







前言
随着微服务和云原生架构的普及、成熟,越来越多的公司开始使用微服务架构来解耦应用,提高业务的迭代发布速度,实现业务价值。微服务架构可以提高开发灵活性和部署速度,但本质上是混乱的。随着规模越来越大,系统也变得越来越复杂,且众所周知,故障总是发生在意料之外,情理之中,没有一个系统能够保证100%的持续正常运行,这是我们需要学会接受的事实,虽然可以使用一些技术对故障进行降级,使用冗余部署实现架构高可用容错。但在复杂系统中,从不同微服务之间的交互到现实世界的破坏性事件,不可预测的结果随时笼罩着生产环境。探索复杂系统未知问题的手段之一就是开展混沌工程,混沌工程是一门新兴的技术学科,它的初衷是通过实验性的方法,让工程师建立应对复杂系统中未知问题的信心。
作为混沌工程的鼻祖 Netflix,在混沌工程的探索上,有着丰富的经验,本文主要围绕 Netflix 在 re:Invent 2022 – The evolution of chaos engineering at Netflix (NFX303) 的分享,结合自身的理解,从技术的视角,介绍 Netflix 的混沌工程的技术演进,为正在建设混沌工程平台的企业提供参考。
Netflix 在 re:Invent 2022 – The evolution of chaos engineering at Netflix (NFX303):
https://www.youtube.com/watch?v=Xbn65E-BQhA&t=1898s
Netflix 如何进行混沌工程实验
2.1 Netflix 公司简介
Netflix(中文名网飞)是起源于美国,在全球市场提供视频网络点播的 OTT 服务公司。Netflix 最初提供在线 DVD 租赁服务。客户使用 Netflix 网站来选择想要租赁的电影,成功下单后,Netflix 会通过邮递的方式,将电影 DVD 寄给客户。在 Netflix 迁移上云之前,Scale-up 架构给 Netflix 带来过很多的单点故障,在2008年,Netflix 经历了一次重大的数据库存储故障,导致了3天的停机,无法向客户邮寄 DVD。同时,Netflix 的业务也慢慢从北美线下 DVD 转变为覆盖全球的线上流媒体服务,Netflix 流媒体服务也会整合到多种播放设备上,不仅仅是 PC,还增加了各式各样的手机、电视盒子等等,未来的成长规模几乎难以预测,如何满足至少是1000倍的扩充需求且24小时不中断?因此 Netflix 决定转向公有云,并在转型过程中逐渐使用微服务对架构进行重构,满足业务扩展的需求,更好的服务全球客户。

今天,如果您在 Netflix 平台上体验他们的流媒体服务,在这流畅的流媒体服务背后,有两大部分组成,一部分是云,这部分在 Amazon 上,主要由大量的实例组成,用于对会员的播放请求进行验证,并选择体验最佳的 Open Connect Appliance,将其内容 URL 返回给客户端设备。另一部分是 Netflix 定制的 CDN 网络,其中包含 Open Connect Appliance 简称 OCA,用于处理和响应客户端的流媒体请求,通过验证的客户端从返回的 OCA URL 列表中选择速度最快,最稳定的节点进行连接,观看视频。
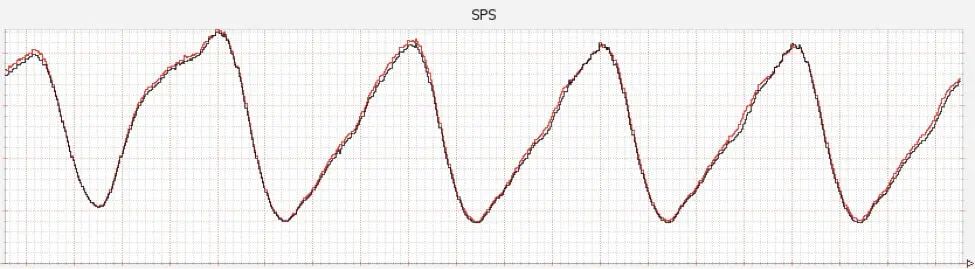
在峰值的时候,Netflix 贡献了大约北美互联网三分之一的流量,当您单击播放视频时,Netflix 将对您的访问进行验证,并将视频流发送到您的设备,这个事件 Netflix 称其为 Stream Start,Netflix 将纪录流的启动数量,称之为 SPS (stream per second),这是 Netflix 工程师监控的关键业务指标,上图显示了 SPS 指标每天是如何变化的。
2.2 Chaos Monkey 军团
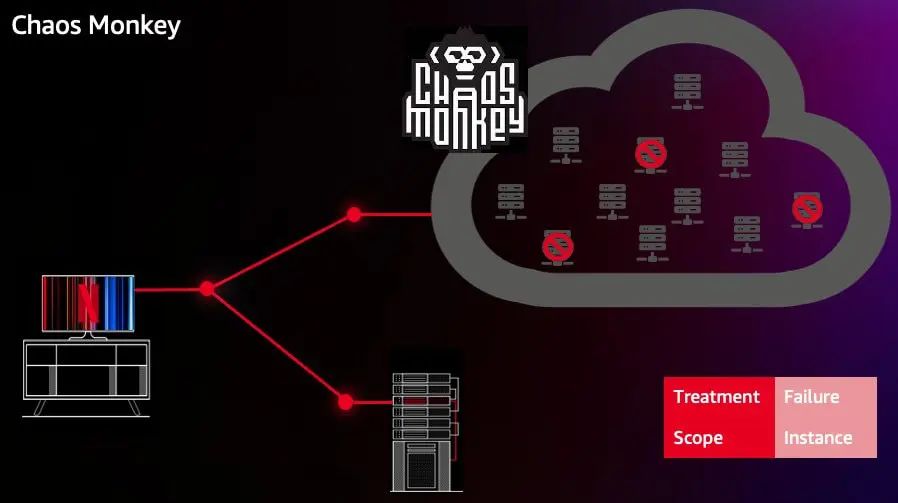
我们先把 Open Connect Appliance 放在一旁,现在先聚焦在 Netflix 在云上的部分服务,我们称之为 Netflix 服务的“控制平面”(Control Plane)。在2008年,公有云还不像现在这么成熟,实例故障经常发生。因此 Netflix 有必要保证在实例故障的情况下不影响流媒体的播放,这就是 Netflix 最初构建 Chaos Monkey 的原因。Chaos Monkey 用于测试系统应对个别实例故障的韧性,这个工具非常简单,它会遍历集群列表,从集群中随机选择计算实例,并关闭它们,这做法直接将问题摆在工程师面前,工程师可能需要借助增加冗余或者使用 autoscaling group,甚至在软件架构上进行调整。在这场混乱之旅的前期,这是一种非常简单但有效的方法,它帮助 Netflix 的服务建立了对节点故障的韧性。虽然这是个非常粗糙的工具,但多年来,它已经成为混沌工程的代名词,且不断发展壮大,形成了“猴子军团”,用于模拟注入各种各样的问题,甚至诞生了 Chaos Kong,用于模拟亚马逊云平台 Region 级别的故障。
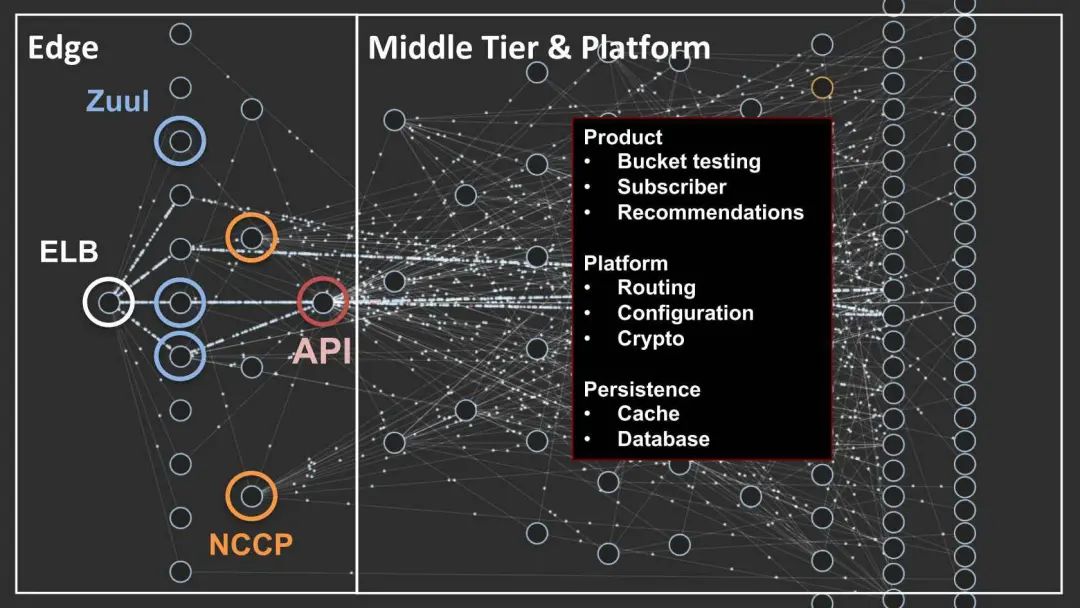
直至今日,Chaos Monkey 仍然在服役,但它提供的价值已经很小了。我们可以看下 Netflix 云架构的鸟瞰图,Netflix 后台的架构现在已经比一组实例要复杂的多,客户请求从负载均衡器(ELB)进入云端,通过 Zuul 网关随着服务调用层层传播。另外由于微服务等架构的使用,有很成熟的负载均衡冗余、Fallback、Retry 等机制用于处理此类问题,单一实例的故障已经很难影响业务可用性。Netflix 自身在微服务领域也是业界先驱,他们为业界贡献了很多微服务的工程实践,也为 Spring Cloud 社区贡献了一些耳熟能详的开源组件,如:Eureka、Zuul、Hystrix 等。
2.3 Failure Injection Technology
在2014年,Netflix 经历了一次中断,负责管理用户订阅的服务遇到了一些意想不到的内部错误,该订阅服务管理着会员的订阅和用户的注册、创建或修改 profile。虽然这项服务对 Netflix 的业务非常重要,但对于流媒体的播放并不关键。如果用户的设备已经认证,本应该能播放客户喜欢的节目,然而这次问题期间,会员无法播放他们喜欢的节目。且发生问题的服务已经根据预先设置的 fallback 策略工作,但系统仍然无法正常处理用户的播放请求。这个情况在之前从未发生过,Netflix 意识到要模拟这些场景,需要能够注入 Failure 到服务本身。这也是建立 FIT (Failure Injection Technology) 的原因。
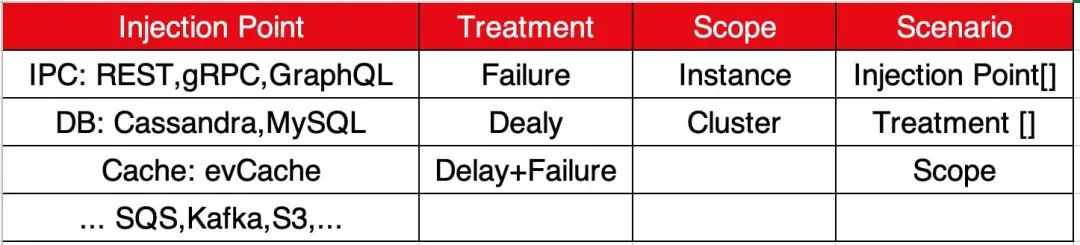
FIT 是 Netflix 的故障注入技术,它使 Netflix 能够精确的注入故障。FIT 规范了故障注入的定义,理解这些定义有助于理解后面各场景:
● Injection Point:注入点,例如针对 IPC 有 REST、gRPC、GraphQL 注入点;
● Treatment:如 Failure、Delay、Failure+Delay;
● Scope:故障注入范围,如 Instance 或者 Cluster;
● Scenario:准确的定义了将要发生的事情,它定义了 Injection Point、Treatment、以及 Scope;
● Session:是一个正在运行的 Scenario。
这使得 Netflix 可以进行一些 Gameday 的设计,大家聚在一起创建一个 FIT 场景,然后启动它,观察服务的表现如何、查看指标和日志的异常和变化、接口的请求错误等,还会查看 SPS 指标的变化。通过这种方式,Netflix 能够在 Gameday 模拟一些故障来进行技术验证。

我们以2014年的订阅服务故障为例,来看看他在实践中是怎么工作的:
首先创建一个实验场景,注入点是一个与 “subscriber” (图中 B 集群) 服务通讯的 gRPC 客户端,把范围限定为 “playback” (图中 A 集群),把 Treatment 设置为 Failure。如大家所看到的,相比 Chaos Monkey 而言,FIT 的精度要好得多。通过故障注入,Netflix 能触发 Fallback,且验证这些 Fallback 能否被正常处理,如果无法处理,那么就可以停止实验,提交工单,由工程师做修复。通过 FIT,Netflix 确保2014年的中断不再发生。
FIT 和 Gameday 代表了 Netflix 混沌工程的一个新阶段,但仍然是一个相当粗糙的方法,因为在注入点,所有的请求都失败了。且指标的收集、日志的查看,仍然是一个复杂的工作,所以 Netflix 决定增强改进实验。首先,针对实验的 Scope,在 Cluster 基础上,增加了 Request,来更精细的控制实验。Netflix 称之为 Request Context 或者Custom Request Routing (CRR)。
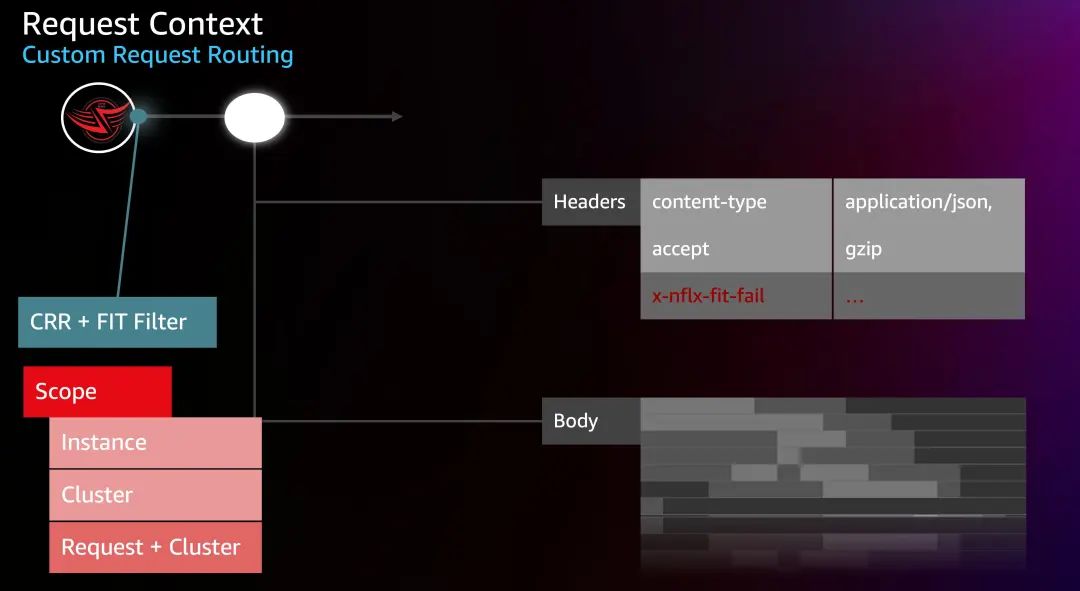
让我们借助上图来解释下它是如何工作的,对于一个 HTTP/gRPC 请求,它是由 Request Header 和 Body 组成。Netflix 在边缘网关(Zuul)中整合了一个 FIT Filter,来执行请求的标记工作。这些标记以自定义的 Header 的方式插入请求,并通过请求传播到调用的每个服务。当请求到达注入点时,注入点将检查这些 Header,决定是否触发注入。这样就可以精确地标记请求,只针对某些请求进行故障注入。
CRR 极大地提升了 Netflix 对故障注入的精度,我们来看下图场景,如果要对 Cluster A 位置发起到服务 B 的 gRPC 客户端请求、且对用户 ID 为 #1234 的请求发起故障注入,只需在 FIT Scope 定义中增加 CID,其他设置不变。这时候这台设备的请求将通过边缘网关,被 FIT Filter 附加标记到 Request Header,这些 Header 在请求中传播,到达 Cluster A 时,如果继续通过 gRPC 请求 Cluster B,该请求将被注入 Failure。
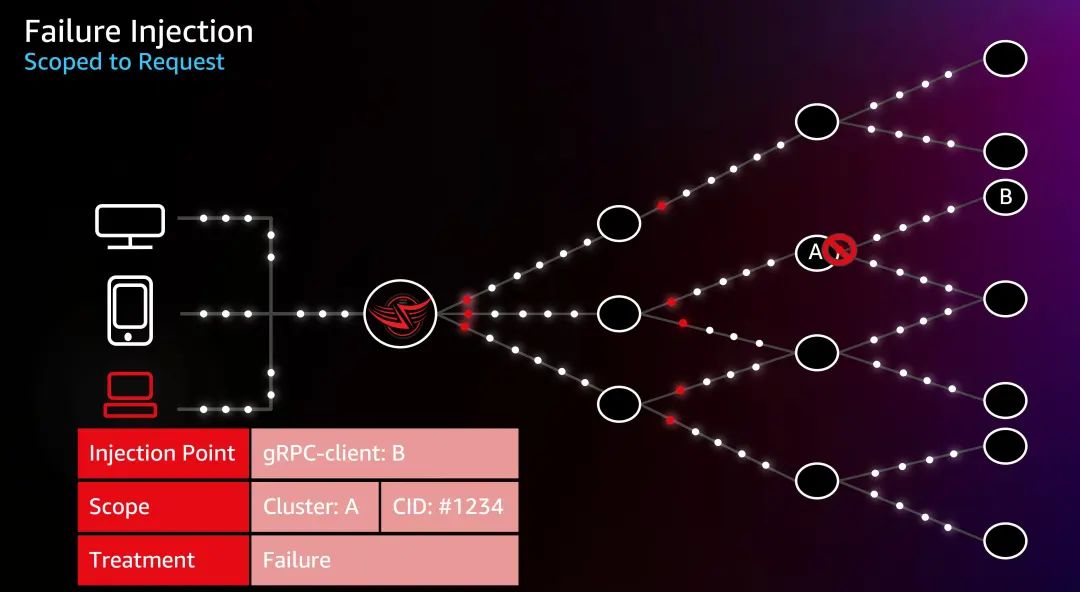
我们可以看到,这个注入仅针对该设备,只有这台设备受影响,就是这么简单。这个是 Netflix 混沌工程的另一个转折点,因为它使软件的开发人员只需创建并应用 FIT Session,可以直接在指定的设备上进行混沌测试。他们将能够亲眼看到每个特定的 FIT 场景如何影响用户。
Netflix 将这些功能构建为一个平台,称为 FIT,主要用于在生产中注入微服务级别的故障,Netflix 也为 FIT 提供了 Web UI,任何软件工程师都可以在平台上选择他们的故障注入点,配置运行他们想要的实验场景。这被证明是开创性的,有史以来第一次让工程师能够自己去试验混沌,无需混沌工程师或 SRE 的协助,他们配置 FIT Session,几秒后就可以看到是否有影响。



2020年 Netflix 推出“双倍点赞”这个功能,能够帮助 Netflix 精准根据客户喜好推荐内容。该功能由 Ratings 服务提供,与用户流媒体体验相比,这不是一个真正重要的功能,即使该服务出现问题,用户仍然应该可以按播放按钮播放视频。
为了验证这一点,该功能的开发人员自己创建了 FIT Session,在 playback 到 ratings 的 gRPC 客户端注入了 Failure 类型的故障,且指定了自己设备的 ESN 和 CID。启动 FIT Session,开发人员观察到该服务故障,SPS 未受影响,也不影响应用的流媒体播放。这样,开发人员就可以推断,ratings 服务发生故障,不会影响会员的流媒体播放,可以安全的启用该 feature。
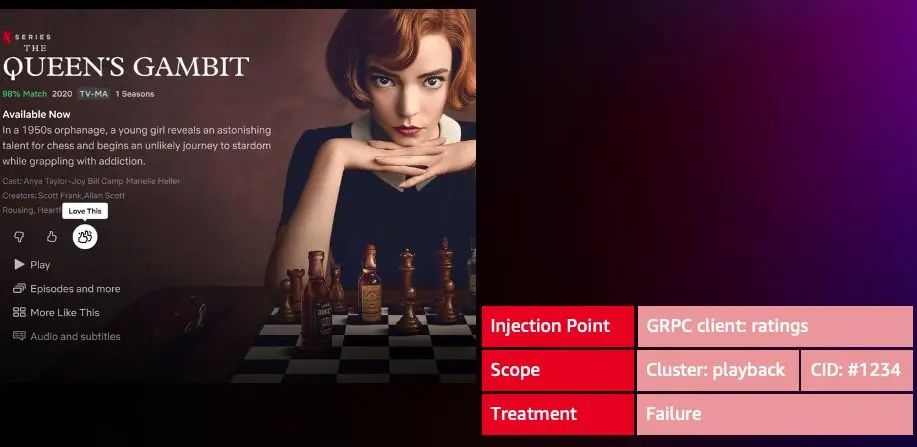
并且,针对每个运行的 FIT Session,Netflix 也纪录了完整的请求信息,因此开发人员可以看到注入失败的位置、系统如何反应、触发了哪些回退、这个失败是如何处理和返回给调用者的。很快,开发工程师们开始集成这些 FIT Header 到他们的冒烟测试和集成测试,FIT 也成为日常应用发布流程的一部分。所以这是一个新的转折点,甚至多年后的现在,FIT 测试仍然是 Netflix 一个非常流行的测试方法。开发人员可以非常快速的创建一个 FIT Session,在自己的设备上去重现它们,在上线前提前发现问题,及时处理修复。
2.4 ChAP: Chaos Automation Platform
大约在同一时间,一些不同的新技术正在首次亮相。如果在没有任何保障的情况下部署到了生产环境,这会是非常冒险的行为。Netflix 工程师每天部署成百上千的变更到生产环境,如何在不增加额外的负担的情况下,提供安全的部署方法呢?如果不能解决该问题,将会阻碍 Netflix 创新速度。

Netflix 选择了科学的方式,将随机对照实验引入部署中。这在医药研发行业是非常流行的实验设计,假设你在开发新的药物,你想看看药物的作用,所以你需要一群人,比如说十万人。然后你将他们分为两组,治疗组和对照组,治疗组会得到治疗,而对照组会得到安慰剂或什么都没有。然后让实验运行一段时间,关注并收集结果,一旦你比较了结果,由于这些组是随机分配的,不会有偏见或差异,这两组的结果之间可以安全的反映使用的药物的作用。
所以 Netflix 采用了这种方法,开始创建 Canary 策略,一般也称为金丝雀发布。在为某个服务(服务A)应用 Canary 策略时,意味着为这个服务创建了两个额外的集群,Baseline(蓝色)集群和 Canary(红色)集群。然后这些集群的成员获得一些小而随机的生产流量,Netflix 对照这两个集群的表现,对照 Baseline 和 Canary 两个集群的观测信号(指日志、追踪、指标等)。Canary 是一个非常简单有效的技术,已经被行业作为应用部署的实践标准,也是在生产环境中进行混沌实验时控制爆炸半径的方法。
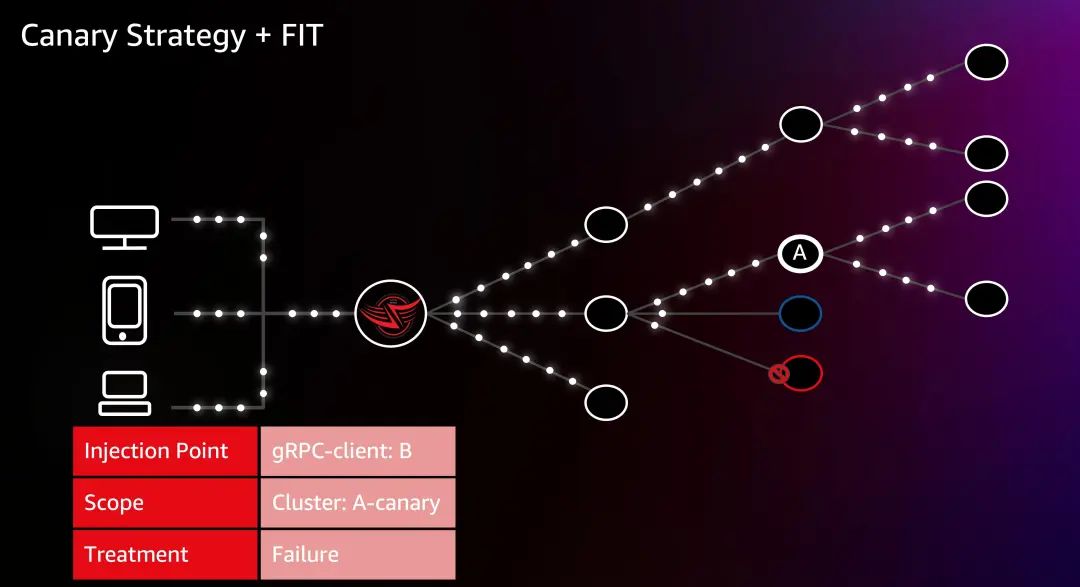
在使用 Canary 发布的基础上,Netflix 将 Canary 与 FIT 技术结合,对于 Canary 集群,仍然将故障注入 Failure 到与 B 通讯的 gRPC 客户端,但是注入范围会有所变化,只影响 A 的 Canary 集群,然后观察对比 Canary 与 Baseline 的观测数据。这是一个非常成功的途径和方法,为 Netflix 提供了巨大的价值。让 Netflix 能够安全、快速地在生产环境中验证新的技术和功能。
但如果你关注 Canary 本身,你会意识到这种方法,虽然低风险而且易于设置,但是它没有告诉我们,最终用户以及用户的设备上正在经历什么。因为我们只关注这两个服务本身的指标,服务器可能愉快地处理请求,但我们的会员可能无法播放视频流。让我们用两个例子来说明:
● 第一个问题:我们可以看到这个请求在 Canary 集群失败,由于这些请求是随机分配到集群的,并且非粘性的,当我们随机重试时,该请求可以转到 Baseline 集群并且请求成功,这样就可以掩盖这个问题,服务所有者甚至可能不会发现这个问题,直到部署到生产环境中;
● 我们的第二个例子是,请求成功,从 Canary 集群返回,并且它被调用者正确处理。但随着这个请求结果成为上游依赖的调用一部分,它实际可能在我们的会员设备上表现为异常,而我们永远不会知道。因为我们只看这两个对照服务集群的的观测数据。

为了解决请求重试的问题,Netflix 扩展了 FIT filter,添加了一种新的 Request Header,可以明确地告诉每个请求,它应该到哪里去,也就是请求具有粘性。Netflix 在微服务框架中使用 Ribbon 客户端负载均衡器,默认情况下,会基于负载均衡的策略来请求下游服务,Netflix 基于新的 Request Header,改变 Ribbon 的负载均衡行为,将流量固定分配给 Canary 或 Baseline 集群。
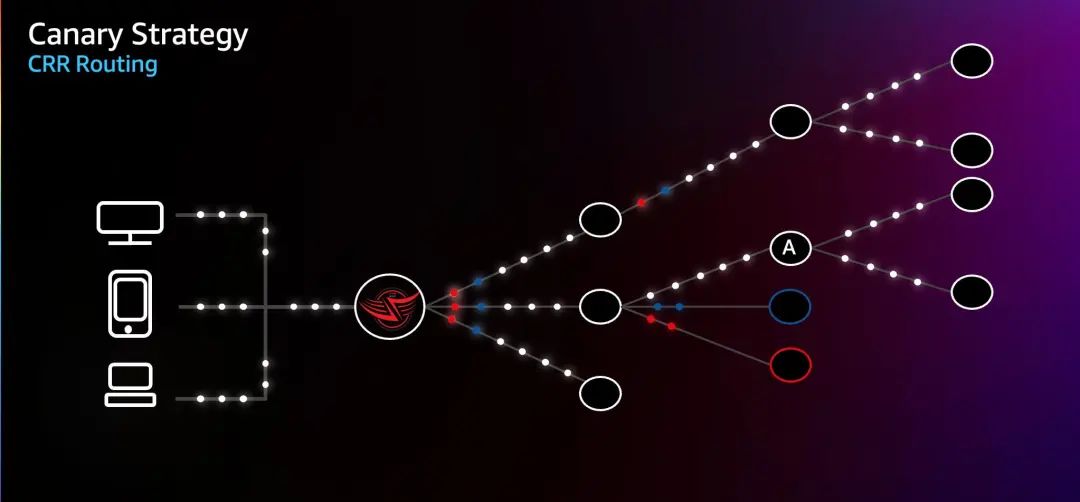
在使用 CRR 的情况下,当请求被分配时,在通往金丝雀服务的边缘网关 Zuul 中,他们被 FIT Filter 增加 Request Header,这个流量要么被分配到 Canary 集群,或者去往 Baseline 集群。然后这些 Request Header 随着请求传播,一旦请求到达注入点 Cluster A,这些被增加的 Header 开始生效,请求将直接被路由到 Canary 或 Baseline 集群。这时候假设某个请求被转发给 Canary 集群,即使请求失败后发起重试,重试请求仍然还是被分发到 Canary 集群。使得请求被锁定在实验中。

第二个改进是针对分配请求的方式,Netflix 再次扩展了 FIT Filter,增加了 User Allocation 的算法,借助 hash 函数,Netflix 可以将一定范围的用户分配到 Canary 集群和 Baseline 集群。在这个例子中,我们基于 ESN 应用 hash,将1%的请求分配给了 Canary 集群,将1%的请求分配给了 Baseline 集群,其余的 98% 的请求不受实验影响。这样可以始终如一地知道实验中包含哪些客户设备。
这些混沌工程的实验并不是总是按预期进行的,因此需要一个好的观测解决方案来洞察系统的内部状态。
● Netflix 一直在使用一个叫 Atlas 的监控系统,这个系统帮助 Netflix 对整个系统、以及后端的服务、节点、Infra 做监控;
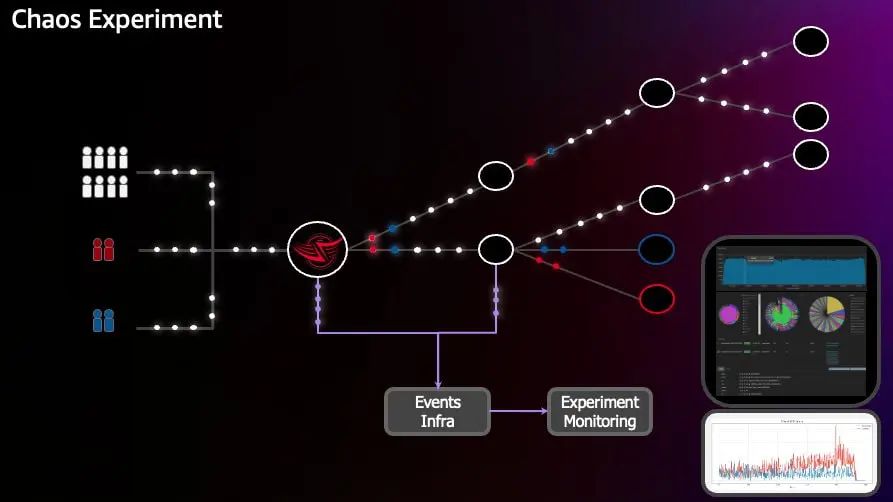
● Netflix 从用户开始收集日志,这些日志将向我们描述设备上到底发生了什么(类似现在的 Real User Monitor,RUM),这些事件包括 Stream Start (一个视频流的启动)、设备开始播放流媒体内容、设备出现流启动错误、尝试流传输但失败或应用程序崩溃等。这些数据和常规的请求一起发送,通过 Netflix 的基础设施,到达 Zuul 网关,被重定向到消息队列,实时的处理收集到 Events Infra;
● 同样的,用户的一些特定事件,例如后端服务请求信息和基础设施的事件也会被收集起来,形成正在发生事件的全貌。Netflix 从 Events Infra 里进一步处理这些事件,形成混沌工程实验的完整事件的记录;
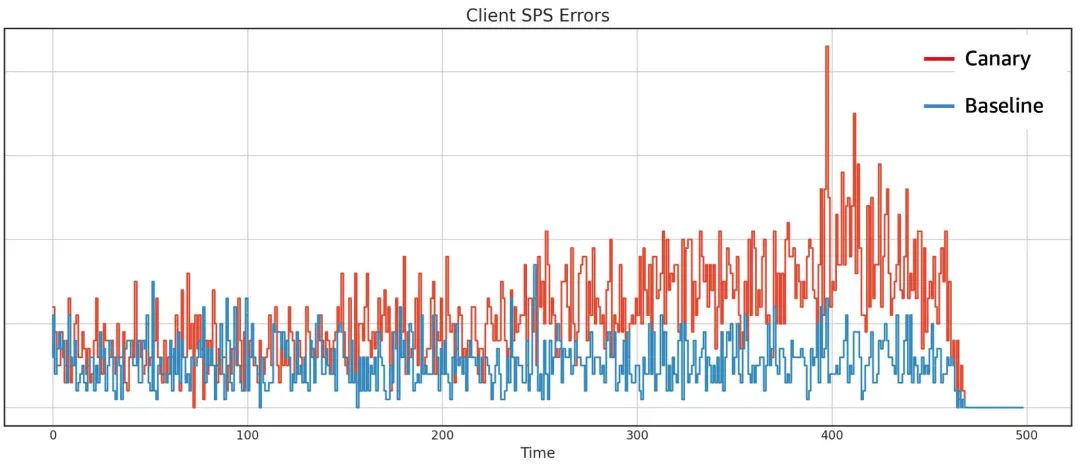
● 进一步的,可以将这些全量的事件做过滤,基于前面提到的 User Allocation 算法,将 Canary 和 Baseline 的请求事件过滤出来,做近一步的处理。
• 一部分推送到 Elasticsearch,分析这些设备发生了什么,并聚合转换为监控系统指标。例如,我们进行了一项实验,导致客户端设备的 SPS 错误,随着这些事件的收集和聚合处理,我们可以看到事件发生的数量。在实际的混沌工程实验中,Netflix 不仅对照 SPS 指标,还会针对各维度的指标进行对照;
• 同时,通过对照这些聚合指标,及时地停止异常的实验,例如 Canary 和 Baseline 版本的错误率保持一致或接近一致,我们可以继续实验。但如果看到 Canary 版本的错误高于 Baseline 版本的数量,那么就需要停止实验。这个监控系统能够分析秒级粒度的数据,所以几秒内,Netflix 就能关闭有问题的实验。

到这里,Netflix 已经从一个简单的 Chaos Monkey、到 Gameday、单用户 FIT Session,演进到了 ChAP (Chaos Automation Platfor) 自动化的混沌实验平台,工程师已经可以精确自动地进行混沌工程的实验。因此让我们回顾下 Netflix 到达 ChAP 所需的技术:
● 在 Zuul 网关的 FIT Filter 中,标记特定的请求,结合 Custom Request Routing 将这些请求路由到指定的地方;
● 使用 Canary 金丝雀策略,以及 Scope 和 Treatment 定义实验仅适用于 Canary 金丝雀集群;
● 使用 User Allocation 算法,对会员设备进行 hash,将一定范围的用户设备分配到混沌工程实验,在监控系统中通过过滤事件,精确定位和观察实验的运行情况;

在这里我们可以看到在运行的针对订阅用户的实验,模拟了当年发生的一样的故障。Netflix 称这种混沌工程实验为 Sticky Canary (粘性金丝雀),它为混沌工程提供了非常好的精度和安全性。今天,任何一个 Netflix 的工程师都可以使用该工具设置一个实验,选择一个特定的 FIT 场景,并在生产环境中随机运行该实验。如果有异常,及时地停止实验,进行深入分析调查。以前花费数小时时间,一组人坐在会议室里的实验,现在可以在几分钟内自动完成。
所以,ChAP 是个了不起的运行混沌实验的平台,它能够衡量任何软件变更对用户会员的影响,这种变更在复杂的微服务系统中的影响类似蝴蝶效应,很难预估。每当他们推动新的软件变更运行 Canary 时,这是他们能真正确定对 SPS 和会员体验有没负面影响的方法。
2.5 Netflix 的工程师如何在 ChAP 上操作实验
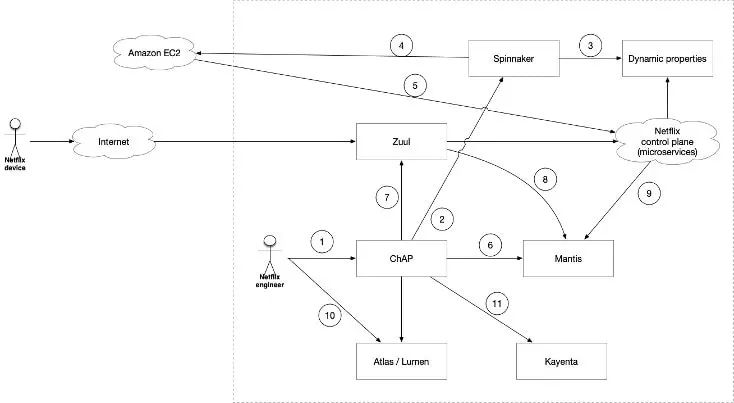
ChAP 实际上是⼀个 FIT 编排系统,它与许多 Netflix 内部服务交互以进行实验。ChAP 利用 FIT 在应⽤程序级别进⾏故障注入。让我们来通过上图解释 Netflix 如何在 ChAP 上进行自动化的混沌工程实验:
① 工程师在 ChAP 上编排应用实验;
② ⾸先调用 Spinnaker 持续发布平台创建实验环境;
③ Spinnaker 在集群实例启动前复制或创建集群运行需要的动态配置(理解为微服务配置中心配置);
④ 创建 Canary 和 Baseline 集群供实验对照,每个集群包含少量的 EC2 实例;
⑤ 集群实例启动完成时将向控制平面注册服务 Endpoint;
⑥ Mantis 是 Netflix 内部的一个实时流处理引擎。ChAP 还创建 Mantis 作业,用于对 Canary 和 Baseline 集群以及用户设备的事件、Trace 进行实时处理,并反馈给 ChAP (秒级) 来决定实验是否触发了阈值从而要被停止;
⑦ Zuul 是个 API 网关,提供请求路由、鉴权、遥测等功能,Netflix 在 Zuul 网关扩展了 Filter 用于 ChAP 的实验。注入上文提到的 Request Context,用于将请求分发到 Canary 和 Baseline 集群;
⑧ ⑨ 用户设备和控制面的微服务的观测数据会发送到 Mantis 进行处理聚合;
⑩ Atlas 是 Netflix 内部的指标聚合系统(分钟级),而 Lumen 是个 Dashboard 工具,类似现在流行的 Prometheus 和 Grafana。ChAP 使用 Lumen Dashboard 来显⽰指标数据。此数据用于分析注入的故障是否对系统健康产⽣负面影响;
⑪ 最后,ChAP 调⽤了 Kayenta,这是 Netflix 的自动金丝雀分析系统。该系统能从 Atlas 获取指标数据,并且自动分析对照 Canary 和 Baseline 集群的各方面指标和数据,生成版本的评分报告供参考;
实验完成,ChAP 将取消 Mantis Job、停止 Zuul 上的 Request Context 注入,调用 Spinnaker 拆除 Baseline 和 Canary 集群。
ChAP 支持两种使用模式:自助服务模式和自动化模式。自助服务模式中,工程师定义并运行自己的实验,ChAP 与 Spinnaker 部署系统集成,因此工程师可以将 ChAP 实验添加到他们的部署管道中 。自动化模式中,由一个集中的团队定义和并自动运行实验。
Netflix 如何扩展演进混沌工程实验
在过去的十年,Netflix 不断提高混沌实验的精度和安全性,从而达到能让工程师们受益的完美效果。Netflix 已经演进出了一种工具可以重新定义如何衡量和部署变更应用到生产的影响。Chaos 只是工具箱中众多工具的一种。所以 Netflix 从 ChAP 上的混沌实验,转向 Infrastructure Experimentation 基础设施实验(这是 Netflix 使用的术语,大家不要和通常说的“基础设施”混扰)。在 Netflix 进行这些 Infrastructure Experimentation 基础设施实验时,已经确定了很多实验用例,下面将介绍其中的一些。
3.1 Sticky Experiment
首先,这是 Sticky Experiment,Netflix 使用的一个用于衡量软件变更影响的实验,与前面介绍的实验不同,该实验不设置 Injection Point,且 Treatment 已经不是 Failure 或者 Delay,而是 Change。Change 可以是软件代码的变更、新运行实例的属性的更改,你仍然可以衡量这对会员有什么影响。

3.2 Chaos Experiment
Chaos Experiment 向该集群注入故障,这个实验不设置 Injection Point,因此整个 Canary 集群被注入了故障,因此上游服务要能很好的处理下游应用集群的消失。
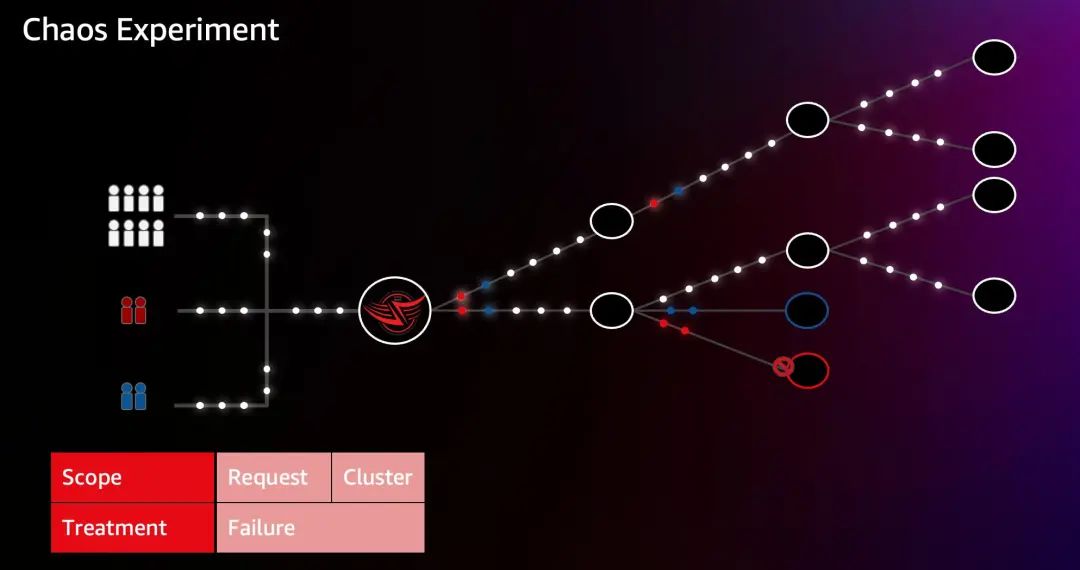
3.3 Unscoped Chaos
Unscoped Chaos 是不限定集群范围的混沌实验。这个实验很有趣,它没有确定失败或实验的范围。这个实验并不使用 Canary 集群和 Baseline 集群,而是 Canary 用户和 Baseline 用户。仍然在 Zuul 的 FIT Filter 上标记请求,带有 Canary 或 Baseline 标签,但不限制 Scope 为单个集群。而是对访问 B 服务的 gRPC 客户端进行注入。这样可以很好的模拟整个 B 服务故障的场景,通过模拟这些中断,可以快速确定某项服务的重要性,以及是否会对关键的服务或对流媒体体验产生影响。
2021年,混沌工程师和软件工程师一起在一个简单的数据服务上针对一些会员用户运行了这个实验,正当该服务的所有者说:“这不是关键路径,这个实验看起来很棒”。几分钟后,另一个工程师跑进房间说:“Black Mirror: Bandersnatch (黑镜:潘达斯奈基) 异常了”。这样我们就意识到了这项服务实际是很关键的。
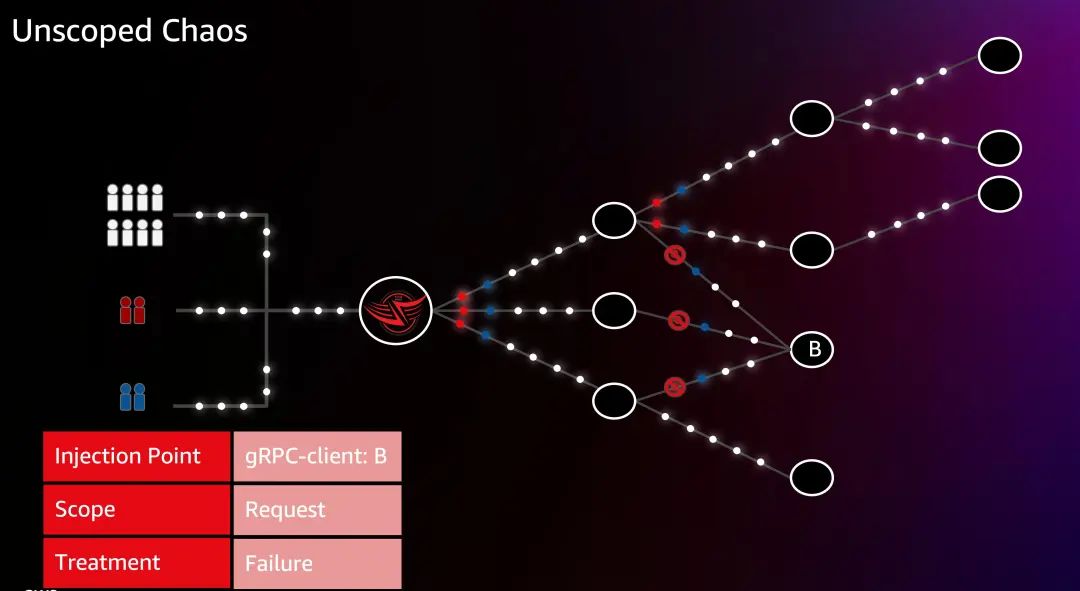
3.4 Data Experiment
另外,Netflix 有一个数据实验,这里扩展了一些方法,在 Data Experiment 实验中,提供的 Treatment 是新的数据文件。当 Canary 集群尝试访问某个数据对象时,他们得到了数据对象的新版本。这个实验可以衡量新数据对象如何影响系统。主要用于验证数据文件格式或字段调整等场景。
3.5 Squeeze Experiment
Squeeze Experiment 还是使用 Canary 策略,可以精确地控制多少的请求流量发送到每个集群,随着挤压实验的运行,我们能发现服务的不同的状态。根据这些数据,可以优化代码、提升并发、使用限流或者其他手段来优化应用性能。有助于我们实现快速的水平横向扩展、故障转移以及动态伸缩来调整成本。

3.6 Priority Load-Shedding
Priority Load-Shedding 实验在 Zuul 网关扩展了 Filter,在 Edge 侧来验证基于优先级的 Load-Shedding 算法。这里将用户分配给实验,包括被标记为 Canary 的用户群,如果他们有较低的优先级,那么就会被限制流量,有更高优先级的请求会优先通过。这样我们可以看到实验是如何影响我们的成员。

这个画面是 Priority Load-Shedding 在工作时工程师捕捉到的图像。对于低优先级的请求,可以看到它们可能获取不到一些信息,但即使错误正在发生,它们仍然能够启动流媒体会话。
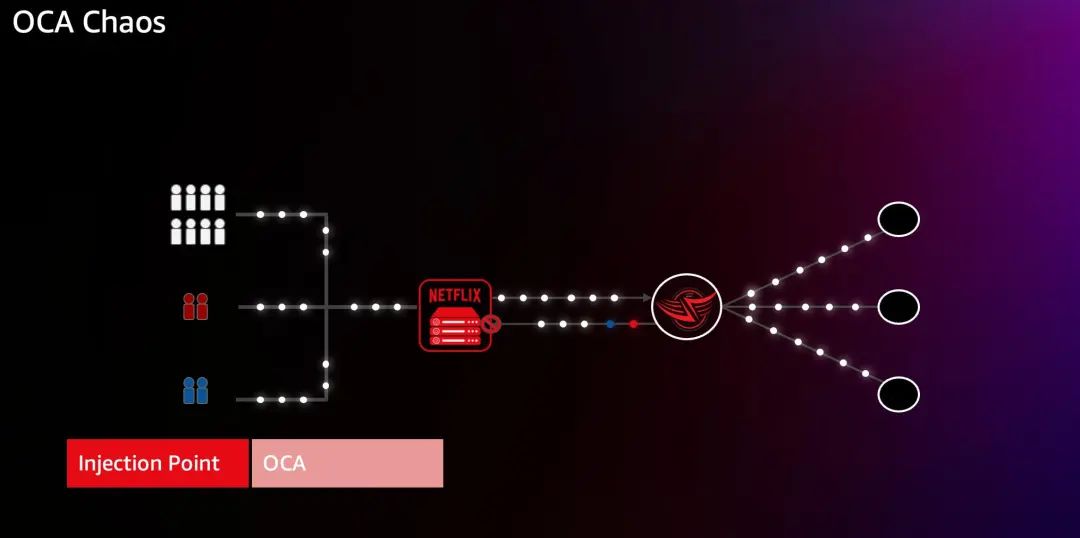
3.7 OCA Chaos
如果你还记得那些 OCA 节点(open connect appliance),它们用来在 CDN 场景下存储视频媒体内容来实现更流畅的用户体验。所以也要对它们发起混沌注入,来验证如果某个 OCA 故障用户设备仍然可以通过不同的节点重新连接,或直接到云上获取数据。这有助于我们发现 Open Connect 节点的故障如何影响我们的会员。
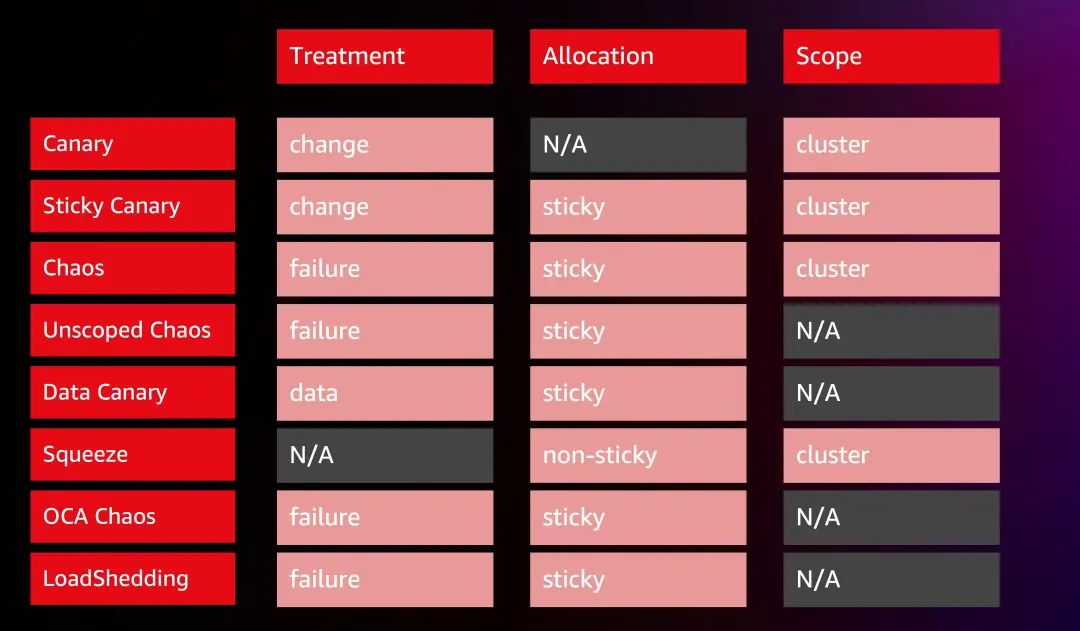
3.8 如何设计新的实验类型
如你所见,经过 Netflix 多年的演进,也扩展了许多不同的实验类型。这是一个非常模块化的方法,当 Netflix 创建新实验时,唯一改变的是这三个参数:Treatment、Allocation、Scope,可以混合搭配它们,创造出不同的实验类型和FIT场景。
● 对于 Treatment,通常可以设置 failure 或 change;
● 对于 Allocation,可以设置 sticky 或 non-sticky;
● 对于 Scope,要么设置为某个集群,要么根本不考虑范围。
每次 Netflix 的韧性团队,设计一个新的实验,只需设计一个实验类型,改变这三个参数,然后实验还可以从实时监控和内建的安全中受益。
3.9 如何在组织中构建混沌工程

如何在基础设施上构建混沌工程或者推行这种做法是一个漫长旅程,涉及到组织文化的改变、技术的改造以及工具的选择和使用。但不管在旅途中的哪个位置,还有你的公司处在什么阶段,你仍然可以采取下一步措施,例如:
● 如果你觉得自己可能会受到单个节点失败的影响,你可以尝试 Chaos Monkey 方法,你可以使用开源的 Chaos monkey,或者你可以自己关闭实例。通过将应用容器化后在 Kubernetes 上运行,也很可能你已经对节点故障具有韧性。在亚马逊云平台上你也可以使用Amazon Fault Injection Simulator 来模拟这些故障;
Amazon Fault Injection Simulator:
https://aws.amazon.com/fis/
● 然后下一阶段是 Canary,这本身是非常好的技术,您可以在您的组织中使用,并真正的从该技术中获益。当你在 CI/CD Pipeline 中开始使用 Canary,这是开发部署的重大演进,因为你已经在观测并比较 Baseline 和 Canary 版本的表现;
● 当你尝试混沌工程,Tracing 也是一项重要而且有趣的技术。因为如果你使用像 Zipkin 这样的技术,你的 Request Header已经通过基础设施传播,这样你就可以将一些自定义的标头加入这些请求。随着 OpenTelemetry 可观测技术的标准化,除了在基础设施之间传播 Request Header,也有很多成熟的方法将实验的 Trace、Logs、Metrics 数据进行过滤和关联;
● 最后,故障注入也是可以添加到组合中,除了编程语言的微服务框架,相比10年前现在有更多的技术选择,Service Mesh 和 Envoy 已支持一些基本的故障注入,例如在 Service Mesh 或者 Envoy 的 Sidecar 基于 Request Header 进行故障注入。
3.10 基础设施实验小结
回顾 Netflix 的混沌工程和 Infrastructure Experimentation 基础设施实验,我们可以小结一下:
● 单一的混沌工程师角色,最初只关注与实例相关的故障,使用 Chaos Monkey 进行实验。逐步演进出 Chaos Monkey 军团,甚至诞生了最具破坏力的 Chaos Kong 用于模拟 Region 级别故障;
● 建立 FIT 平台,丰富和规范实验场景。除此之外,工程师还能借助 FIT 进行 Fault Injection Testing;
● 进一步通过 ChAP 运行 Canary 实验,可以在任何服务上运行实验且确保实验精度和安全性;
● 变更型(Change)的实验,在做变更时被运行,验证变更对用户的影响;
● 挤压实验(Squeezes),一个月运行一次,观测系统随压力增大带来的影响,用于优化应用性能和弹性;
● Unscoped 混沌实验,每个季度运行一次,当你需要验证服务是关键还是非关键时这是一个非常好用的实验;
● 数据金丝雀实验,用于验证新的数据对象版本对用户的影响;
● Priority Load Shedding 实验,用于帮助 Netflix 了解不同的请求优先级对订阅用户的影响。
总结
本文以技术的视角,阐述 Netflix 如何在大规模的复杂系统里,在不影响创新的情况下,通过混沌工程提升系统的安全和稳定性。作为这个行业的领导者,Netflix 的成功并不在于消除系统的复杂性,而是接受复杂性,通过以下原则不断探索验证复杂未知:
● 建立一个围绕稳定状态行为的假说:Netflix 使用 Stream Per Second 作为 KPI 来建模稳态行为,在设计实验时假设“在条件 X 时,对于服务 Y,客户仍然能正常播放视频流”;
● 多样化真实世界的事件:在 Netflix 的实践中,设计了很多实例故障、延迟增加、服务失效、回退未被正常处理等真实场景,通过实验进行验证,将可能影响系统运行的不确定复杂因素变为确定;
● 在生产环境中运行实验:Netflix 的系统十分庞大、复杂、时刻变化,以至于在预生产环境无法提供完整环境。通过在生产环境运行混沌实验、测试左移,建立应付复杂系统和故障的信心;
● 持续自动化运行实验:频繁的运行手动试验始终不可持续,Netflix 通过 ChAP 建设了自动化的混沌实验平台,从实验编排到自动部署、实验观测数据的收集、对比和分析,减少执行混沌工程实验的成本;
● 最小化爆炸半径:Netflix 通过 ChAP 启动新 Canary 和 Baseline 集群,向其分配少量的流量(每次最多不超过5%流量),可以安全的减少爆炸半径。如果指标的变化达到了设定的阈值会立即停止实验,确保影响不会扩大。而且通过环境的隔离,可以同时运行多个不同实验。另外,所有的混沌实验都会在工作日进行,确保一旦出了问题可以有人员立刻来解决。
所以今天,混沌工程的目的是在确保系统韧性同时使软件工程师尽可能快的创新。
参考资料
● Amazon re:Invent 2022 – The evolution of chaos engineering at Netflix (NFX303)
https://www.youtube.com/watch?v=Xbn65E-BQhA
● Principles of Chaos Engineering – Netflix – SRECon2017
https://www.youtube.com/watch?v=6ilMZqKdMMU&t=1820s
● 混沌工程原则 (PRINCIPLES OF CHAOS ENGINEERING)
https://principlesofchaos.org/zh/
● Automated Canary Analysis at Netflix with Kayenta
https://netflixtechblog.com/automated-canary-analysis-at-netflix-with-kayenta-3260bc7acc69
● Building Netflix’s Distributed Tracing Infrastructure
https://netflixtechblog.com/building-netflixs-distributed-tracing-infrastructure-bb856c319304
● ChAP: Chaos Automation Platform
https://netflixtechblog.com/chap-chaos-automation-platform-53e6d528371f
● Keeping Netflix Reliable Using Prioritized Load Shedding
https://netflixtechblog.com/keeping-netflix-reliable-using-prioritized-load-shedding-6cc827b02f94
● Automating chaos experiments in production
https://blog.acolyer.org/2019/07/05/automating-chaos-experiments-in-production/
● Chaos Engineering — Review Lineage Driven Failure Injection (LDFI)
https://medium.com/becloudy/chaos-engineering-review-lineage-driven-failure-injection-ldfi-a1c831abe504
● Chaos Engineering — Surviving the failures in Distributed Systems
https://medium.com/becloudy/chaos-engineering-surviving-the-failures-in-distributed-systems-5688c6905dbb
本篇作者

林旭芳
亚马逊云科技解决方案架构师,主要负责亚马逊云科技云技术和解决方案的推广工作,在 Container、容灾等方向有丰富实践经验。

谷雷
亚马逊云科技资深解决方案架构师,专注于迁移上云、云上业务连续性的实现等技术方向。

李俊杰
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案的咨询与架构设计,同时致力于容器方面研究和推广。在加入亚马逊云科技之前曾在金融行业 IT 部门负责传统金融系统的现代化改造,对传统应用的改造,容器化具有丰富经验。


听说,点完下面4个按钮
就不会碰到bug了!















 8481
8481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









