







在工业物联网以及互联网等场景中,常常会产生大量的带时间标签的数据,被称为时间序列数据。这些数据的典型特点为:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(实时监测系统有成千上万的监测点,监测点每秒钟都产生数据,每天轻松产生几十 GB 甚至更多的数据量)。例如,生产制造、电力、化工等行业,需要实时监测,检查并分析海量设备所采集和产生的数据;车联网以及电动汽车也会产生海量数据用于行车安全监控,车辆设备状态监控;互联网应用运行状况的监控、实时点击流数据的收集以及分析等等。
时间序列数据的这些特点,使得传统的关系型数据库无法提供高效存储、快速扩展以及快速处理的能力。时间序列数据库因此应运而生,它采用特殊的存储方式,专门针对时间序列化数据做了优化,极大提高了时间相关数据的处理能力,相对于关系型数据库,它的存储空间减半,查询速度得到显著提高。
Amazon Timestream是一种快速、可扩展的全托管、无服务器时间序列数据库服务,借助Amazon Timestream,您可以每天轻松存储和分析数万亿个事件。其主要优势为:
高性能、低成本:相比传统关系型数据库,其速度提升了1000倍,而成本仅为十分之一。
无服务器:自动缩放以调整容量和性能,使得您只需要专注于应用程序的构建,而无需管理底层基础设施。
生命周期管理:根据您预先设置好的生命周期策略,Amazon Timestream可以自动实现将近期数据保留在内存层,而将历史数据移动到成本优化的磁性存储层,帮助您节省管理时序数据库的时间以及成本。
简单高效查询:无需在查询中显式指定数据是保存在内存中还是成本优化层中,Amazon Timestream的查询引擎可用于统一的访问和分析近期数据和历史数据。
此文将利用一个车联网行车监控上报时序数据的模型,探讨Amazon Timestream如何通过流式方法注入行车数据以及在不同数据量下的的扩展性以及查询性能表现。结构上分为数据模型、Amazon Timestream端到端测试、性能表现三个部分,如果希望直接看性能评测结果,可以直接跳到性能表现当中查看结论。
数据模型
场景介绍
我们选取一个车联网行车监控的典型场景,汽车实时监测数据会以时序数据的形式,流式的上传并存储到Amazon Timestream中,由不同的数据使用者、不同的应用程序做不同类型的SQL查询。
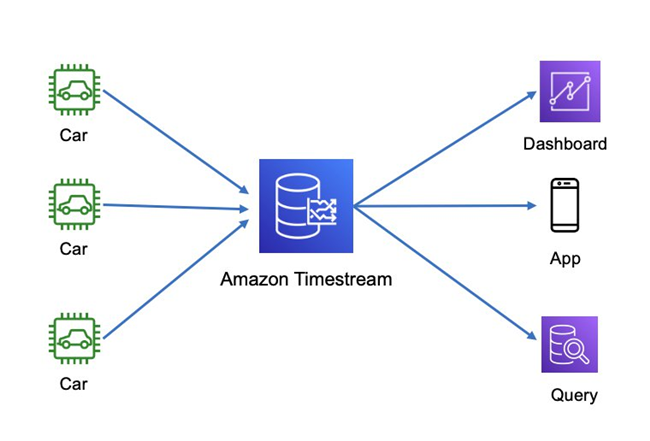
使用Amazon Timestream,可以有效解决车联网应用的若干痛点。
数据无法可靠地收集或传输,并且数据之间存在间隙或者乱序。
需要对多个数据系列执行不同的分析,这些数据系列无法以相同的速率(频率)生成数据或以相同的速率生成数据但不同步。
数据的时间心跳粒度可能从秒级到分钟,小时不等。
需要计算并考虑数据在不同时间段内的统计值,例如平均值,标准偏差,百分位数和排名。
需要以可变的粒度级别检索数据,例如特定分析时间轴中的缩放:降采样和随机采样的要求。
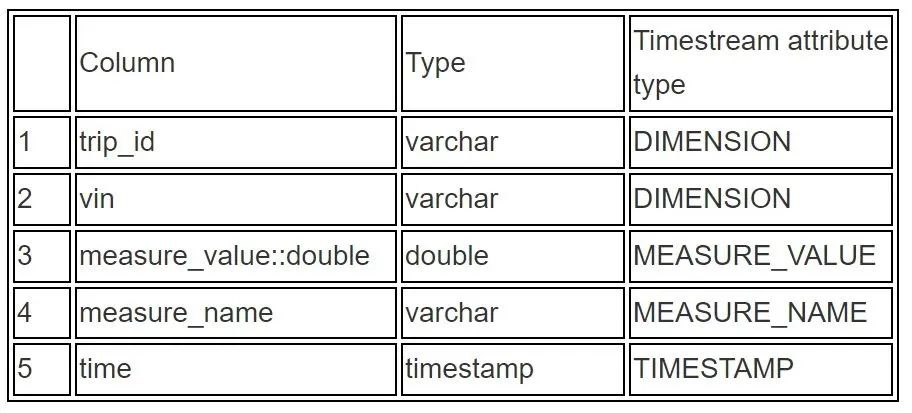
每辆车的每次上报,都包含时间戳,设备基本属性(ID等信息),以及不同维度的属性值(温度,速度等)。数据 Schema 如下表所示。
data = {
"vin": vin, # 车架号,VIN = 'vin-' + str(rand_n(14))
"event_time": str(datetime.datetime.now()), # 时间戳 timestamp
"trip_id": trip_id, # 行程标识
"PressureLevel": random.choice(['LOW', 'NORMAL', 'HIGH']), # 压力值水平
"Systolic": random.randint(50, 80), # 某参数值
"Diastolic": random.randint(30, 50), # 某参数值
"temp": random.randint(0, 1000), # 温度
"powertrainState": DOUBLE, # 动力总成状态
"ignition_state": DOUBLE, # 点火状态
"bms_soc2":DOUBLE, # 排放值
"odo":DOUBLE, # 里程数
"speed":DOUBLE, # 速度数
"gear":DOUBLE, # 变速器
"engine_rpm":DOUBLE # 发动机转速
}请左右滑动了解更多细节
Amazon Timestream建模
在建模之前,我们先了解一下Amazon Timestream中的一些基本概念。
Time series时间序列:在一段时间范围内,记录的一个或者多个数据点(也就是 records)序列。比如一个短时间的股价,一个短时间的CPU或内存利用率,以及一段时间Iot传感器的温度压力值等。
Record记录: 在时间序列当中的一个数据点。
Dimension: 时间序列当中的一个mete-data属性值。包含 dimension 的key值以及实际值。比如对于Iot传感器,常见的 dimension name为设备ID,dimension value为12345。
Measure:record当中实际被测量的值。比如一个设备的实际温度或者湿度。Measure包含measure names(相当于为key值)以及 measure values。
Timestamp时间戳: 表明测量值是在哪个时间点被测量的。
Table:存储时间序列的表
Database:数据库
根据定义,我们对上述schema当中的 key 做一个分类,将反应设备基本情况类的信息归类到DIMENSION里,将实际需要上报的值归类为MEASURE类,建模如下:
Amazon Timestream 测试
测试目的
为了验证Amazon Timestream数据库可以支持车联网实时数据监控和查询,我们设计了针对Amazon Timestream的测试场景,其中涉及端到端集成和性能测试。测试期望验证下列场景。
数据可以通过流式注入的方式写入Amazon Timestream数据库。
数据注入速率不小于每秒1000条数据,每条数据Playload大致在8KB左右。
数据按照百万级、千万级和亿级分阶段测试,数据保留时间为1周。超过此时间段的数据将移至数据湖中保存,数据湖数据处理不在本文讨论访问。
为了良好的成本效率,测试不同存储分层下的Amazon Timestream 的性能表现,保证数据可以平滑的在不同层级的存储中转换。
测试在不同存储分层下时间窗口内查询,聚合,跨表查询等性能。
架构说明
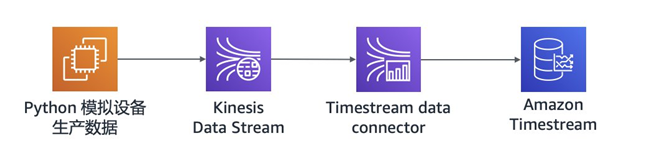
在此次压测中,我们用python程序模拟物联网设备产生数据的过程,数据将实时写入到流式存储介质Amazon Kinesis Data Stream当中,通过由 Flink 构建的Amazon Timestream data connector,实时读取 kinesis 里的数据,并写入到Amazon Timestream中。
Amazon Kinesis Data Stream:
https://aws.amazon.com/cn/kinesis/data-streams/
Amazon Timestream data connector:
https://docs.aws.amazon.com/zh_cn/timestream/latest/developerguide/ApacheFlink.html
压测步骤
1. 在此处下载此次压缩所需要的代码,并按照README的步骤进行必要软件的下载、安装以及运行。
此处:
https://github.com/nwcd-samples/timestream-scale-performance
2. 启动Amazon Timestream Flink Connector (在README当中也包含此步骤)。
Amazon Timestream Flink Connector:
https://github.com/nwcd-samples/timestream-scale-performance/tree/main/flink_connector
cd /home/ec2-user/timestream/amazon-timestream-tools/integrations/flink_connector
mvn clean compile
mvn exec:java -Dexec.mainClass="com.amazonaws.services.kinesisanalytics.StreamingJob" -Dexec.args="--InputStreamName TimestreamTestStream --Region us-east-1 --TimestreamDbName kdaflink --TimestreamTableName kinesis-6yi"
mvn exec:java -Dexec.mainClass="com.amazonaws.services.kinesisanalytics.StreamingJob" -Dexec.args="--InputStreamName TimestreamTestStream --Region us-east-1 --TimestreamDbName kdaflink --TimestreamTableName kinesis-6yi --TimestreamIngestBatchSize 75"请左右滑动了解更多细节
1. 在另一个terminal 或者另一台服务器启动执行生产数据的 python 程序(在 README 当中也包含此步骤)。
# cd /home/ec2-user/timestream/amazon-timestream-tools/tools/kinesis_ingestor
python3 timestream_kinesis_data_gen_blog.py --stream TimestreamTestStream --region us-east-1请左右滑动了解更多细节
2. 此时,如无错误,Amazon Timestream 将持续被写入数据。可以在 kinesis 的监控,Amazon Timestream 监控中,观察写入延迟等指标。也可以在 Amazon Timestream 中,通过 count 的方式查询写入条数。当观测达到目标数量级时,停止写入。
3. 如果希望提高并行写入速度,可以通过增大producer脚本(timestream_kinesis_data_gen_blog.py)的并行来解决,但此时应注意 kinesis 的写入速度是否达到瓶颈。kinesis 单个 shard 有1MB/s 或者 1000 条/s 的写入限制,如到达瓶颈,请增大 kinesis 的 shard 数量。
4. 在写入完成后,在确保测试服务器已经配置了Amazon CLI后,运行query_test.py脚本,根据自己的需要,更改替换 profile_name (默认为default),DATABASE_NAME,TABLE_NAME,RIGHT_TABLE_NAME (做join操作) ,QUERY_REPEAT(运行query的次数) 等参数。此脚本将记录在不同的SQL查询下,每次以及平均的延迟数据。
Amazon CLI:
https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html
query_test.py:
https://github.com/nwcd-samples/timestream-scale-performance/blob/main/query_test.py
性能表现
在此次测试中,我们分别通过上述方法向Amazon Timestream不同table里写入了百万,千万,和亿级别的数据,主要监控指标有Amazon Timestream的写入延迟,Query查询速度。
写入延迟
在写入TPS在 6000 条/秒 下:
在写入TPS在 6000 条/秒下:

6亿条数据Kinesis写入的时延在 60ms – 75ms

Query 查询速度
我们分别针对百万级,千万级,和亿级的数据量做了不同 SQL 语句下的测试;并且在每个数量级下,我们做了对比测试,以对比 Amazon Timestream 内存介质和磁性介质在不同查询语句下的表现。
对应SQL 语句可在 query_test.py 中查看并做修改。
百万级 records:9547102 rows ( 950 万条)
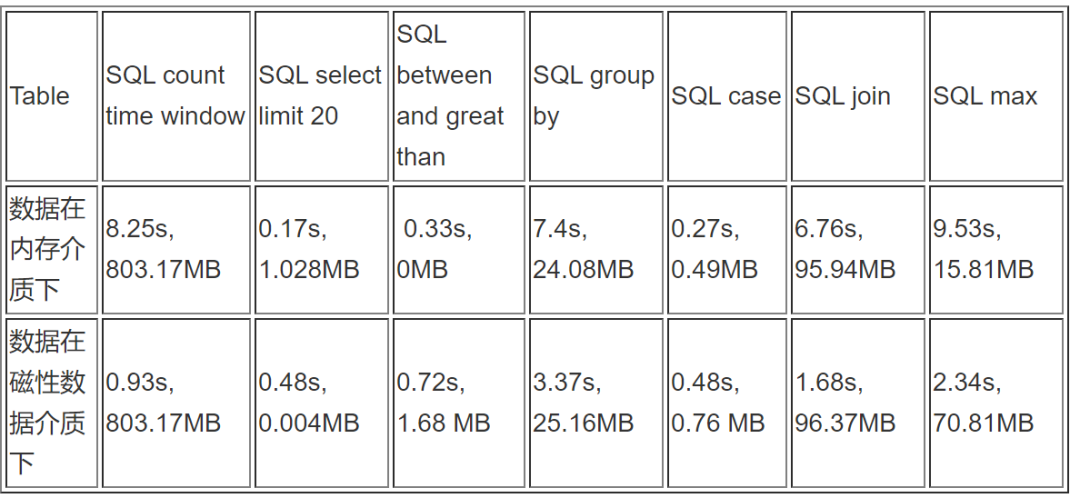
千万级 records:71602075 rows (7000 万条)
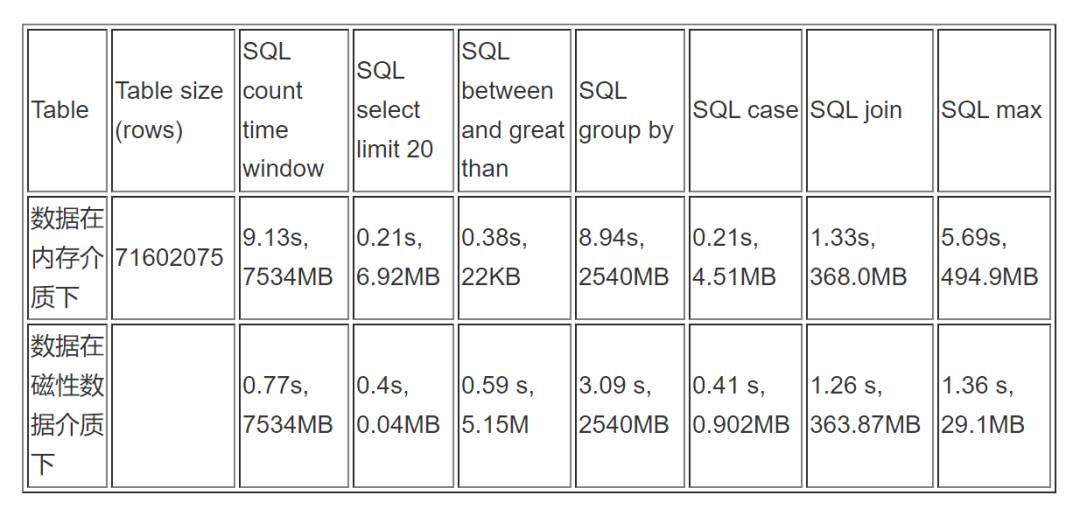
亿级 records:609769360 rows (约 6 亿条)
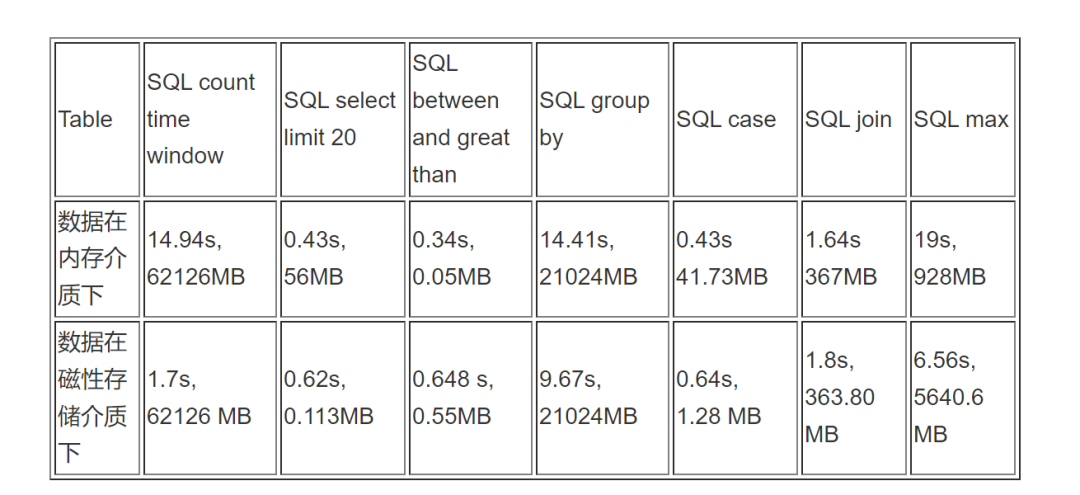
结论
通过测试数据,我们可以得到以下结论:
Amazon Timestream 可以良好的支持大规模数据输入,提供了平滑的注入性能。
Amazon Timestream 可以良好的支持大规模数据存储,并且通过不同分层,优化成本。
Amazon Timestream 可以良好的支持典型时序查询,提供了丰富的时序查询方法,并且可以在海量数据情况下提供良好的查询性能。
提升查询性能方面,我们有如下建议:
Amazon Timestream 所扫描的 data size 越大,返回速度越慢。这一点可以在每个表格中的 data size 与 response data 中得到证实。
我们建议查询时仅包含对查询必不可少的度量和维名称。
在可能的情况下,在查询的WHERE子句中包含一个时间范围。
在可能的情况下,在查询的WHERE子句中比较维度和度量时,请使用相等运算符。
使用CASE表达式执行复杂的聚合,而不是多次从同一张表中进行选择。
仅在查询的GROUP BY子句中使用必要的列。
如果使用ORDER BY子句查看前N个值或后N个值,请使用LIMIT子句以提升查询性能
我们建议遵循其他最佳实践指南的建议,以优化工作负载的规模和性能。
对于一些查询性的 SQL 语句,如 between and, 在内存当中的查询速度会更快;但对于一些分析类的服务,如 group by,在磁性存储介质下会有更好的效果。 这是因为:内存存储专为快速的时间点查询进行了优化,而磁性存储官方文档:则为快速的分析查询进行了优化。此结论在 Amazon Timestream官方文档当中可以得到理论支持。
最佳实践指南:
https://docs.aws.amazon.com/timestream/latest/developerguide/best-practices.html
官方文档:
https://docs.aws.amazon.com/zh_cn/timestream/latest/developerguide/configuration.html
参考文档
Amazon Timestream 官方文档:
https://docs.aws.amazon.com/zh_cn/timestream/latest/developerguide/what-is-timestream.html
Amazon Timestream Blog:
https://aws.amazon.com/cn/blogs/database/deriving-real-time-insights-over-petabytes-of-time-series-data-with-amazon-timestream/
本篇作者

李天哥
亚马逊云科技解决方案架构师
负责基于亚马逊云科技的云计算方案架构咨询和设计,擅长开发,Serverless 等领域,具有丰富的解决客户实际问题的经验。

梁睿
亚马逊云科技解决方案架构师
主要负责企业级客户的上云工作,服务客户涵盖从汽车,传统生产制造,金融,酒店,航空,旅游等,擅长DevOps领域。11 年 IT 专业服务经验,历任程序开发,软件架构师、解决方案架构师。

听说,点完下面4个按钮
就不会碰到bug了!
















 8603
8603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









