







概述
本文将介绍 37Games 在亚马逊云科技上采用的 Multi-Region 双活架构,利用 Amazon 托管服务 Amazon Route53 、 Amazon CloudFront 、 Aurora Global Database 和 DynamoDB Global Tables 等实现了流量分配、数据同步和容灾切换,大幅提高了游戏平台的可用性、容错能力和灾备能力。这种架构设计充分利用了云上服务的优势,是游戏平台服追求高可用和业务连续性的一个很好的实践案例。
游戏平台服及其架构设计
游戏平台服务是为游戏提供关键支持服务的核心系统,负责管理玩家账号、处理支付流程等关键任务。一旦平台服发生故障不可用,将直接影响到所有接入平台的游戏,这些游戏的玩家可能无法注册、登陆和充值,导致游戏运营商信誉受损并遭受经济损失。因此,游戏平台服在架构设计上需要更加注重高可用以及容灾能力。
游戏平台服的技术栈通常和游戏服的技术栈有一定的差异,它更类似于互联网的 HTTP 服务,通常由三层架构发展而来,现在大多使用 Kubernetes 容器化部署。
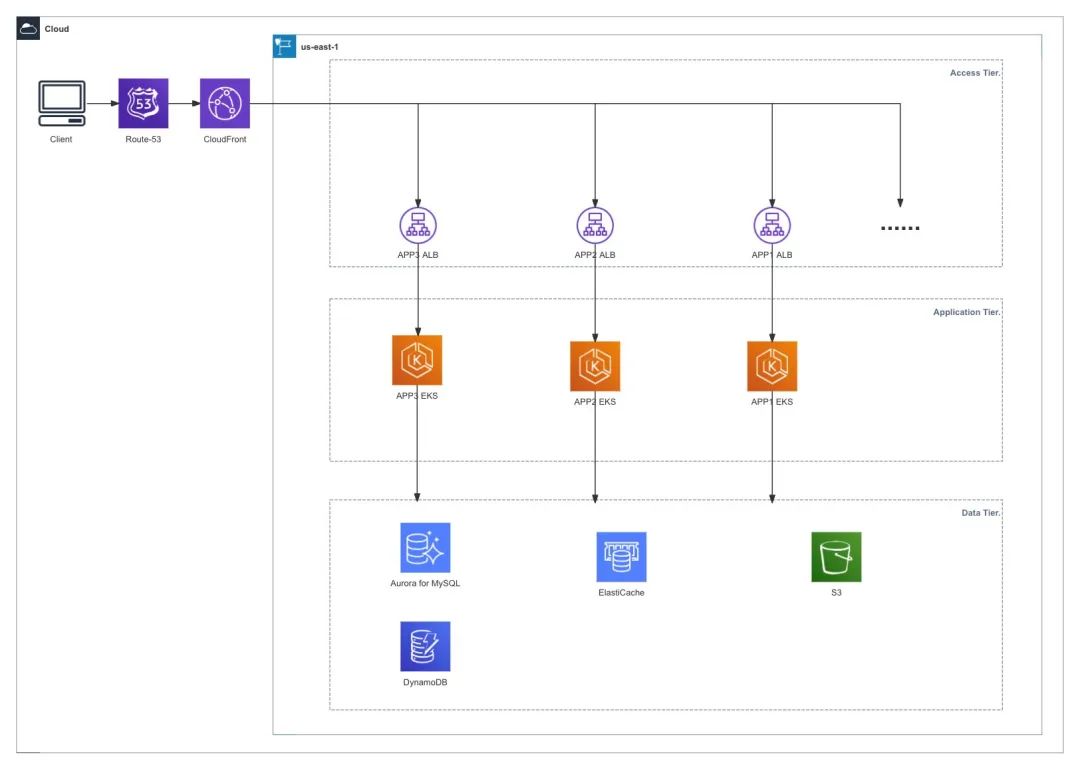
以下是一个在 Amazon 上最简化的平台服架构示例,主要包括三层:
Access Tier :作为不同业务程序的流量入口,将请求路由到相应的业务程序。对于 HTTP 服务通常使用 Amazon CloudFront 进行全球动态请求的加速,使用 Application Load Balancer(ALB) 作为不同业务模块的入口。

Amazon CloudFront
扫码了解更多

Application Load Balancer
扫码了解更多
左右滑动查看更多
Application Tier :实现各种业务逻辑,比如注册、登陆、充值、运营活动等。这些服务通常采用无状态设计,并使用 Amazon Elastic Kubernetes Service 进行容器化部署。

Amazon Elastic
Kubernetes Service
扫码了解更多
Data Tier :存储和管理业务数据以及缓存。根据不同业务类型的需求,Data Tier 通常包括关系型数据库如 Amazon Aurora 、 NoSQL 数据库如 Amazon DynamoDB 和 Amazon ElastiCache 以及对象存储 Amazon S3 等。

Amazon Aurora
扫码了解更多

Amazon DynamoDB
扫码了解更多

Amazon ElastiCache
扫码了解更多

Amazon S3
扫码了解更多
左右滑动查看更多
从传统的三层架构发展而来的游戏平台服务通常面临着诸多可用性挑战,而随着各种云平台控制面和数据面故障的日益频发,这些挑战变得更加严峻。
诸如机房电力、温度控制系统等硬件故障,地震、龙卷风等自然灾害,网络链路故障等因素,都极大影响着游戏平台服的可用性。
而我们可以依赖 Amazon 各种托管服务的 resilience feature ,应用 Amazon Well-Architected 的最佳实践和设计原则,在原本的游戏平台服基础上进行架构优化,更好地提升架构的韧性。
Multi Region 双活平台服架构
架构概览
37Games 平台服架构采用 Multi Region 双活设计,不仅考虑到了单个 IDC 机房、单个 AZ 的故障,也考虑到的 Region 级别的灾难恢复,相较于单个 Region 部署具有更高的韧性,同时两个 Region 都会承载线上玩家的流量,保证了两个 Region 的环境是一致可用的,依赖云上的弹性可以实现任何一个 Region 都可以在很短时间内进行扩容,承载所有玩家流量。
以下是 Multi Region 的架构示意图:
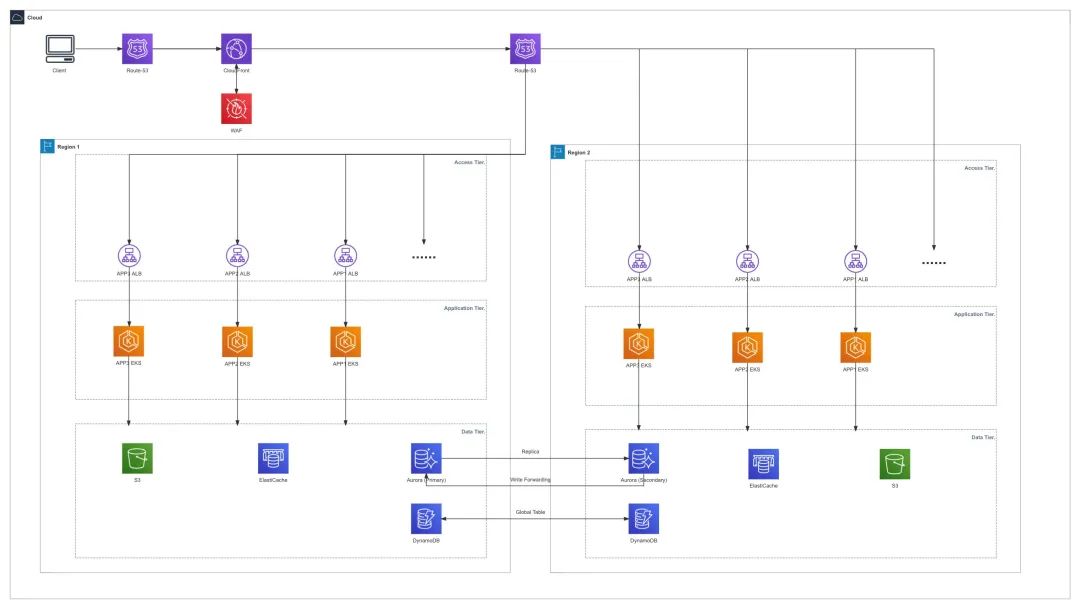
Multi Region 双活相较于传统三层架构不同的是,在两个 Region 都部署了相同的业务,需要在 Access Tier 和 Data Tier 解决入口流量分配以及数据同步的问题。
这个架构整体的概览如下:
Access Tier :在流量入口处使用 Route53 和 CloudFront 的组合来实现玩家流量就近接入,并且按照一定的策略分配给不同的 Region ;
Application Tier :更新 CI/CD 流程以保证两个 Region 的业务代码是一致的;
Data Tier :依赖 Amazon Aurora Global Database 和 Amazon DynamoDB Global Tables 的能力,实现关系型数据和非关系型数据的跨 Region 同步。

Amazon Aurora
Global Database
扫码了解更多

Amazon DynamoDB
Global Tables
扫码了解更多
左右滑动查看更多
Access Tier 流量分配
在 Access Tier 处进行流量分配可以有多种策略,如按权重、延迟、来源 IP 的地域等,同时如果使用了 CloudFront 来实现玩家就近接入,那么还需要规避一个 duplicate domain names 的限制。

duplicate domain names
扫码了解更多
以下是 Access Tier 的参考架构:
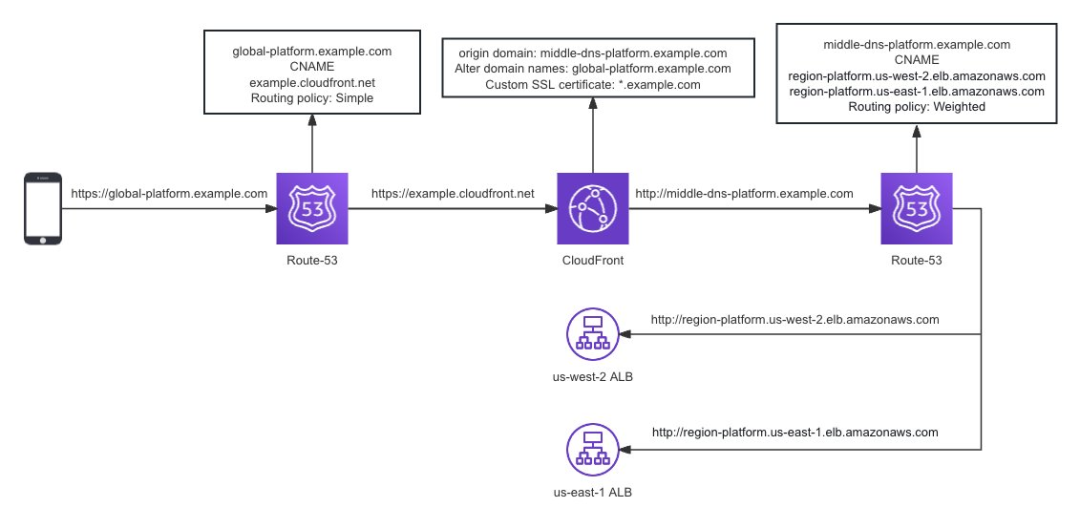
Access Tier 部署配置以及玩家流量分发的过程如下:
1、玩家访问游戏发行方域名的地址(比如 https://global-platform.example.com ) ;
2、在 Route53 上将游戏发行方的域名通过 simple policy CNAME 到 CloudFront 域名(比如 cloudfront.net );
3、配置 CloudFront 的 Origin 为一个域名(比如 middle-dns-platform.example.com ),并且配置 CNAME( global-platform.example.com )的 SSL 证书。这样做的目的有三个:
实现玩家就近接入,让玩家的流量大部分时候在 Amazon 骨干网上进行传输,保证玩家的网络质量;
将 SSL 证书认证过程卸载到 CloudFront 边缘节点;
将 Origin 配置成域名而非真实的业务入口,可以通过 Route53 的能力进行更灵活的流量分配策略(比如 weight )。
4、玩家的流量从 CloudFront 的边缘节点完成 SSL 认证后进入 Amazon 骨干网,CloudFront 会把流量回源到 middle-dns-platform.example.com ;
5、在 Route53 中给 middle-dns-platform.example.com 配置更灵活的路由策略,比如按一定的比例分别路由到不同的 Region 。
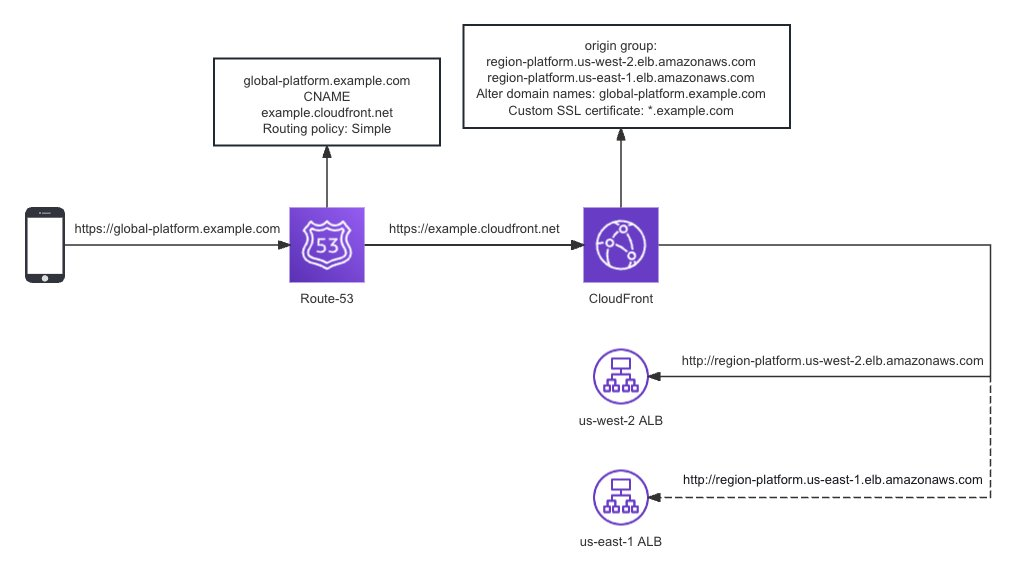
上面的 Access Tier 架构可以实现多个 Region 的双活,如果只需要有 Failover 的能力,可以将架构简化,直接在 CloudFront 处配置 Origin Failover 。

Origin Failover
扫码了解更多
Data Tier 数据同步
在 Multi Region 双活的架构中,数据的同步是非常重要的,在这里面需要考虑数据一致性、读写性能、disaster recovery 等诸多问题。
Data Tier 中需要进行同步的重要数据既包括关系型数据,也包括 NoSQL ,而 Aurora Global Database 和 Amazon DynamoDB Global Tables 作为托管服务的特性,可以很好地解决 Multi Region 数据同步的问题。
Aurora Global Database
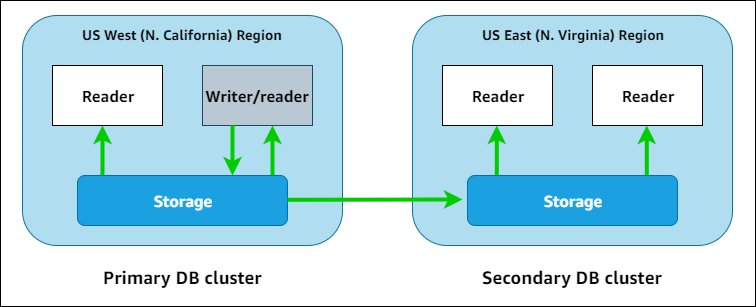
Aurora Global Database 可以实现一个 Aurora 跨越多个 Region 进行数据同步:
它包含了 1 个 Primary Region 和多个 Secondary Region ;
所有的写入操作最终都会在 Primary Region 进行落盘,Secondary Region 可以在本地的 Endpoint 进行写入,通过 Write forwarding 的方式将写入操作通过 Amazon 骨干网转发到 Primary Region ;
所有的 Region 都可以在本地进行极低延迟的读操作,Secondary Region 和 Primary Region 的数据同步是 storage-based 而非通过数据库引擎,并且数据同步流量是全部在 Amazon 骨干网上,通常延迟低于 1s 。
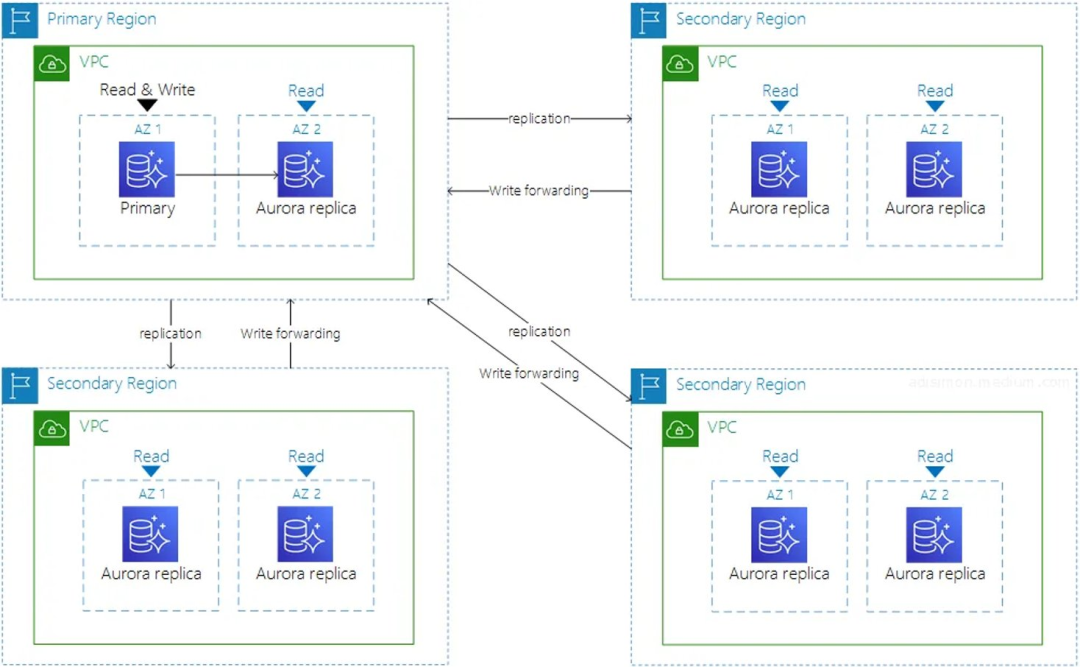
应用在进行 Write forwarding 时,需要指定 Aurora_replica_read_consistency 参数,不同参数会影响着 Secondary Region 的应用看到数据的延迟:
EVENTUAL :应用通过 Write forwarding 写入数据后,在本地看到刚刚写入的数据可能会有短时间的延迟,因为需要在 Primary Region 落盘并同步到 Secondary Region 后才能在本地可见;
SESSION :Write forwarding 数据提交后还没落盘, Aurora 会将 DML 的变更快照到当前计算节点的内存,使得相同 session 可以很快读到刚刚做的变更,数据延迟最低。如果 TPS 较高则会比较耗资源,因为每个 session 都要把变更快照进计算节点的内存。同时如果用了 RDS proxy , Write forwarding 不建议使用 session 一致性,因为同一个程序通过 RDS proxy 连数据库可能会分配到其他的 session ,无法固定 session 拿到刚刚 DML 的数据;
GLOBAL :提供数据最大的保护,全球数据都同步后才可以读到,因此数据延迟最大。
Aurora Global Database 的 Primary Cluster 还有一个参数控制着 writer 节点可以分配百分之多少的连接数给 Write forwarding:
Aurora_fwd_master_max_connections_pct (Aurora MySQL version2) ;
Aurora_fwd_writer_max_connections_pct (Aurora MySQL version3) 。
DynamoDB Global Tables
DynamoDB 作为 Serverless 的 NoSQL 数据库,提供全托管的 Global Tables 特性,可以在多个 Region 提供多活的 DynamoDB Read/Write Endpoint 。
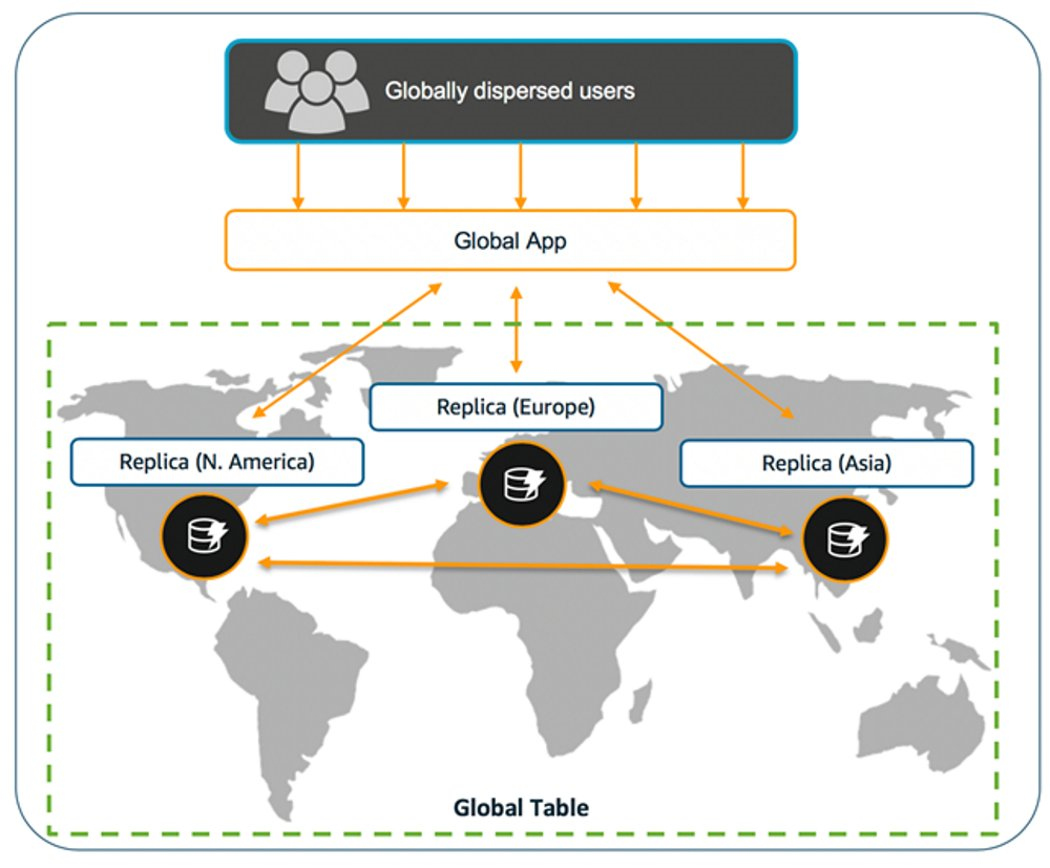
在 Global Tables 的任何一个 Region 写入的数据都会同步到其他 Region ,而对于数据冲突的解决,比如多个 Region 同时写入相同的 item ,Global Tables 采用的是 last-writer-wins 策略,即以最后一个写入为准。
对于游戏平台服的业务,我们可以在一些场景给写入 item 的 key 加上相关 Region 的 prefix/suffix ,以此来避免数据冲突问题。
Multi Region 双活平台服
容灾切换
任何未经测试的容灾策略,都不是真正的容灾策略。基于上述的架构,可以帮助我们很好地进行容灾演练:
Data Tier :在故障时进行 Aurora Global Database 的 Failover ,将 Primary Cluster 从故障 Region 切到其他的 Region ;而 DynamoDB 的 Global Tables 不需要做任何操作。
Access Tier :可以根据具体故障的 Region 来调整玩家流量的入口。
对于切换流量入口以及业务代码逻辑处理的过程这里不做介绍,这里仅介绍 Aurora Global Database 的 Failover 过程。
Aurora Global Database Failover
当 Aurora Global Database 的 Primary Region 发生故障时 Failover 的过程时这样的:
选择一个 Secondary Cluster ,它的一个 read replica 被提升为 write instance ,这个 Secondary Cluster 此时在 Global Database 的拓扑中变成 Primary ;
Aurora Global Database 持续监控 old Primary Region ,一旦它可用就把它加回到 Global Database 拓扑,此时会通 restore 当前 Primary Region 的 snapshot 的方式来恢复 old Primary Region Cluster ;
恢复过程耗时从几分钟到几个小时,取决于数据量大小 (storage volume) 和物理距离 (region distance) 。
本篇作者

王睿
亚马逊云科技高级解决方案架构师,从事过 SRE 以及 Game SDE ,在游戏和云计算行业有丰富的实践经验。

张辉
三七互娱高级运维工程师,主要负责 37GAMES 海外发行平台的运维。擅长设计高可用架构,善于优化系统性能和稳定性,致力于提升平台的可用性,确保用户获得流畅的游戏体验。

李标云
三七互娱数据库工程师,主要负责 37GAMES 海外发行平台的数据库运维工作,专注于 MySQL 、 Redis 、 Kafka 等数据库产品,具备丰富的多云数据库维护经验。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
点击阅读原文查看博客,获得更详细内容
听说,点完下面4个按钮
就不会碰到bug了!

















 8596
8596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









