







前言
Amazon SageMaker 是亚马逊云科技提供的一个全面的机器学习平台。它支持从构建、训练和部署机器学习模型到监控和自动模型调优的整个机器学习工作流程。利用 Amazon SageMaker HyperPod,用户可以像使用 Amazon EC2 实例一样快速启动、登录各种 GPU 资源 (如 G5 A10、P4 A100、P5 H100…...) 并进行 LLM 或 SD 等模型的分布式训练和推理部署。
LLaMA-Factory 是开源社区一套大模型集成训练框架。本文中我们将结合代码和示例,介绍如何使用 LLaMA-Factory 在 Amazon SageMaker HyperPod 上训练大模型,熟悉 Amazon SageMaker HyperPod 集群创建和多机多卡分布式训练方法。
简介
1
Amazon SageMaker HyperPod 简介
Amazon SageMaker HyperPod 集群是一种分布式训练平台,它支持持续数天、数周甚至数月的开发和训练任务,可以将训练时间缩短多达 40%。
HyperPod 采用基于 Slurm 的 HPC 高性能弹性计算集群,能够实现单机或跨机器跨 GPU 的大规模并行训练。它提供原生的基于 GPU 或 CPU 的基础设施,您可以自由操控或部署任意框架,充分发挥亚马逊云科技上服务可伸缩的计算能力,线性扩展训练吞吐量。
HyperPod 预配置了 Amazon SageMaker 分布式训练库,能自动将训练工作负载拆分到数千个 GPU 上并行处理,提高训练性能。它还通过自动定期保存 Checkpoint,支持数周或数月的无中断训练;当硬件故障时会自动检测、修复或更换有故障实例,从上次检查点恢复训练,无需任何手动管理,以保证任务的持续、稳定运行。

Amazon SageMaker
HyperPod 集群
扫码了解更多
2
LLaMA-Factory 介绍
LLaMA-Factory 是开源社区一套大模型集成训练框架,支持:
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Baichuan等等
集成方法: (增量) 预训练、 (多模态) 指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等
多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调
先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调
因此 ,LLaMA-Factory 结合 Amazon SageMaker,也可以应用于其他模型和其他的训练方法。充分利用 Amazon SageMaker 托管服务,可以无需关注资源的系统配置,并且可以按需启动训练任务,训练完成后自动清退节点资源,无需长期占用资源,带来更加便捷,经济的训练。

LLaMA-Factory
扫码了解更多
创建 HyperPod 集群
接下来我们将以 HyperPod 做分布式训练大模型的例子,创建一个包含 2 台 g5.12xlarge (单台 4 张 GPU 卡) 集群。
1
Notebook 实例工作环境准备
(为创建和管理 HyperPod 的工作环境)
下载 Amazon CloudFormation 配置文件,在 Amazon CloudFormation 中使用这个配置文件,启动一个 Amazon SageMaker Notebook 实例。该配置文件已经预置了 HyperPod 必要的权限,使用该配置文件创建一个 Notebook 实例可以避免手动去设置 IAM policy 等操作。
在 Amazon SageMaker Notebook jupyterlab 中,打开一个 terminal。

Amazon CloudFormation
配置文件
扫码了解更多
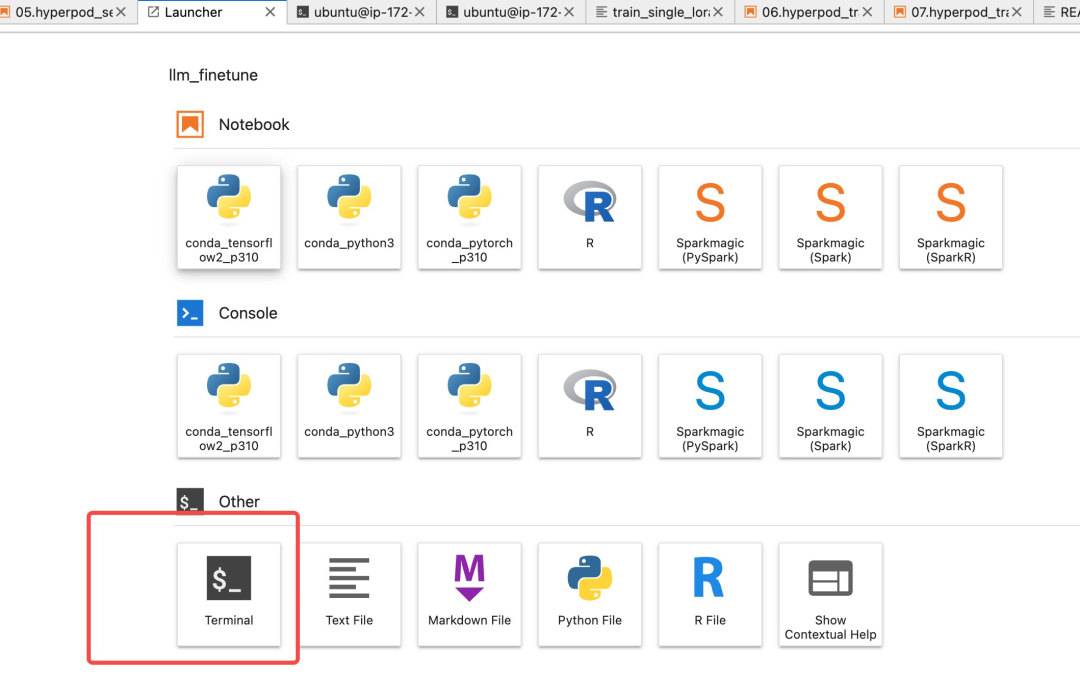
终端打开后,进入 Amazon SageMaker/ 目录,运行一下命令下载相关的代码。
cd SageMaker/
git clone --recurse-submodules https://github.com/aws-samples/Easy_Fintune_LLM_using_SageMaker_with_LLama_Factory左右滑动查看更多
2
下载官方 lifecycle 配置文件,
并上传到 Amazon S3 存储桶中
!注意替换{bucket},必须以“sagemaker”作为前缀,所以可以使用 Amazon SageMaker 默认的 bucket,例如 sagemaker-us-west-2-434444145045 的形式。
aws s3 cp --recursive awsome-distributed-training/1.architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/ s3://{bucket}/hyperpod/LifecycleScripts/左右滑动查看更多
3
创建集群 provisioning 配置文件,
并上传到 Amazon S3 存储桶
写一个 Slurm 配置文件并将其另存为 provisioning_parameters.json。在文件中,指定基本的 Slurm 配置参数,以便将 Slurm 节点正确分配给集群实例组。
本示例中,我们创建 2 个组,分别是控制组和工作组,设置组名为
my-controller-group
worker-group-1
也可以创建多个 worker-group,不同的 group 可以使用不同类型的实例。
另外 partition_name 表示节点分区,可以结合用户组来控制资源的使用权限。
如以下示例配置所示。provisioning_parameters.json。
%%writefile lifecycle-scripts/provisioning_parameters.json
{
"version": "1.0.0",
"workload_manager": "slurm",
"controller_group": "my-controller-group",
"worker_groups": [
{
"instance_group_name": "worker-group-1",
"partition_name": "partition-1"
}
]
}左右滑动查看更多
把该文件 copy 至 S3 中。
aws s3 cp —recursive lifecycle-scripts/ s3://{bucket}/hyperpod/LifecycleScripts/左右滑动查看更多
4
准备一个 create_cluster.json 文件,
用于使用 Amazon CLI 命令行创建
HyperPod 集群
例如,以下配置文件将创建一个 ml.c5.xlarge*1+ml.g5.12xlarge*2 的集群。
#替换成实际的集群名称
cluster_name = "hyperpod-cluster-1"
SourceS3Uri = f"s3://{bucket}/hyperpod/LifecycleScripts"
worker_instance = "ml.g5.12xlarge"
worker_count = 2
create_cluster = \
{
"ClusterName": cluster_name,
"InstanceGroups": [
{
"InstanceGroupName": "my-controller-group",
"InstanceType": "ml.c5.xlarge",
"InstanceCount": 1,
"LifeCycleConfig": {
"SourceS3Uri": SourceS3Uri,
"OnCreate": "on_create.sh"
},
"ExecutionRole": role,
"ThreadsPerCore": 1
},
{
"InstanceGroupName": "worker-group-1",
"InstanceType": worker_instance,
"InstanceCount": worker_count,
"LifeCycleConfig": {
"SourceS3Uri": SourceS3Uri,
"OnCreate": "on_create.sh"
},
"ExecutionRole": role,
"ThreadsPerCore": 1
}
]
}
with open("create_cluster.json","w") as f:
json.dump(create_cluster,f)左右滑动查看更多
在 Notebook 中运行以下命令来创建集群,注意 file:// 后面是 create_cluster.json 的绝对路径。
!aws sagemaker create-cluster --cli-input-json file://~/SageMaker/llm_finetune/create_cluster.json左右滑动查看更多
大概等待 12—13 分钟之后,集群成功拉起之后,可以在 Amazon SageMaker HyperPod 控制台看到启动成功的集群。如图所示:
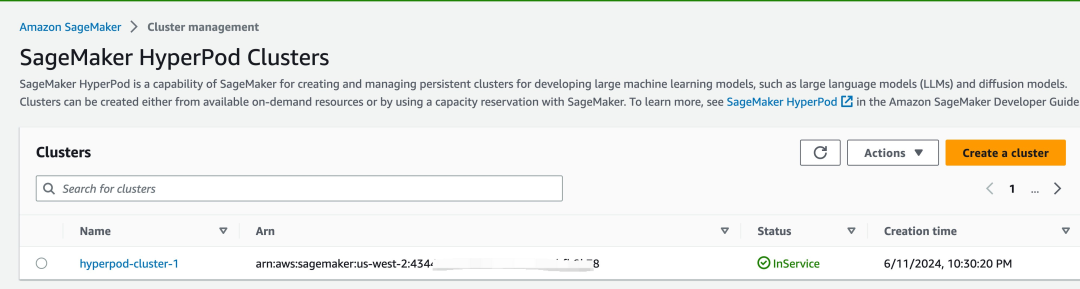
也可以在 Notebook 终端中运行以下命令,查看集群信息:
aws sagemaker list-clusters
#替换成实际的集群名称
cluster_name=hyperpod-cluster-1
aws sagemaker list-cluster-nodes --cluster-name {cluster_name} --region us-west-2左右滑动查看更多

设置远程访问 HyperPod 集群
1
通过 Amazon Systems Manager (SSM) 访
问集群,并且通过脚本 easy-ssh.sh
连接集群节点
如果在您的本地主机远程访问集群,则需要下载 easy-ssh.sh 到本地主机,另外本地主机需要配置好 Amazon Credentials 的 access key/secret access key,且需要相关的权限,具体参考这个 policy。
如果在上述已经部署好的 Amazon SageMaker Notebook 实例中访问集群,由于启动时已经预置了权限,无须在额外设置。
如果在本地主机访问,请升级最新的 Amazon CLI 工具,升级参考链接。
安装 ssm plugin。

easy-ssh.sh
扫码了解更多

access key/secret access key
扫码了解更多
左右滑动查看更多
sudo yum install -y https://s3.amazonaws.com/session-manager-downloads/plugin/latest/linux_64bit/session-manager-plugin.rpm左右滑动查看更多
使用 easy-ssh.sh 脚本登录到 worker-group-1 的计算节点 (后续的设置和训练任务,我们将直接在计算节点操作) 。
chmod +x easy-ssh.sh
./easy-ssh.sh -c worker-group-1 hyperpod-cluster-1左右滑动查看更多
成功执行上述脚本之后,已经登录到了集群中的一个计算节点,并出现以下结果。

2
设置 SSH 代理访问
以及 vs code 远程调试
上一步完成之后,在本地机器或者 Notebook 实例中,编辑 ~/.ssh/config,把上面打印 Host hyperpod-cluster-1 的那段加入到 config 最后,或者直接复制出命令在终端执行。
$ cat <<EOF >> ~/.ssh/config Host <cluster-name> User ubuntu ProxyCommand sh -c "aws ssm start-session --target sagemaker-cluster:<cluster_id>_<node-group>-<instance_id> --document-name AWS-StartSSHSession --parameters 'portNumber=%p'" EOF左右滑动查看更多
在本地机器或者 Notebook 实例中,生成 public key。
ssh-keygen -t rsa -q -f "$HOME/.ssh/id_rsa" -N ""
cat ~/.ssh/id_rsa.pub左右滑动查看更多
复制 public key 并加入到集群主机的 authorized_keys 中,这样本地主机或者 Notebook 实例会与集群节点建立起互信,可以通过 SSH 访问。重新登录集群主机,打开~/.ssh/authorized_keys 文件,并发上一步生成的 public key 添加到文件的最后。
#登录到集群中,工作组为 worker-group-1 的计算节点
./easy-ssh.sh -c worker-group-1 hyperpod-cluster-1
#切换至 ubuntu 用户
sudo su - ubuntu
vim ~/.ssh/authorized_keys左右滑动查看更多
完成以上设置之后,重新回到本地机器,直接用以下命令登录到名称为 hyperpod-cluster-1,工作组为 worker-group-1 的计算节点中。
ssh hyperpod-cluster-1在 vscode 的 remote explorer 插件中会自动出现该集群 worker-group-1 组中的计算节点,登录之后即可进行远程调试。

remote explorer 插件
扫码了解更多
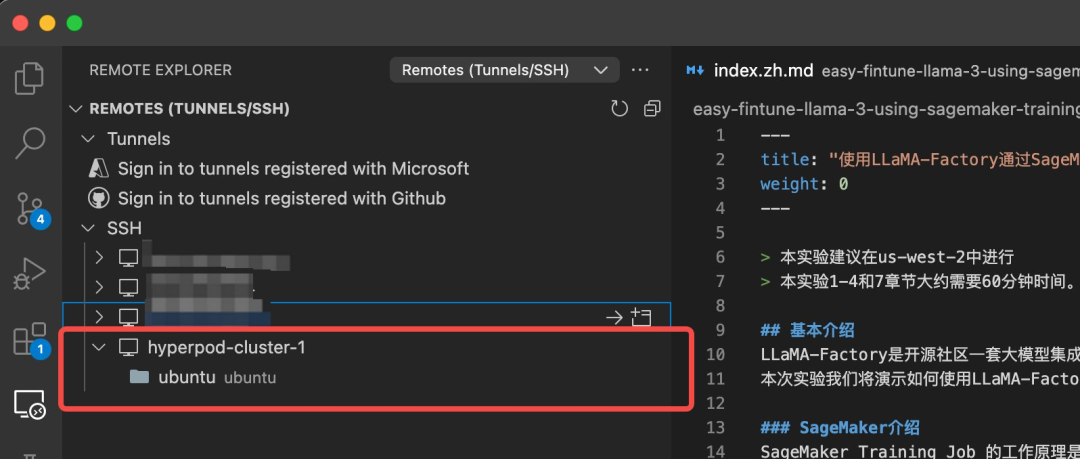
HyperPod 集群环境设置
1
上传训练脚本到 Amazon S3
在 Amazon SageMaker Notebook 实例中,打开一个 terminal
通过命令行上传训练脚本到 S3 bucket 中,之后 S3 bucket 会挂载到集群所有节点中,这样所有计算节点都可以访问训练代码和数据。
./s5cmd sync ./LLaMA-Factory s3://{bucket}/hyperpod/
aws s3 cp —recursive hyperpod-scripts/ s3://{bucket}/hyperpod/LLaMA-Factory/左右滑动查看更多
2
挂载 Amazon S3
与 Amazon EC2 实例一样,Hyperpod 集群实例上可以挂载各种共享存储,如 EFS、Lustre、S3 等,此处我们以 mount-s3 为例。
mount-s3 共享存储安装及挂载脚本示例:
仍然 SSH hyperpod-cluster-1 登录到集群节点中,执行。
###下载 s3mount
cd ~
srun -N2 "wget" "https://s3.amazonaws.com/mountpoint-s3-release/latest/x86_64/mount-s3.deb"
srun -N2 sudo apt-get install -y ./mount-s3.deb
# 挂载到"~/mnt" 中, 注意实验中用了2个计算节点,所以以下用srun -N2表示在所有节点中执行, 如果是其他数量节点,则对应修改成计算节点的数量
srun -N2 "sudo" "mkdir" "/home/ubuntu/mnt"
#在所有节点上挂载,注意region,account-id替换成您自己的aws region和 account id
srun -N2 "sudo" "mount-s3" "--allow-other" "--allow-overwrite" "sagemaker-us-west-2-434444145045" "/home/ubuntu/mnt"左右滑动查看更多
3
在集群上安装 LLaMA-Factory
仍然保持登录到集群节点中,把 S3 bucket 的目录下的代码 copy 到本地目录,该命令使用 srun -N2,意思是在 2 个计算节点上执行同样的操作。
cd ~
srun -N2 "cp" "-r" "mnt/hyperpod/LLaMA-Factory" "LLaMA-Factory"左右滑动查看更多
执行按照脚本 llama_factory_setup.sh,该命令使用 srun -N2,在 2 个计算节点上都安装 LLaMA-Factory。
cd LLaMA-Factory
srun -N2 "rm" "-rf" "../miniconda3"
srun -N2 rm - rf Miniconda3-latest*
srun -N2 "bash" "llama_factory_setup.sh"左右滑动查看更多
在 HyperPod 集群上基于
DeepSpeed 进行分布式训练
我们部署了 2 台 ml.g5.12xlarge 实例作为计算节点,因此可以在 HyperPod 集群提交训练任务,底层使用 LLaMA-Factory 集成的 deepspeed 分布式训练引擎进行训练。以 lora 微调 llama-3-8b-Instruct 为例。
1
训练数据和脚本准备
数据集准备
LLaMA-Factory 本身已经预置了多种丰富的训练数据集,可以自动从 huggingface repo 中下载,也支持自定义数据集,支持 alpaca 或者 sharegpt,需要在 LLaMA-Factory/data/dataset_info.json 注册即可。我们可以把准备好的数据集上传至 S3,然后把数据集元信息注册到 dataset_info.json 中。并在训练脚本中采用执行 s5cmd 从 S3 下载数据集到节点的本地 data 目录中。具体可以参考代码中 04.llama_factory_finetune_on_SageMaker_multi_node.ipynb 数据准备部分。
准备训练配置文件
如使用 deepspeed zero3 方式进行 lora 训练 sg_config_multl_node_lora_ds.yaml 如下。

数据准备
扫码了解更多
cutoff_len: 2048
dataset: identity,ruozhiba
ddp_timeout: 180000000
deepspeed: examples/deepspeed/ds_z3_config.json
do_train: true
eval_steps: 500
evaluation_strategy: steps
finetuning_type: lora
fp16: true
gradient_accumulation_steps: 2
learning_rate: 0.0001
logging_steps: 10
lora_target: q_proj,v_proj
lr_scheduler_type: cosine
max_samples: 1000
model_name_or_path: unsloth/llama-3-8b-Instruct
num_train_epochs: 3
output_dir: /home/ubuntu/finetuned_model
overwrite_cache: true
overwrite_output_dir: true
per_device_eval_batch_size: 1
per_device_train_batch_size: 1
plot_loss: true
preprocessing_num_workers: 16
save_steps: 500
stage: sft
template: llama3
val_size: 0.1
warmup_ratio: 0.1
warmup_steps: 10左右滑动查看更多
准备训练脚本 train_multi_ds.sh
%%writefile hyperpod-scripts/train_multi_ds.sh
#!/bin/bash
sg_config=sg_config_multl_node_lora_ds.yaml
echo "sg_config=$sg_config"
#注意把s3 bucket 替换成自己账号的地址
OUTPUT_MODEL_S3_PATH=s3://sagemaker-us-west-2-434444145045/hyperpod/llama3-8b-ds/
source ../miniconda3/bin/activate
conda activate py310
chmod +x ./s5cmd
#下载training dataset
./s5cmd sync s3://sagemaker-us-west-2-434444145045/dataset-for-training/train/* /home/ubuntu/LLaMA-Factory/data/
NODE_RANK=$SLURM_NODEID
echo "NODE_RANK=$NODE_RANK"
WORLD_SIZE_JOB=$SLURM_NTASKS
echo "WORLD_SIZE_JOB=$WORLD_SIZE_JOB"
MASTER_ADDR=(`scontrol show hostnames \$SLURM_JOB_NODELIST | head -n 1`)
MASTER_PORT=$(expr 10000 + $(echo -n $SLURM_JOBID | tail -c 4))
echo "MASTER_ADDR=$MASTER_ADDR"
echo "MASTER_PORT=$MASTER_PORT"
# get gpu count
gpu_count=$(nvidia-smi --query-gpu=gpu_name --format=csv,noheader | wc -l)
DEVICES=""
# 构建设备字符串
for ((i=0; i<gpu_count; i++)); do
DEVICES+="$i"
if ((i < gpu_count - 1)); then
DEVICES+=","
fi
done
echo "DEVICES=$DEVICES"
export DS_BUILD_FUSED_ADAM=1
export NCCL_PROTO=simple
export NCCL_DEBUG=INFO
export HCCL_OVER_OFI=1
# 使用efa
export FI_PROVIDER=efa
export NCCL_IGNORE_DISABLED_P2P=1
## 如果拉起的集群为A100/H100(P4d/P5机型)节点,可以设置如下的NCCL参数启用RDMA,以获得多机多卡训练时节点GPU更大的网络吞吐量
export FI_EFA_USE_DEVICE_RDMA=1
export NCCL_LAUNCH_MODE=PARALLEL
#依次在各个node上执行llamafactory-cli train
if [ "$NODE_RANK" == "0" ]; then
CUDA_VISIBLE_DEVICES="$DEVICES" NNODES=$WORLD_SIZE_JOB RANK=0 MASTER_ADDR="$MASTER_ADDR" MASTER_PORT="$MASTER_PORT" llamafactory-cli train "$sg_config"
else
CUDA_VISIBLE_DEVICES="$DEVICES" NNODES=$WORLD_SIZE_JOB RANK=$NODE_RANK MASTER_ADDR="$MASTER_ADDR" MASTER_PORT="$MASTER_PORT" llamafactory-cli train "$sg_config"
fi
#只在0节点执行上传模型文件至s3操作
if [ "$NODE_RANK" == "0" ]; then
echo "*****************finished training, start cp finetuned model*****************************"
./s5cmd sync "/home/ubuntu/finetuned_model" "$OUTPUT_MODEL_S3_PATH"
echo '-----finished cp-------'
fi左右滑动查看更多
上传训练脚本到 S3 bucket 中,之后 S3 bucket 会挂载到集群所有节点中,这样所有计算节点都可以访问训练代码
./s5cmd sync ./LLaMA-Factory s3://{bucket}/hyperpod/
aws s3 cp --recursive hyperpod-scripts/ s3://{bucket}/hyperpod/LLaMA-Factory/左右滑动查看更多
2
提交训练任务
按前面所述,使用 SSH 登录到集群计算节点, 把挂载的 S3 bucket 的目录下的代码更新到节点的本地目录中
srun -N2 "cp" "-r" "mnt/hyperpod/LLaMA-Factory/train_multi_ds.sh" "LLaMA-Factory/train_multi_ds.sh"
srun -N2 "cp" "-r" "mnt/hyperpod/LLaMA-Factory/train_batch.sh" "LLaMA-Factory/train_batch.sh"左右滑动查看更多
提交训练任务,在所有节点上执行 train_multi_ds.sh
cd ~/LLaMA-Factory
srun -N2 "bash" "train_multi_ds.sh"训练完成之后将 lora adapter 文件上传到 S3 输出目录中,可参考代码库中的 deploy_on_SageMaker_endpoint_lmi_vllm.ipynb 部署到推理节点中。

代码库
扫码了解更多
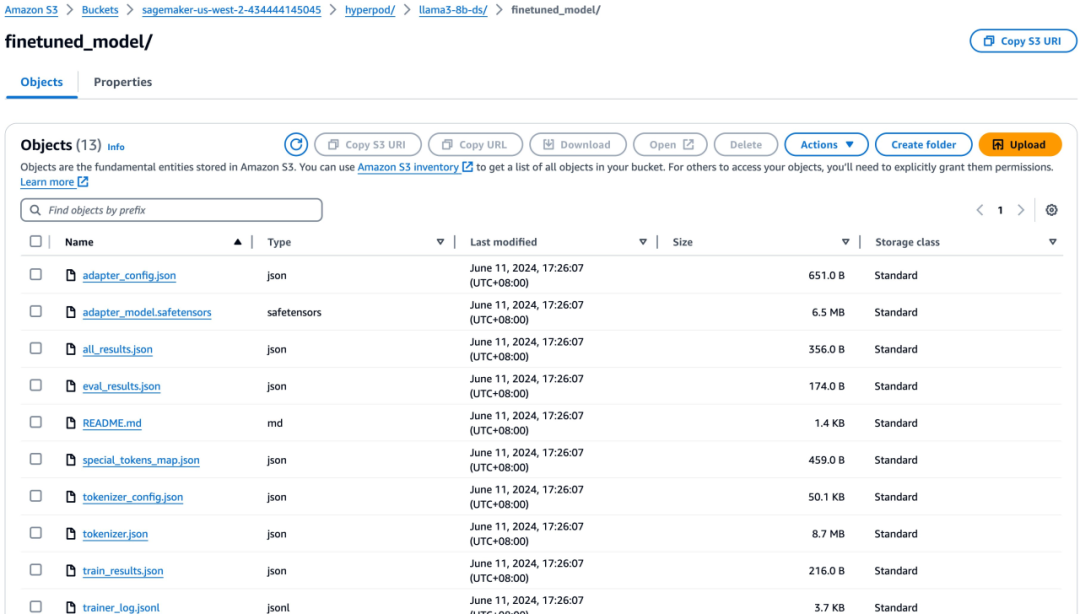
总结
Amazon SageMaker HyperPod 采用基于 Slurm 的 HPC 高性能弹性计算集群,能够实现跨机器跨 GPU 的大规模并行训练。本文介绍了:
HyperPod 集群的创建
SSH 远程访问集群设置
集群中部署 LLaMA-Factory
在集群中提交分布式训练任务
LLaMA-Factory 本身支持多种模型,集成多种训练方法,也可以应用于其他模型和其他的训练方法,因此,LLaMA-Factory 结合 Amazon SageMaker HyperPod,提供大规模可扩展的云上训练能力,实现轻松、便捷的大规模分布式训练。
附录

本篇代码库
扫码了解更多

Hyperpod 官方文档
扫码了解更多

Hyperpod 官方示例代码
扫码了解更多

Hyperpod CLI 命令
扫码了解更多

面向 GPU 服务器的 SageMaker 使用指南 (三) - Hyperpod 集群
扫码了解更多
左右滑动查看更多
本篇作者

谢川
亚马逊云科技生成式 AI 高级解决方案架构师,负责基于亚马逊云科技的生成式 AI 解决方案的设计、实施和优化。曾在通信、电商、互联网等行业有多年的产研经验,在数据科学、推荐系统、LLM RAG 等方面有丰富的实践经验,并且拥有多个人工智能相关产品技术发明专利。

郭韧
亚马逊云科技人工智能和机器学习方向解决方案架构师,负责基于亚马逊云科技的机器学习方案架构咨询和设计,致力于游戏、电商、互联网媒体等多个行业的机器学习方案实施和推广。在加入亚马逊云科技之前,从事数据智能化相关技术的开源及标准化工作,具有丰富的设计与实践经验。

唐清原
亚马逊云科技高级解决方案架构师,负责 Data Analytic & 人工智能与机器学习产品服务架构设计以及解决方案。十余个数据领域研发及架构设计经验。在大数据 BI、数据湖、推荐系统、MLOps 等平台项目有丰富实战经验。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容
















 9205
9205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









