







背景
大数据处理技术现今已广泛应用于各行各业,用于解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。当前业务通常已不再满足滞后的分析结果,企业希望看到更实时的数据,从而在第一时间做出判断和决策,典型的需求场景如电商大促和金融风控等,基于延迟数据的分析结果已经失去了价值。
如何构建一个统一的数据湖存储,并以之为基础进行多种形式的数据分析,成为企业构建大数据生态的一个重要方向。如何快速、一致地在数据湖存储上构建起 Data Pipeline,已是亟待解决的问题。
对于构建数据湖的过程中遇到的一些痛点,Iceberg 恰好能解决:
T+0 的数据落地和处理。传统的数据处理流程从数据入库到数据处理通常需要一个较长的环节,此中涉及许多复杂的逻辑来保证数据的一致性,也由于架构的复杂性使得整条流水线具有明显的延迟。Iceberg 的 ACID 能力可以简化流水线的设计,降低其延迟。
降低数据修正的成本。传统 Hive/Spark 在修正数据时需要将数据读取出来,修改后再写入,因此具有极大的修正成本。Iceberg 所具有的修改、删除能力能够有效地降低开销,提升效率。
在2022年,亚马逊云大数据分析服务 EMR6.5 已经集成 Iceberg,方便大家快速进行大型表查询性能、原子提交、并发写入 Amazon S3 的操作。
以用户行为分析为例,看看在亚马逊云上如何快速搭建一个 Iceberg 准实时数仓。
架构
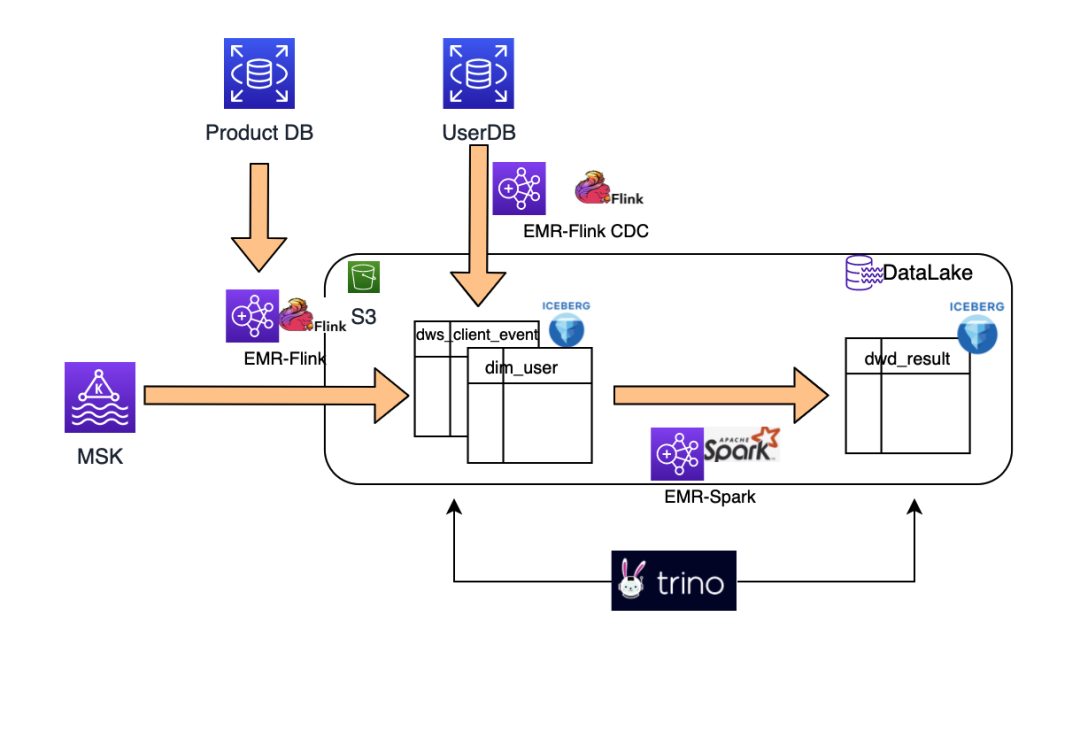

架构说明
1.用户行为数据(ClickEvent)从前端手机或者 Web 页面提交到 Amazon MSK。
2.经过 EMR-Flink 清理数据和关联产品信息后存入 Iceberg 表。
3.系统业务数据库用户和商品数据由于活动会产生变更,Amazon RDS DB 开启 binlog 通过 EMR-FlinkCDC 同步到 Iceberg 表。
4.监听 ClickEvent Iceberg table 实时计算集合数据。
5.通过 Spark 读取统一 HMS, 批量计算到结果表。
6.Trino ad-hoc 查询数据 Iceberg 流表数据。
组件版本
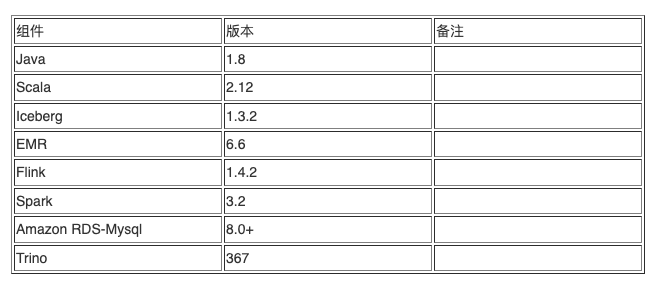
环境搭建
首先下载 demo 工程 github 地址, 通过 maven 编译。
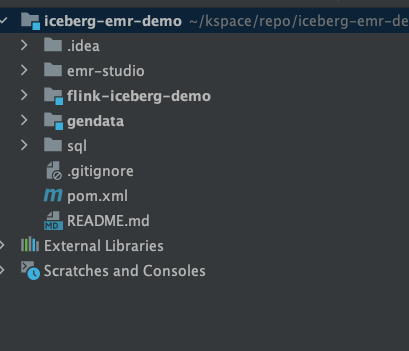
工程说明:
gendata:动态产生测试数据 input 到 MSK
Flink-iceberg-demo:实时消费 MSK 数据入湖
SQL:MySQL 设置表的 ddl 和测试使用 SQL
地址:
https://github.com/jiayew868/iceberg-emr-demo
Amazon MSK 创建(参考)
创建一个集群名字为“click-stream” MSK 集群,

在 config 页面 Bootstrap servers endpoint 和 zookeeper connection,
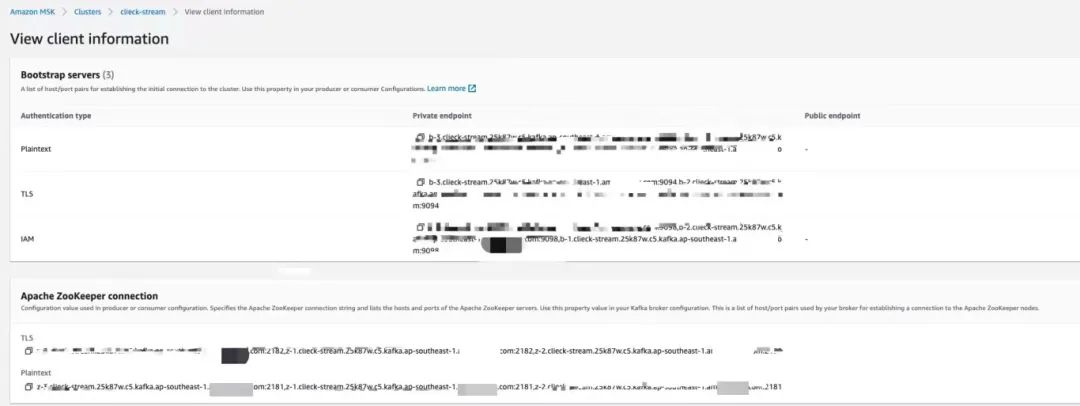
在一台 EC2 跳板机上通过 kafka client 创建 topic 和调试。
export BS={Bootstrap servers}
export ZK={zookeeper servers}
## 创建 topic
bin/kafka-topics.sh --create --zookeeper $ZK --replication-factor 3 --partitions 3 --topic clicktopic
##测试发送数据
/bin/kafka-console-producer.sh --broker-list $BS --producer.config client-stand.properties --topic clicktopic
## 测试接收数据
/bin/kafka-console-consumer.sh --bootstrap-server $BS --consumer.config client-stand.properties --topic clicktopic --from-beginning
## list topic
/bin/kafka-topics.sh --list --bootstrap-server $BS左滑查看更多
参考:
https://docs.aws.amazon.com/zh_cn/msk/latest/developerguide/getting-started.html
创建维表 Amazon RDS
a. 创建 RDS 并打开 MySQL binlog 配置
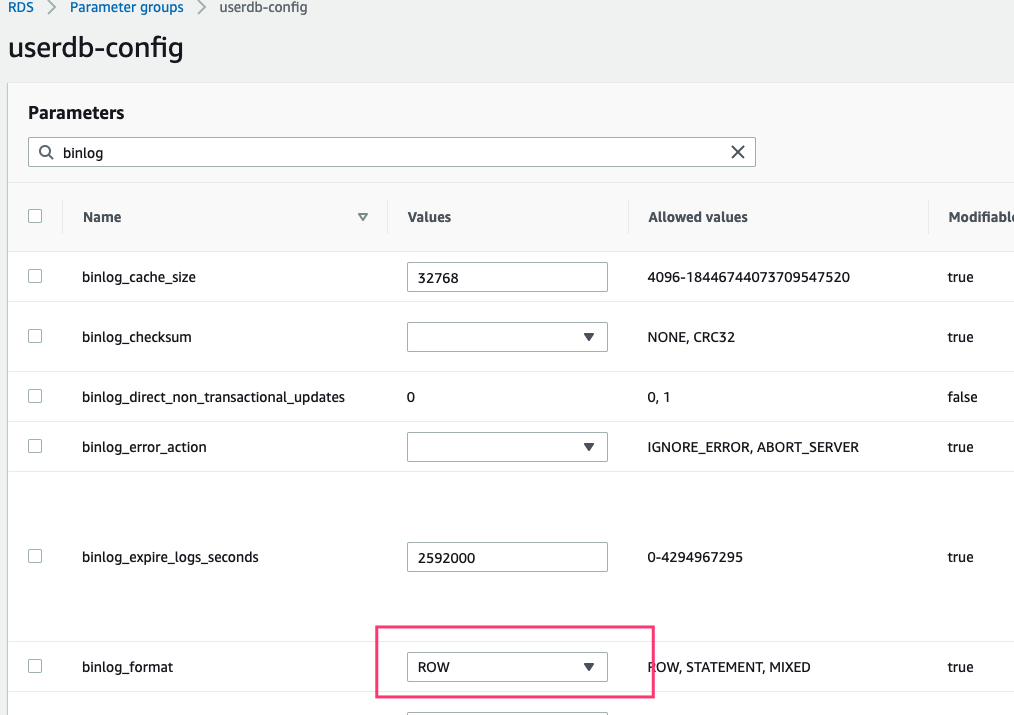
b. 创建 Table& 测试数据
CREATE TABLE products (
productId VARCHAR(10) NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512),
product_price DECIMAL(10, 4),
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
CREATE TABLE user_member (
userid VARCHAR(10) NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
show_params VARCHAR(256),
memberLevel int,
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);左滑查看更多
测试数据:
INSERT INTO products
VALUES ("1","test01","Small 2-wheel scooter" , 11.11, now()),
("2","test02","12V car battery",11.11,now()),
("3","test03","12-pack of drill bits with sizes ranging from #40 to #3",11.11,now()),
("4","test04","12oz carpenter's hammer",11.11,now()),
("5","test05","14oz carpenter's hammer",11.11,now()),
("6","test06","16oz carpenter's hammer",11.11,now()),
("7","test07","box of assorted rocks",11.11,now()),
("8","test08","water resistent black wind breaker",11.11,now()),
("9","test09","24 inch spare tire",11.11,now());
INSERT INTO user_member
VALUES ("513248","test01","label01" , 1, now()),
("10952","test02","label02",2,now()),
("555655","test03","label03",3,now()),
("795098","test04","label04",4,now()),
("603670","test05","label05",5,now());左滑查看更多
创建 Amazon EMR
创建含有 Flink、Spark 等组件的 EMR6.6 (使用Amazon EMR 6.6 版本演示。启动 EMR 集群非常简单,这里不再赘述,可以参考亚马逊云科技官方文档)。
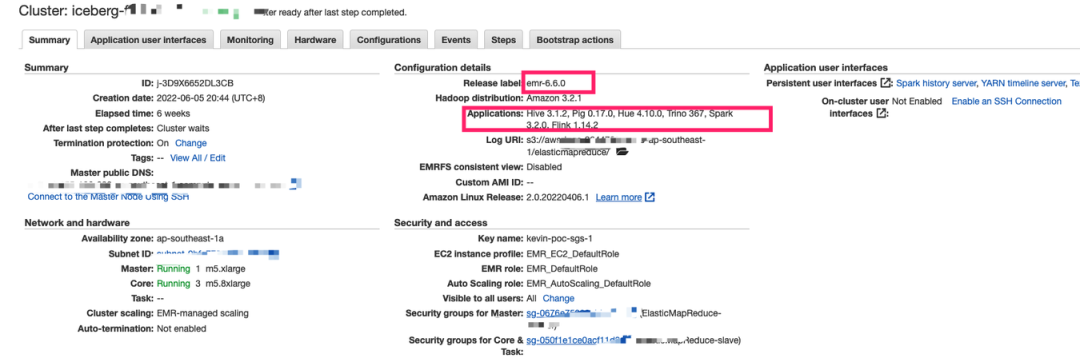
a.EMR 启动配置
[
{
"classification": "hive-site",
"properties": {
"javax.jdo.option.ConnectionUserName": "{metadb_user}",
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionPassword": "{metadb_password}",
"javax.jdo.option.ConnectionURL": "jdbc:mysql://{metadb_url}/hive?createDatabaseIfNotExist=true"
},
"configurations": []
},
{
"classification": "iceberg-defaults",
"properties": {
"iceberg.enabled": "true"
},
"configurations": []
},
{
"Classification": "flink-conf",
"Properties": {
"taskmanager.numberOfTaskSlots":"10"
}
}
]左滑查看更多
参数说明:
“hive-site”使用外接 RDS 作为 Hive metadata,配置 JDBC 连接
“iceberg-defaults” 开启 EMR Iceberg 配置
“taskmanager.numberOfTaskSlots”配置 taskmanager slot 数量(根据自己的集群机器设定)
b. 配置安全组
使其能访问 RDS,在 RDS 安全组添加 EMR master and slave 权限。
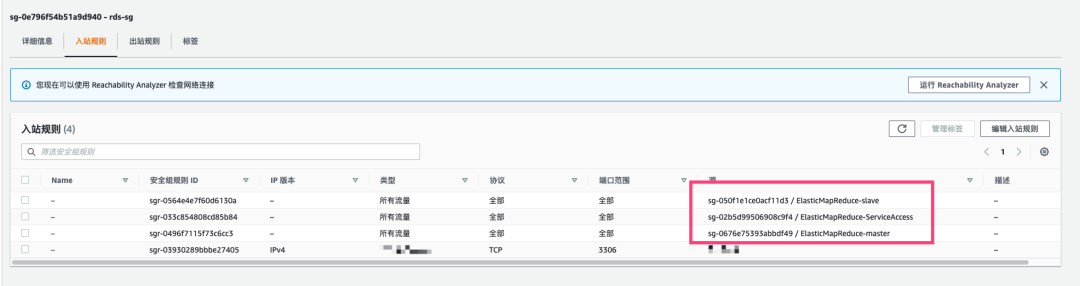
c.下载对应的第三方 JAR
(Flink-CDC、Kafka Flink connect 和 Flink jdbc connect)
下载 Flink-SQL-connector-MySQL-cdc、Flink-SQL-connector-kafka、Flink-SQL-connector-Hive 到 /usr/lib/Flink/lib/。
wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.14.2/flink-sql-connector-kafka_2.12-1.14.2.jar
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.1/flink-sql-connector-mysql-cdc-2.2.1.jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.14.2/flink-sql-connector-hive-3.1.2_2.12-1.14.2.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc_2.12/1.14.2/flink-connector-jdbc_2.12-1.14.2.jar左滑查看更多
d.启动 Flink YARN 集群
## 在flink bin 目录下启动
./yarn-session.sh -d -tm 1024 -s 5 –nm demo-flink左滑查看更多
参数说明
-jm 1024 表示 jobmanager 1024M 内存
-tm 1024 表示 taskmanager 1024M 内存
-d --detached 任务后台运行
-s 指定每一个 taskmanager 分配多少个 slots (处理进程)。建议设置为每个机器的 CPU 核数。一般情况下,vcore 的数量等于处理的slot(-s)的数量
-nm,--name YARN 上为一个自定义的应用设置一个名字
-q,--query 显示 YARN 中可用的资源(内存、CPU 核数)
-qu,--queue 指定 YARN 队列。
创建 Iceberg data lake
创建 Iceberg Flink SQL client 文件
“start.sh”
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# download Iceberg dependency
ICEBERG_VERSION=0.13.2
MAVEN_URL=https://repo1.maven.org/maven2
ICEBERG_MAVEN_URL=${MAVEN_URL}/org/apache/iceberg
ICEBERG_PACKAGE=iceberg-flink-runtime
wget ${ICEBERG_MAVEN_URL}/${ICEBERG_PACKAGE}/${ICEBERG_VERSION}/${ICEBERG_PACKAGE}-${ICEBERG_VERSION}.jar
## 当下载完成后可以注释掉
# open the SQL client.
/usr/lib/flink/bin/sql-client.sh embedded \
-j ${ICEBERG_PACKAGE}-${ICEBERG_VERSION}.jar \
shell左滑查看更多
启动含有 Iceberg runtime 的 FlinkSQL client。
[hadoop@ip-18-0-6-4 script]$ ./start.sh左滑查看更多
创建 user_member Iceberg 表
业务系统 user_member table 记录用户的会员等级和标签,由于它会根据业务的变化而变化,可以使用 FlinkCDC 实时同步的方式将数据同步到 Iceberg table。
a. 创建 Iceberg catalog
在使用 Iceberg 时候,必须创建一个 Iceberg catalog。
create catalog hive_catalog with(
'type'='iceberg',
'catalog-type'='hive',
'clients'='5',
'property-version'='1',
'hive-conf-dir'='/usr/lib/hive/conf',
'warehouse'='s3://sg-emr-flink-iceberg/mywarehouse/'
);左滑查看更多
参数说明:
“type”:指名这个是一个 Iceberg 的 catalog
“catalog-type”:统一使用 Hive 的 metadata 储存 Iceberg table schema
“warehouse” :Iceberg catalog 需要指定一个 S3 路径存放数据,在 S3 创建一个 bucket “s3://sg-emr-Flink-Iceberg/mywarehouse/”
b. 创建 user_sinkiceberg,同步 RDS 数据
use catalog hive_catalog;
CREATE DATABASE dim_db;
CREATE TABLE dim_db.user_member_sink(
`userid` STRING,
`name` STRING,
`show_params` STRING,
`member_level` int,
`update_time` TIMESTAMP(3),
PRIMARY KEY(userid) NOT ENFORCED
) with(
'type'='iceberg',
'catalog-type'='hive',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'warehouse'='s3://sg-emr-flink-iceberg/mywarehouse/',
'format-version'='2'
);左滑查看更多
c. 创建 Flink MySQL-cdc table
use catalog default_catalog;
use default_database;
CREATE TABLE default_database.user_member (
`userid` STRING,
`name` STRING,
`show_params` STRING,
`member_level` int,
`update_time` TIMESTAMP(3),
PRIMARY KEY (userid) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'user-database.crcwrov0yr1e.ap-southeast-1.rds.amazonaws.com',
'port' = '3306',
'username' = '{mysql_username}',
'password' = '{mysql_psw},
'database-name' = 'user_db',
'table-name' = 'user_member'
);左滑查看更多
d. 提交 Flink job
SET execution.checkpointing.interval = 10s;
use hive_catalog.dim_db;
insert into dim_db.user_member_sink select * from default_catalog
.default_database.user_member;左滑查看更多
打开 FlinkWebUI 检查 job 状态。
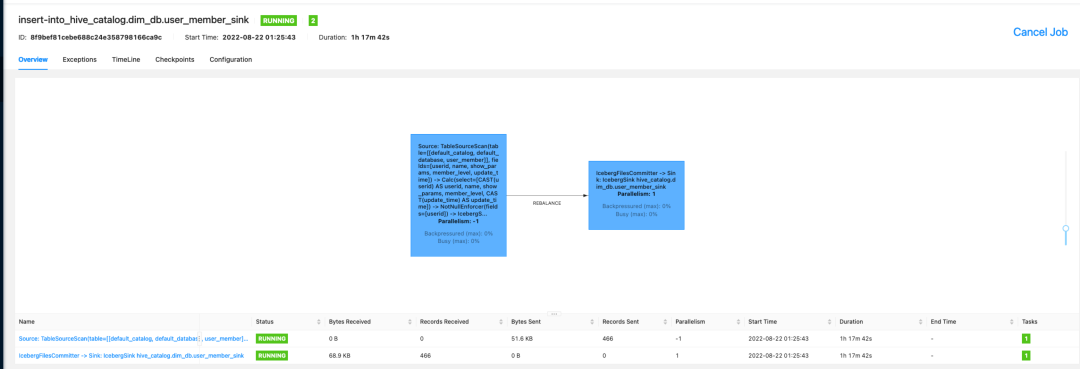
在 MySQL client 提交 “update user_member set member_level =2 where userid = '555655'”后,通过 FlinkSQL “select * from dim_db.user_member_sink;” 观察数据变化。

Event 数据入湖
a. Mock 前端数据通过 MSK 入湖
打开 gendata 工程,配置 MSK 地址和 Topic。
/**
* java -cp gendata-1.0-SNAPSHOT-jar-with-dependencies.jar com.demo.gendata.DataGen2 -c 100000 -s 10
*/
public class DataGen2 {
static class SampleCmdOption {
@Option(name = "-c", usage = "mock data number")
public int count = 1000000;
@Option(name = "-s", usage = "stop time /10")
public long sleeptime = 1L;
@Option(name = "-bts", usage = "kafka bootstrap")
public String bootstrap;
}
//配置MSK 地址
private final static String BOOTSTRAP_SERVERS_CONFIG = “xxxxxx.kafka.ap-southeast-1.amazonaws.com:9092,xxxxxxx.kafka.ap-southeast-1.amazonaws.com:9092,b-1.clieck-stream.xxxxxxxx.kafka.ap-southeast-1.amazonaws.com:9092";
//配置MSK topic
private static final String DEFAULT_KAFKA_TOPIC = "kafkatopic";
private final static Map<Integer, String> USERINFR_MAP = new HashMap<Integer, String>() {{
put(1, "513248");
put(2, "10952");
put(3, "555655");
put(4, "795098");
put(5, "603670");
}};
public static void main(String[] args) {
SampleCmdOption option = new SampleCmdOption();
CmdLineParser parser = new CmdLineParser(option);
try {
if (args.length == 0) {
showHelp(parser);
return;
}
parser.parseArgument(args);
System.out.println(option.count);
System.out.println(option.sleeptime);
} catch (CmdLineException cle) {
System.out.println("Command line error: " + cle.getMessage());
showHelp(parser);
return;
} catch (Exception e) {
System.out.println("Error in main: " + e.getMessage());
e.printStackTrace();
return;
}
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS_CONFIG);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put("acks", "-1");
properties.put("batch.size", "1048576");
properties.put("linger.ms", "5");
//properties.put("compression.type", "snappy");
properties.put("buffer.memory", "33554432");
properties.put("client.id", "producer.client.id.demo");
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
System.out.println("开始发送数据");
// 4. 调用 send 方法,发送消息
for (int i = 0; i < option.count; i++) {
String value = JSON.toJSONString(genUserBehavior());
ProducerRecord<String, String> record = new ProducerRecord<>(DEFAULT_KAFKA_TOPIC, value);
kafkaProducer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println(metadata.partition() + ":" + metadata.offset());
}
});
if (i % 1000 == 0) {
try {
TimeUnit.MILLISECONDS.sleep(option.sleeptime);
kafkaProducer.flush();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
kafkaProducer.flush();
// 5. 关闭资源
kafkaProducer.close();
}
static ClickEvent genUserBehavior() {
ClickEvent clickEvent = new ClickEvent();
clickEvent.setCookieId(RandomStringUtils.random(15, true, false));
clickEvent.setExpendTime(RandomUtils.nextInt(0, 20));
clickEvent.setWebpageId(RandomUtils.nextInt(10, 100));
clickEvent.setUid(USERINFR_MAP.getOrDefault(RandomUtils.nextInt(1, 6), "10001"));
clickEvent.setUpdateTime(System.currentTimeMillis());
clickEvent.setUpdateTime(DateTime.now().getTime());
clickEvent.setProductId(String.valueOf(RandomUtils.nextInt(0,20)));
return clickEvent;
}
public static void showHelp(CmdLineParser parser) {
System.out.println("LDA [options ...] [arguments...]");
parser.printUsage(System.out);
}
}左滑查看更多
打开项目并通过编译 JAR 上传到 EC2,打包后上传到 EC2。 请使用 JVM CMD 执行 java -cp gendata-1.0-SNAPSHOT-jar-with-dependencies.jar com.demo.gendata.DataGen2 -c 100000 -s 10 -bootstrap {kafka_bootstrap}。
参数说明:
-c 发送数据条数据
-s 每1000条数据 sleep毫秒数
b. 将 MSK 数据保存到 Iceberg table
编译打包 Flink-iceberg-demo,将 JAR 包上传到 EMR Master Node 后,提交 Flink job 运行。
这里需要将 MSK 数据和 MySQL 里的 Products 数据 join,然后存储到 Iceberg table,Flink Temporary table join 可以帮助我们解决维表 join 流表问题。
public class Kafka2Iceberg {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.disableOperatorChaining();
env.setParallelism(5);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setInteger("table.exec.resource.default-parallelism", 5);
configuration.setBoolean("table.dynamic-table-options.enabled", true);
Properties properties = new Properties();
properties.setProperty("max.partition.fetch.bytes", "10485760");
properties.setProperty("request.timeout.ms", "120000");
properties.setProperty("session.timeout.ms", "60000");
properties.setProperty("heartbeat.interval.ms", "10000");
env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage(FLINK_CHECKPOINT);
String kafkasourceTable = "CREATE TABLE IF NOT EXISTS default_database.kafka_table (\n" +
" `webpageId` int,\n" +
" `uid` STRING,\n" +
" `productId` STRING,\n" +
" `cookieId` STRING,\n" +
" `expendTime` int,\n" +
" `updateTime` BIGINT,\n" +
" `proctime` as PROCTIME(), -- 通过计算列产生一个处理时间列\n" +
" `eventTime` AS TO_TIMESTAMP(FROM_UNIXTIME(updateTime/1000, 'yyyy-MM-dd HH:mm:ss')) -- 事件时间\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = '"+ DEFAULT_KAFKA_TOPIC +"',\n" +
" 'properties.bootstrap.servers' = '"+ BOOTSTRAP_SERVERS_CONFIG +"',\n" +
" 'properties.group.id' = 'test-group02',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
" )";
String productsTable = "CREATE TABLE IF NOT EXISTS default_database.products_jdbc (\n" +
" productId STRING PRIMARY KEY,\n" +
" name STRING,\n" +
" description STRING,\n" +
" product_price DECIMAL(10, 4),\n" +
" update_time TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = '" + MYSQL_URL + "',\n" +
" 'table-name' = 'products',\n" +
" 'username' = '"+ MYSQL_USER + "',\n" +
" 'password' = '"+ MYSQL_PSW +"',\n" +
" 'scan.fetch-size' = '100',\n" +
" 'lookup.cache.max-rows' = '5000',\n" +
" 'lookup.cache.ttl' = '10s',\n" +
" 'lookup.max-retries' = '3'\n" +
" )" ;
String flinkCatalogSQL = "create catalog iceberg_hive_catalog with(\n" +
" 'type'='iceberg',\n" +
" 'catalog-type'='hive',\n" +
" 'clients'='5',\n" +
" 'property-version'='1',\n" +
" 'hive-conf-dir'='/usr/lib/hive/conf',\n" +
" 'warehouse'='s3://sg-emr-flink-iceberg/mywarehouse/'\n" +
")";
String clickEventTable = "create table IF NOT EXISTS ods_behavior.clickevent_v5(\n" +
" `webpageId` int,\n" +
" `uid` STRING,\n" +
" `productId` STRING,\n" +
" `cookieId` STRING,\n" +
" `expendTime` int,\n" +
" `updateTime` TIMESTAMP(3),\n" +
" `name` STRING,\n" +
" `product_price` DECIMAL(10, 4),\n" +
" `dt` STRING,\n" +
" `eventTime` TIMESTAMP(3)\n" +
") PARTITIONED BY (dt) with(\n" +
" 'type'='iceberg',\n" +
" 'catalog-type'='hive',\n" +
" 'write.metadata.delete-after-commit.enabled'='true',\n" +
" 'write.metadata.previous-versions-max'='5',\n" +
" 'sink.parallelism' = '5',\n" +
" 'sink.partition-commit.policy.kind'='metastore,success-file', \n" +
" 'warehouse'='s3://sg-emr-flink-iceberg/mywarehouse/',\n" +
" 'write.upsert.enable'='true',\n" +
" 'format-version'='2'\n" +
")";
String insertETL = "insert into ods_behavior.clickevent_v5(\n" +
" webpageId,\n" +
" uid,\n" +
" productId,\n" +
" cookieId,\n" +
" expendTime,\n" +
" updateTime,\n" +
" name,\n" +
" product_price,\n" +
" eventTime,\n" +
" dt\n" +
") select\n" +
" aa.webpageId,\n" +
" aa.uid,\n" +
" aa.productId,\n" +
" aa.cookieId,\n" +
" aa.expendTime,\n" +
" aa.updateTime,\n" +
" bb.name,\n" +
" bb.product_price,\n" +
" aa.eventTime,\n" +
" DATE_FORMAT(LOCALTIMESTAMP, 'yyyyMMdd')\n" +
"from\n" +
" default_catalog.default_database.kafka_table AS aa\n" +
" left join default_catalog.default_database.products_jdbc FOR SYSTEM_TIME AS OF aa.proctime AS bb\n" +
" on aa.productId = bb.productId";
tableEnv.executeSql(kafkasourceTable);
tableEnv.executeSql(productsTable);
tableEnv.executeSql(flinkCatalogSQL);
tableEnv.useCatalog("iceberg_hive_catalog");
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS ods_behavior");
tableEnv.executeSql(clickEventTable);
tableEnv.executeSql(insertETL);
}
}左滑查看更多
修改 MySQL jdbc、MSK 地址和 topic 后,Flink CLI 提交 job。
./bin/flink run -m yarn-cluster -ynm -c com.demo.flinkiceberg.Kafka2Iceberg flink-iceberg-demo-1.0-SNAPSHOT.jar左滑查看更多
检查 Flink web UI。
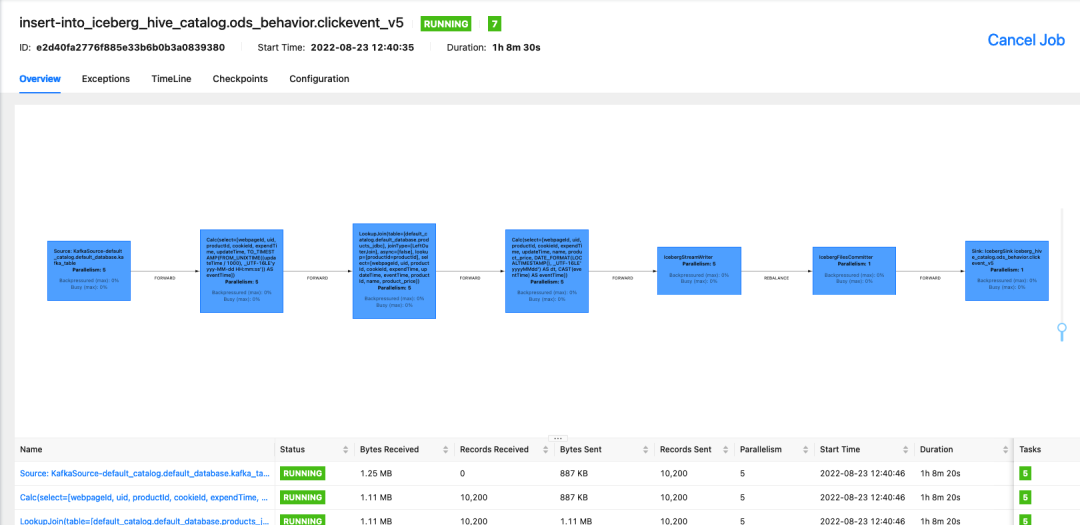
c. 使用 FlinkSQL 实时统计
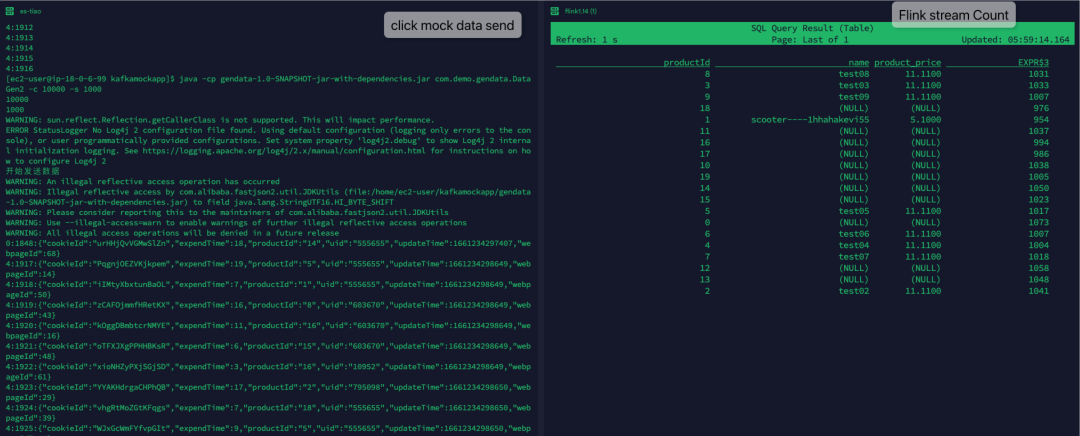
使用 Iceberg stream table 统计产品客户浏览。
select
productId,
name,
product_price,
count(uid)
from
ods_behavior.clickevent_v5 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/
group by
productId,
name,
product_price左滑查看更多
实时发送 mock data,可以看见 Flink 实时统计数据在变化。
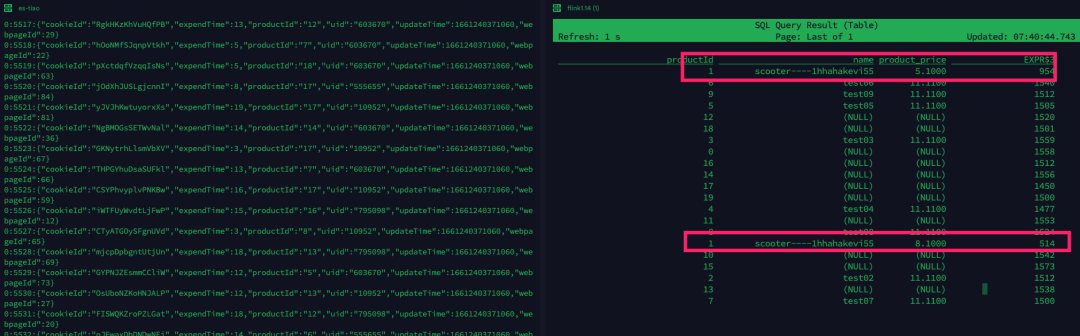
当更新 products table 后,统计数据也发生变化。
update products set description = 'test666' ,product_price =8.1 where productId = '1';左滑查看更多
d. Spark 批处理数据
Spark 可以和 Flink 共享 Hive metadata,批流都可以通过同一套 schema 管理。
这里使用 EMR studio 提交测试脚本,
大家可以查看具体的 notebook。

notebook:
https://github.com/jiayew868/iceberg-emr-demo/tree/main/emr-studio
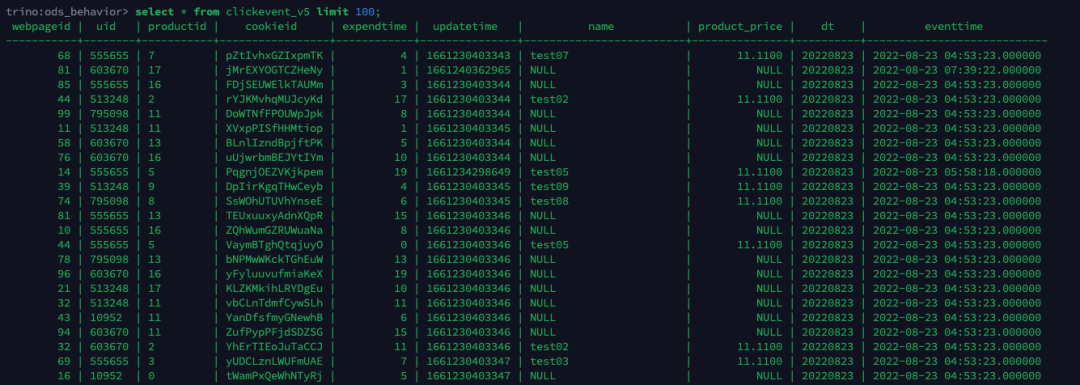
e. Trino ad-hoc 查询数据
配置 Trino Iceberg connect,
cd /usr/lib/trino/etc/catalog
trouch iceberg.properties
vim iceberg.properties将如下配置加入 Iceberg.properties,
connector.name=iceberg
hive.metastore.uri=thrift://localhost:9083左滑查看更多
执行:
trino-cli --catalog iceberg
trino> use iceberg;
trino> use catalog iceberg;
trino> show Schemas;
、trino> use ods_behavior;
trino:ods_behavior> select * from clickevent_v5 limit 100;左滑查看更多
总结
Apache Iceberg 与 Amazon S3、EMR 集成, 适用于大型数据集的开放表格式,提供快速的大型表查询性能、原子提交、并发写入和 SQL 等功能,能快速构建一个准实时数仓。
参考资料
Iceberg 官网:
https://iceberg.apache.org/
Flink Temporal Joins:
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/sql/queries/joins/
亚马逊云科技 Iceberg 文档:
https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/emr-iceberg.html
本篇作者
汪建业
亚马逊云科技解决方案架构师,负责基于亚马逊云科技云计算方案架构的咨询和设计,同时致力于 Amazon IoT 和大数据服务在国内和全球企业客户的应用和推广。十余年分布式应用、大数据的分布式处理经验。

张振威
亚马逊云科技 APN 解决方案架构师,主要负责合作伙伴架构咨询和方案设计,同时致力于亚马逊云科技云服务在国内的应用及推广,擅长数据迁移,数据库调优和数据分析相关。

听说,点完下面4个按钮
就不会碰到bug了!















 8485
8485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









