







前言
需求量预测在物流行业中至关重要,在目前全球范围内供应链紧张的情况下尤为明显。物流和供应链公司(例如从事海运和空运跨境运输业务的物流公司),能够准确估计物流需求量,有助于有效管理运输网络的成本,从而降低运输费用,实现利润最大化。
机器学习模型的性能很大程度上依赖于训练数据的质量。对于物流需求量预测模型,训练数据包括历史物流量和与需求量相关的特征。例如价格、库存、销售团队人数、市场环境、假期、天气以及宏观经济都可能会影响物流需求量,可以作为模型特征。
在确定了可以用于模型训练的特征之后,业务人员可能还希望对某些特征进行调控,从而能够观察到特征对模型预测结果的影响。例如,业务人员如果看到未来某个时刻物流需求量的预测值偏低时,可以通过提前调整价格来影响物流需求量。在模型推理时,模型能够将业务人员修正过的特征摄入到模型当中,这会让用户更直观的了解这些特征会如何影响模型的预测结果。
本文讨论了如何在亚马逊云科技云上构建基于机器学习的物流需求量预测。用于训练模型的数据包括内部和外部数据。机器学习模型使用物流需求量历史数据和其他相关特征进行训练,在推理时用户可以通过对特征的微调来了解特征对模型预测结果的影响。
架构
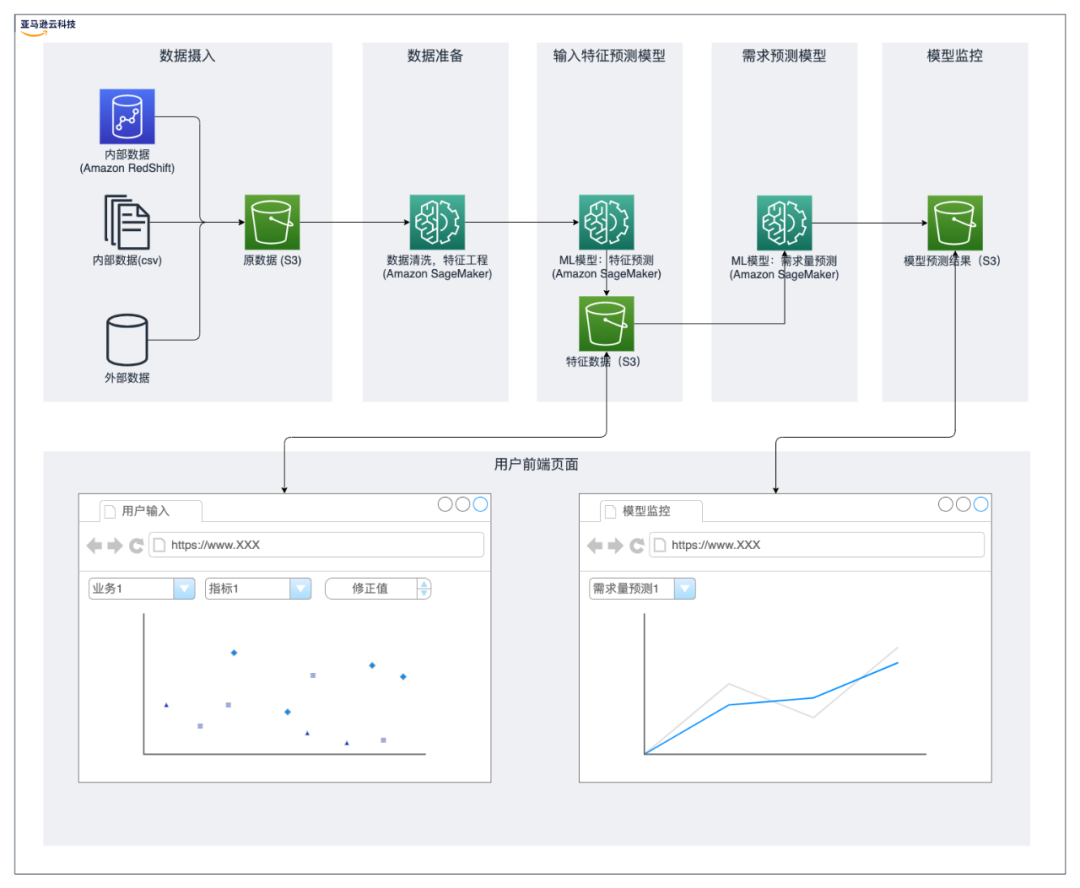
解决方案架构包括六个主要组件:
1. 数据摄入:将内部数据和外部数据摄入到 Amazon S3 中。
2. 数据准备:使用 Amazon SageMaker 进行数据清洗,特征工程。
3. 模型构建1-输入特征预测模型:先为时间序列特征构建预测模型。
4. 数据输入-用户输入:用户检查第3步输入特征的预测结果,并在需要时对特征预测模型结果进行微调。
5. 模型构建2–物流需求量预测模型:使用步骤2和步骤4中的特征构建机器学习模型。
6. 模型输出和监控:ML 模型推理的结果输出到 Amazon S3,分析师可以监控预测结果,并通过与实际物流需求量的比较来评估预测的准确性。
创建机器学习管道,实现机器学习模型的自动化。机器学习管道包括数据摄入,数据清洗,特征工程,模型训练,模型验证,模型推理。根据业务需求每月进行物流需求量预测。如果有多条航线需要进行物流需求量预测,Amazon SageMaker 可以利用机器学习管道对多条航线并行推理。
数据
高质量的数据对于任何机器学习模型都是必不可少的。对于物流需求量预测,可以利用任何可能影响最终物流需求量的相关数据来进行建模。数据的来源可能各自不同,可以分为内部数据和外部数据。
内部数据
内部数据是指由业务系统生成的数据。这些数据通常存储在数据仓库中,例如 Amazon RedShift。将这些业务指标作为机器学习的特征输入到模型当中。例如历史价格、成本、运力、库存等。
物流需求预测的结果可以保存在数据仓库中,其中包含各条航线的预测时间、航线相关属性、物流需求量预测结果等信息。对于航运公司来说,输出结果可以是海运的集装箱总需求量或者是空运货物的总重量。
外部数据
企业外部的数据源,例如天气数据、宏观经济数据、行业数据、市场数据等,都可以作为特征来帮助提高模型预测的准确性。这些因素可能对物流和运输行业产生直接或间接的影响,从而影响物流需求量。例如,中国出口集装箱运价指数,波罗的海干散物流价指数通常可以作为全球物流市场的重要指标。宏观经济数据,例如主要经济体的进出口数据,也可以作为衡量市场活跃度的指标。为了合并这些外部数据,可以使用各种 API 来摄取数据。
例如,圣路易斯联储提供的 API
(https://fred.stlouisfed.org/docs/api/fred/)来访问宏观经济数据。NOAA提供 API (https://www.ncdc.noaa.gov/cdo-web/webservices/v2) 来访问全球天气数据。
机器学习模型
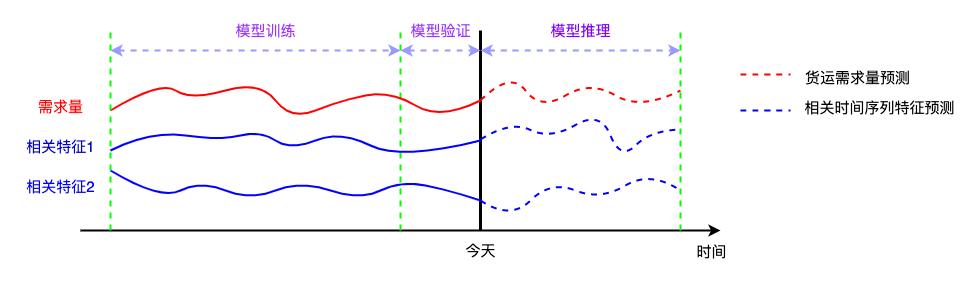
在物流需求预测中,输出是物流需求量预测值。与物流需求量相关的时间序列特征也需要预测。为了准确预测物流需求量,解决方案中需要两个机器学习模型。第一个模型是用于对输入的时间序列特征预测,包括内部和外部数据。第二个模型是使用所有特征进行最终的物流需求量预测。通过结合使用这两个模型,可以有效地捕捉时间序列趋势以及物流需求量与相应特征之间的关系。
ML 模型1 – 输入特征预测
输入特征包括内部和外部历史时间序列数据。为了对每个特征的未来进行预测,可以使用一维时间序列模型。例如 Prophet,可以建立合理的时间序列模型并进行预测。对于每个特征,用户都可以使用 Prophet 对未来进行预测。
ML 模型2 – 物流需求量预测模型
物流需求量的 ML 模型旨在捕获所有特征与物流需求量之间的关系。可以使用各种监督回归模型,从 LASSO, Ridge回归、随机森林、XGBoost、LightGBM、Catboost 等。在构建模型并为每个模型找到最佳参数时,可以使用保留数据来评估模型。
具体的算法细节可以参考我们的另一篇文章机器学习多步时间序列预测解决方案。
用户输入
由于大多数特征在未来都是未知的,于是我们使用一维时间序列模型预测这些时序特征。这让业务人员能对这些特征未来的走势有更加直观的感受。并且可以通过对这些特征的微调,让业务人员能够直接看到这些特征将如何影响业务的需求量。例如,价格通常与物流需求量有着密切的关系,业务人员可以对未来某个时刻制定促销或者折扣计划。然后通过将这些特征输入给模型进行推理,直接看到这样的计划可能会对物流需求量带来什么样的影响。此外,销售团队人数也可能是影响物流需求量的一个特征,销售团队的规模也是企业可以控制的。
总的来说,这类业务人员可以控制或提前知晓的特征,我们就可以利用这类特征作为用户可以调整的特征。在 ML 建模步骤中,先使用一维时间序列模型将对每个特征进行预测,然后用户可以检查这些预测值,并且允许用户对这些特征值进行修正。最后将这些被修正过的特征和其他相关特征一起输入到模型,做出最终的预测。
用户介入是至关重要的,因为在这个过程中我们对某些特征进行了时序预测,而如果这样的预测结果和业务人员的预期相差很大的时候,我们可以通过修改特征的预测值,再进行最终的物流需求量预测。这样的操作有可能改善整体的预测效果。
最佳实践
1. 在开始物流需求预测项目之前,将相关人员(业务人员、技术人员、管理人员等)聚到一起,通过头脑风暴的方式讨论物流需求预测是否是目前的业务痛点、目前的数据情况如何、期望达成怎么样的业务成果等。业务人员需要帮助数据科学家了解更多的业务知识,对业务的理解越深越有利于识别和创建有用的特征,从而构建更加可靠的预测模型。
2. 对于时间序列预测,建议有足够长的历史数据来进行模型训练,让模型从数据中学习到相应的模式。例如,要对未来12个月进行月度预测,最好有3-4年的历史数据来捕捉周期和趋势。
3. 在机器学习流水线中创建自动调参的步骤,为模型寻找最佳参数。通过这种方式,可以将相同的模型训练代码应用于不同的航线,并自动为每条航线寻找最佳模型。
4. 即使您可能没有足够长的历史数据,您仍然可以构建机器学习流水线和基线模型以查看其性能。随着您获得更多数据,模型将会被重新训练,并随着时间的推移提高模型的准确性。
本篇作者

陈恒智
亚马逊云科技专业服务团队数据科学家。

贾天下
亚马逊云科技专业服务团队高级数据科学家,他专注于帮助能源、媒体、供应链和物流以及金融服务行业的企业客户构建 AI/ML 解决方案。

Isabelle Imacseng
Data & ML Engineering Consultant at Amazon ProServe. She helps customers with data lake, data pipeline, and machine learning solutions.

听说,点完下面4个按钮
就不会碰到bug了!
















 8568
8568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









