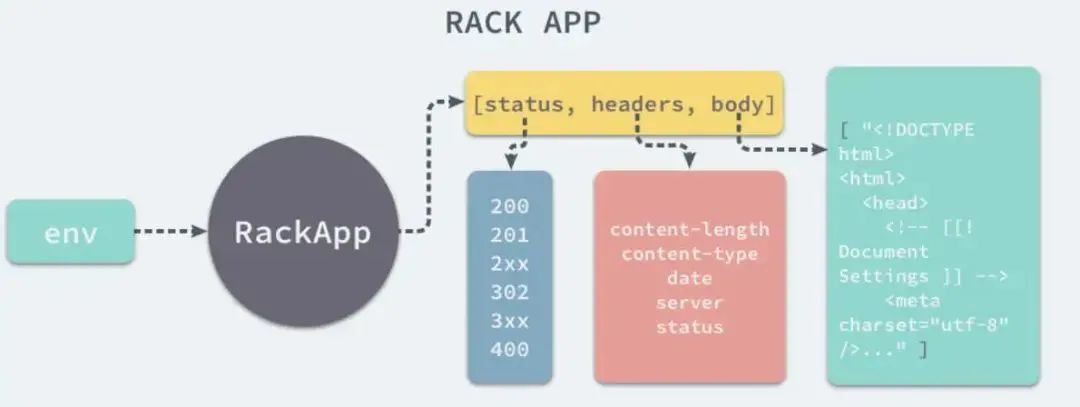
Rack在webserver和应用框架之间提供了一套最小的API接口,如果webserver都遵循Rack提供的这套规则,那么所有的框架都能通过协议任意地改变底层使用webserver。
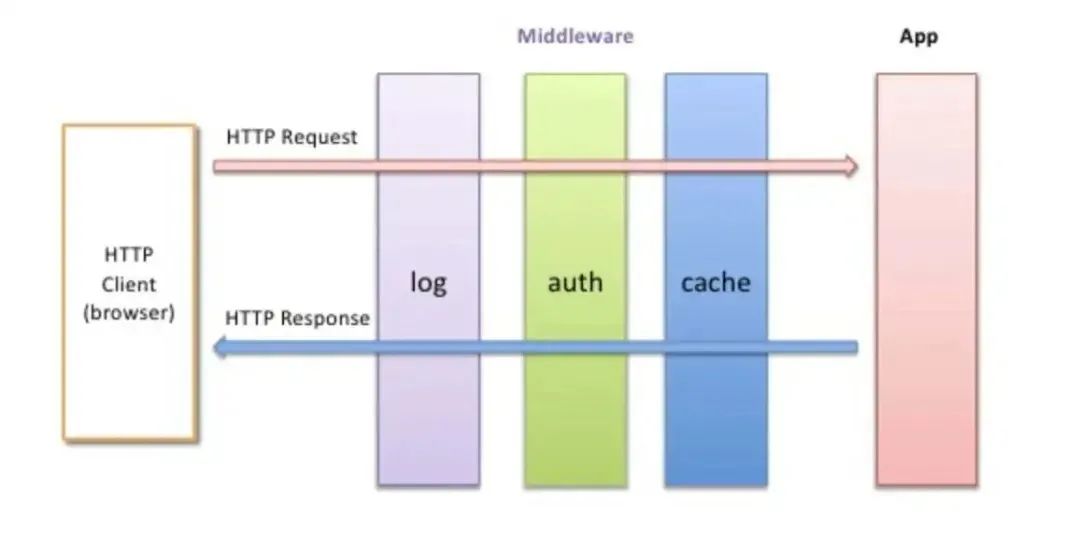
Rack分层设计非常类似Decorate Pattern或者Chain of Responsibility Pattern。
总结
本文作者结合自身工作经验, 总结一些典型分层设计案例
计算机语言的发展
Linux内核设计(内核功能层与内核硬件层,MMU抽象层,CPU与外设的通信)
TCP/IP网络协议堆栈(DNS和ARP协议)
Netty框架发展以及分层私有协议栈分析
微服务分层
应用框架 Rails On Rack
这些案例充分说明了计算机系统本身就是通过一层一层抽象构造出来的。
硬件方面是从一个个小的晶体管,抽象成一个个门电路,再到CPU器件,最后抽象组成计算机。
软件设计也是一个层次一个层次功能完善叠加的,无论是自顶向下还是自底向上。
本篇作者
杨敏
FreeWheel 首席工程师
负责 SFX 团队的整体工作。目前从事服务化框架、容器化平台相关。关注与感兴趣的技术主要有 Python/Java 虚拟机、Golang、K8s、分布式数据库、分布式搜索引擎 ElasticSearch。

听说,点完下面4个按钮
就不会碰到bug了!
















 8622
8622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









