







背景介绍
Apache Kafka 是一个分布式流处理平台,广泛应用于构建实时数据管道和流应用。它以其高吞吐量、低延迟和可扩展性而著称。Kafka 有着丰富的应用场景:
消息队列:作为高性能的消息中间件,用于解耦生产和消费速度不同的系统组件;
实时流处理:结合 Apache Flink、Spark Streaming 等工具,实现实时数据分析和处理;
数据集成:作为不同数据源和目标系统之间的桥梁,支持数据同步和 ETL(提取、转换、加载)过程;
Metrics 与监控:收集和处理应用程序或系统的性能指标和监控数据。
在云计算时代,软件定义了硬件,并提供了高可用、高可靠的服务级别协议保障。利用云服务构建 Kafka,无需自行实现复杂的分布式多副本复制协议,架构更简洁,成本更低。
AutoMQ Cloud 是 AutoMQ CO.,LTD 提供的新一代全托管 Kafka 云服务。在充分调研和深入的对亚马逊云科技的云上技术研究后, AutoMQ Cloud 深度融合了 Amazon EBS、Amazon S3 、Amazon EKS 帮助企业开发者在公有云环境中轻松构建、运行事件流处理应用程序,大幅降低了云上 Kafka 运维管理的成本。

AutoMQ Cloud
扫码了解更多

AutoMQ CO.,LTD
扫码了解更多
左右滑动查看更多
AutoMQ Cloud 100% 兼容开源 Apache Kafka,相比社区版在高可用容灾架构、弹性、可观测运维等企业级场景具做了大量的增强和完善。同时,AutoMQ Cloud 也提供了 RocketMQ 的商业支持版本,用户目前均可在亚马逊云科技的应用市场使用。本文将重点介绍 AutoMQ 在亚马逊云科技上架构的技术细节及核心优势。
AutoMQ Cloud
在亚马逊云科技平台上部署架构
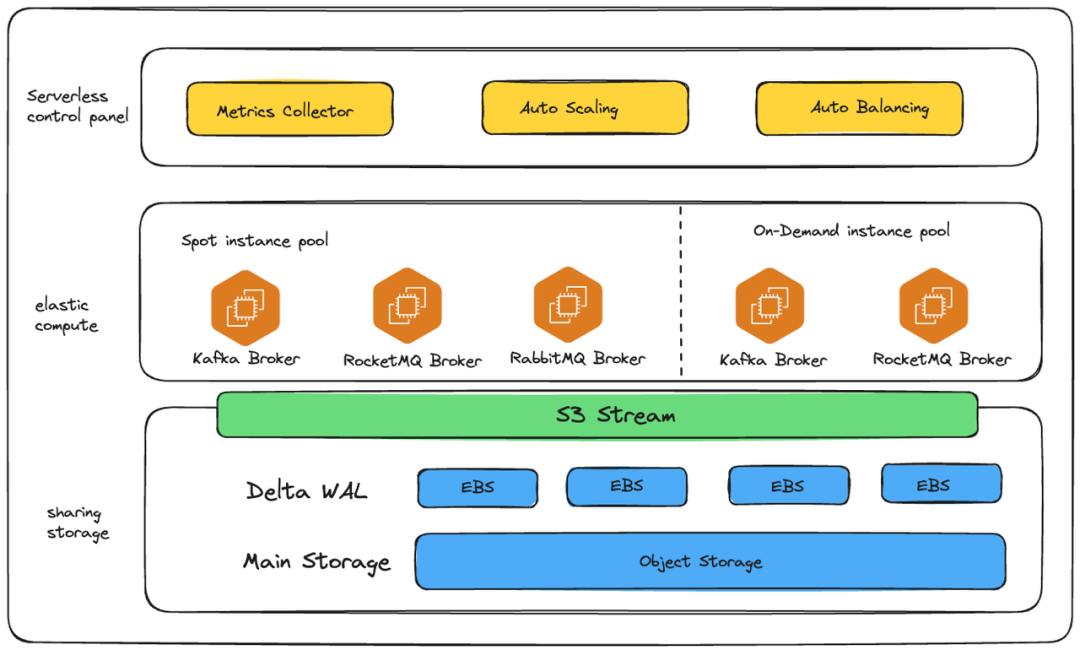
整体架构
AutoMQ 支持部署在 Amazon Elastic Kubernetes Service(Amazon EKS)上。
利用 Amazon EKS 将工作负载与亚马逊云科技联网和安全服务相集成。并且还与 Amazon Identity and Access Management(IAM)集成,为 Kubernetes 集群提供身份验证。包括对 Amazon S3、Amazon EBS 的资源管理。
Amazon S3 Stream 是 AutoMQ 中核心的流存储组件,秉承了 AutoMQ 存算分离的理念,将 Apache Kafka 原生的基于 ISR 复制的 Log 存储层卸载至云存储 Amazon EBS 和对象存储 Amazon S3。AutoMQ 创新性地在对象存储之上实现了一套核心的流存储 API,包括位点管理、Append、Fetch 和 Trim 数据等。
得益于 AutoMQ 无状态的计算层实现,使得其可以使用 Amazon EC2 Spot 实例配置托管节点组,以优化 Amazon EKS 集群中运行的计算节点的成本,相比 On-Demand 的按需实例,计算实例成本可以节约至多 90%。
支持 ARM 架构的 Amazon Graviton 处理器实例,为 AutoMQ 运行的云工作负载提供最佳性价比。

Kubernetes
扫码了解更多

亚马逊云科技联网
扫码了解更多

身份验证
扫码了解更多

Amazon EC2 Spot
扫码了解更多
功能及技术实现
充分发挥云弹性
Amazon EKS 支持 Karpenter 方式来快速扩容计算节点。Karpenter 是一个专为 Kubernetes 设计的开源自动扩缩容项目。它提高了 Kubernetes 应用程序的可用性,无需手动或过度配置计算资源。Karpenter 通过监控无法调度的 Pod 的聚合资源请求,智能决策启动或终止节点,从而在几秒钟内(而非几分钟)提供适当的计算资源,满足应用程序的实时需求,最大限度减少调度延迟。
在实际使用 Apache Kafka 的场景中,由于涉及到业务流量的迁移和分区数据的复制,Apache Kafka 集群往往无法直接应用弹性能力,而需要运维人员介入手动进行流量的腾挪,耗时通常在小时级别,这对于流量频繁变化的线上集群来说,几乎不可能做到按需扩缩容,为了保障集群的稳定性,运维人员只能选择提前按照最大容量部署,避免流量峰值来临时临时扩容不及时产生的风险,而这也导致了大量的资源浪费。
AutoMQ 可以实现秒级扩缩容,这个特性依赖一个原子能力,即秒级分区迁移。借助 HPA 和 Karpneter 可以快速完成 AutoMQ 的集群扩容和 Amazon EKS 集群节点扩容,集群扩容后,需要将集群中的部分分区批量地迁移至新节点,即可完成流量的重平衡,这往往能在十秒级完成。自动扩缩容为集群提供了更好的成本、稳定性、多租户的优势。

Karpenter
扫码了解更多

秒级分区迁移
扫码了解更多
左右滑动查看更多
HPA 示例:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: kafka-broker-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: automq-automq-enterprise-broker
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50左右滑动查看完整示意
使用 Node Group,预置两节点的 Broker 和 Controller 实例,使用 Karpenter 弹性进行 Spot 节点的扩展,配置示例:
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["arm64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["r6g.large", "r6g.xlarge", "r6g.2xlarge"]
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 720h # 30 * 24h = 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2 # Amazon Linux 2
role: "KarpenterNodeRole-eks"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "eks"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "eks"
amiSelectorTerms:
- id: "${ARM_AMI_ID}"
- id: "${AMD_AMI_ID}"
EOF左右滑动查看完整示意
在 Pod 需要新增节点时,查看 Karpenter 日志,快速响应拉起指定的 Graviton Spot 节点。
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller左右滑动查看完整示意

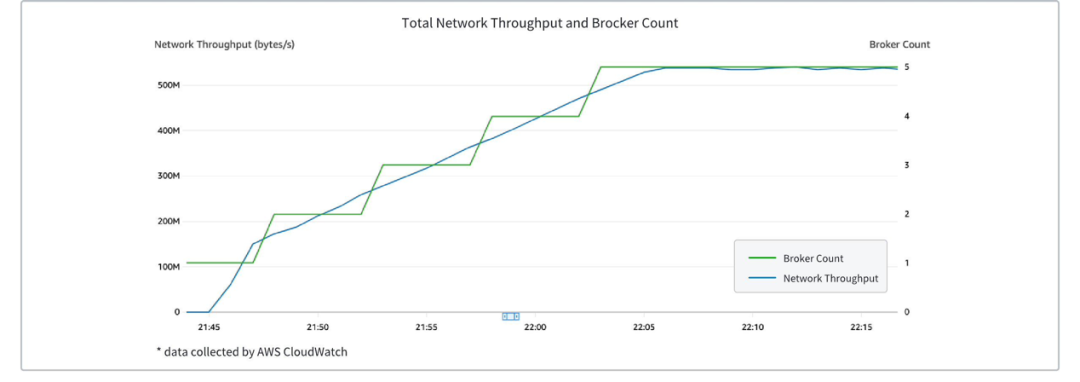
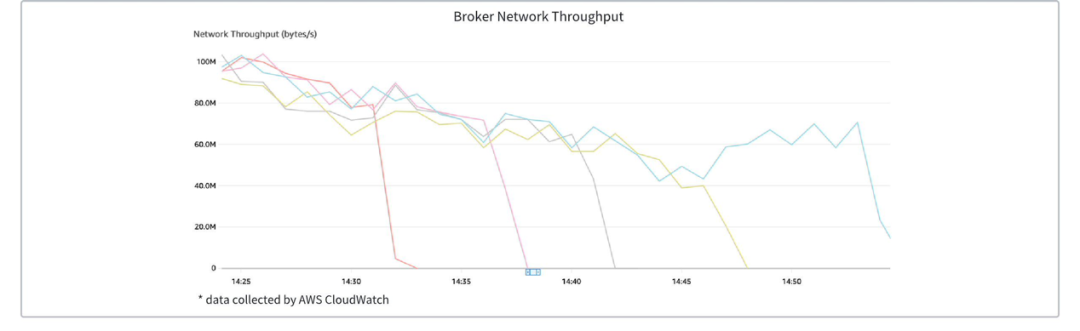
下图展示了 AutoMQ Kafka 集群的 Broker 数量随流量上涨发生的变化,可以看到随着流量的线性上升,Broker 被动态创建并加入集群平衡负载。
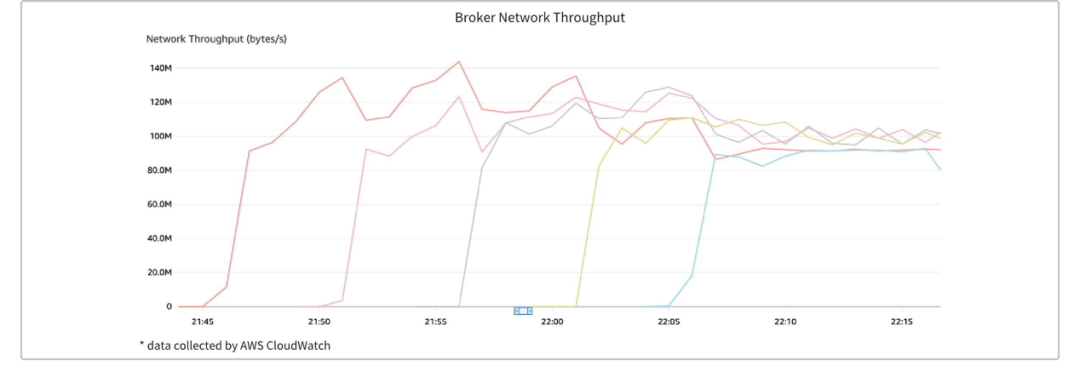
下图展示了流量上涨过程中,各 Broker 节点的流量变化,可以看到新创建的 Broker 均在十秒级完成了流量的重新负载。
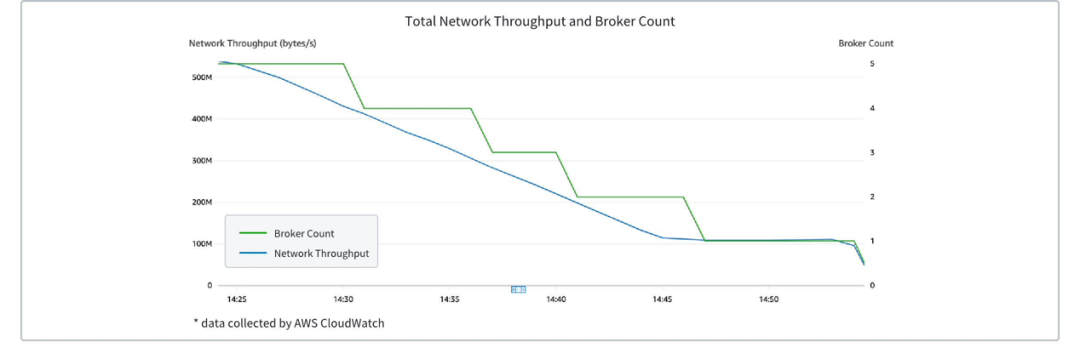
下图展示了一个 AutoMQ Kafka 集群的 Broker 数量随流量下降发生的变化,可以看到随着流量的线性下降,Broker 被动态下线节约资源。
下图展示了流量下降过程中,各 Broker 节点的流量变化,可以看到下线中的 Broker 的负载被转移到其余 Broker 上(每当 Broker 下线时,可观察到其余 Broker 流量有显著上升)。
利用云关键特性实现大幅成本优化
Apache Kafka 集群的成本主要包括计算和存储两部分。计算成本涵盖 Kafka Broker 运行所需的服务器 Amazon EC2;存储成本则涉及数据保存所需的存储设备 Amazon EBS。AutoMQ 全新的云原生架构针对计算和存储进行大幅优化,使集群总成本在相同流量下降低至原来的十分之一。
在存储方面,AutoMQ 充分使用亚马逊云科技的高可靠、低成本的云存储 Amazon S3 和 Amazon EBS gp3。在计算方面充分利用按量计费、任意扩缩的云计算,并且支持竞价实例,所有 Broker 都可以作为竞价实例,可以显著降低成本。
在亚马逊云科技宁夏区域 (cn-northwest-1) 运行上述负载 24 小时,获得以下结果。态扩缩容,通过 Amazon CloudWatch 可以获得在对应时间内,Broker 数量与集群总流量随时间的变化关系。如下图:
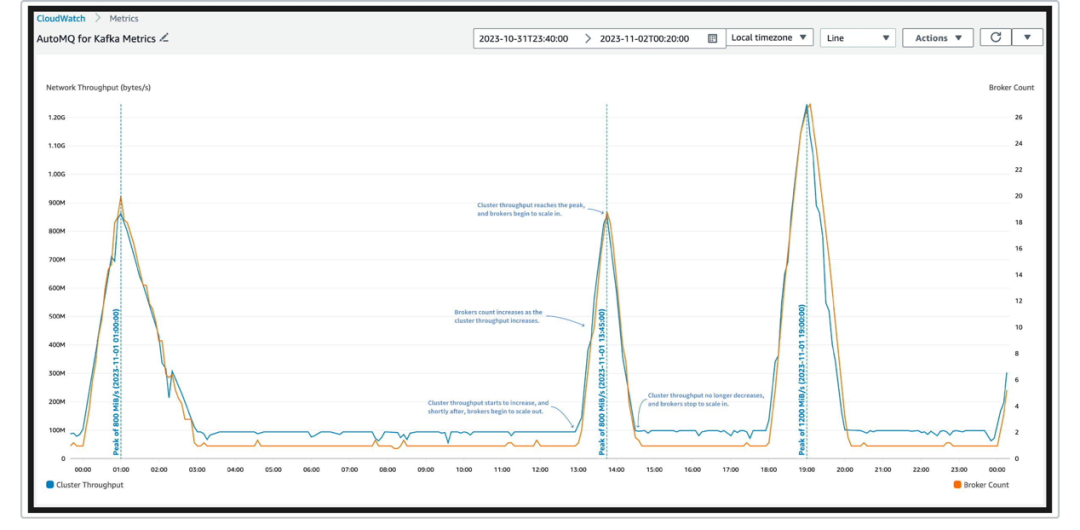
图中蓝色曲线为集群中生产消息的总流量(即每秒生产的消息总大小),由于生产消费比为 1:1, 这同时也是消费消息的总流量。其单位为 byte/s, 左 Y 轴中标识的单位是以 10 为底数的指数,例如,1M = 1,000,000, 1G = 1,000,000,000。
由于开启了 Amazon Auto Scaling group 的重平衡,以及竞价实例释放,在集群流量维持稳定时,依然可能发生短时间内 Broker 数量的增减。
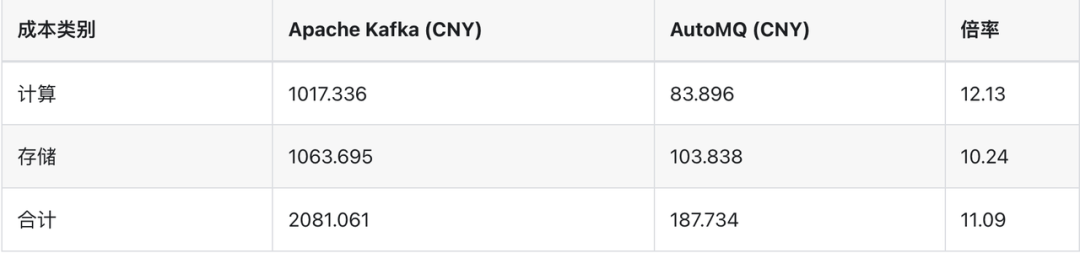
成本组成。
与 Apache Kafka 对比,估算了在同样场景下,Apache Kafka (低于 3.6.0 版本,无分层存储) 所需成本。
单 Broker 承载流量上限:100 MiB/s * 80% / (1 + 2) = 26.67 MiB/s
集群中 Broker 的数量:1200 MiB/s ÷ 26.67 MiB/s = 45
所需实例数量:45 + 3 = 48
每日计算成本:48 * 24 hour * 0.88313 CNY/hour = 1017.366 CNY
所需存储大小:16242 GiB * 3 / 80% = 60907.5 GiB
每日存储成本:60907.5 GiB * 0.5312 CNY/(GiB*month) / 730 hour/month * 24 hour = 1063.695 CNY
总成本:1017.366 CNY + 1063.695 CNY = 2081.061 CNY
云上可观测性增强
AutoMQ 使用 OpenTelemetry SDK 实现 Metrics 采集和导出,支持透出 Apache Kafka 业务指标和底层存储实现相关指标,这两类指标统一使用 OTLP 格式进行转换和透出。
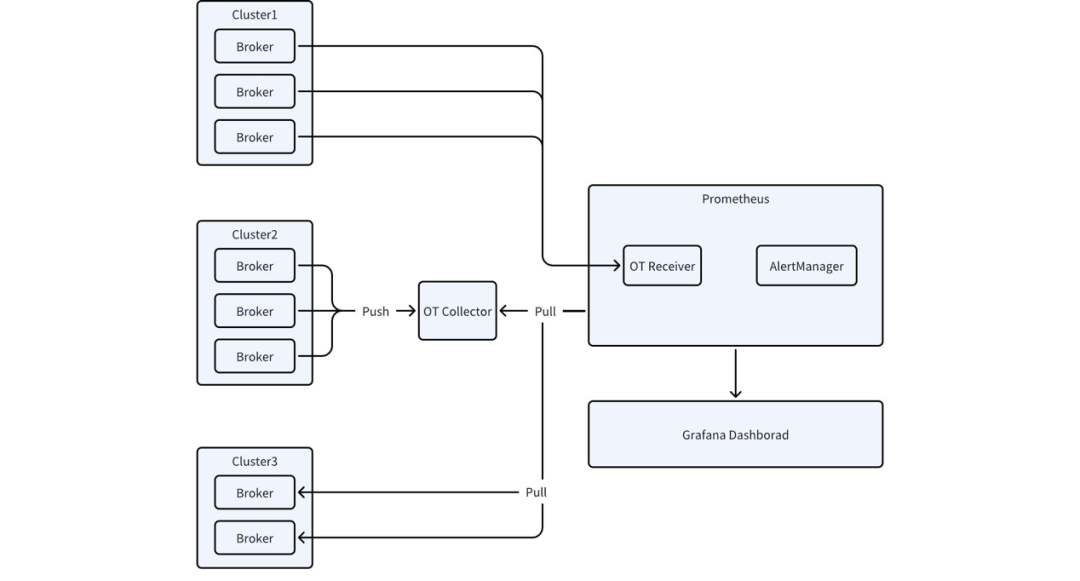
AutoMQ 提供了预设的 Grafana 大盘模板(链接)。将指标导出到 Amazon Managed Service for Prometheus 后,导入 Grafana 大盘模板,并将 Grafana 数据源配置为对应的 Prometheus,即可开始监测 AutoMQ。
预置的 Grafana 大盘模板提供了不同维度的指标监控,如Cluster Overview、Broker Metrics、Topic Metrics 等。其中,Cluster Overview 提供了集群级别的监控信息,包括节点数量、数据大小、集群流量等指标。此外,还提供了 Topic、Group、Broker 等维度的概览指标,并支持进一步查看详细监控信息的下钻功能,如下图所示:
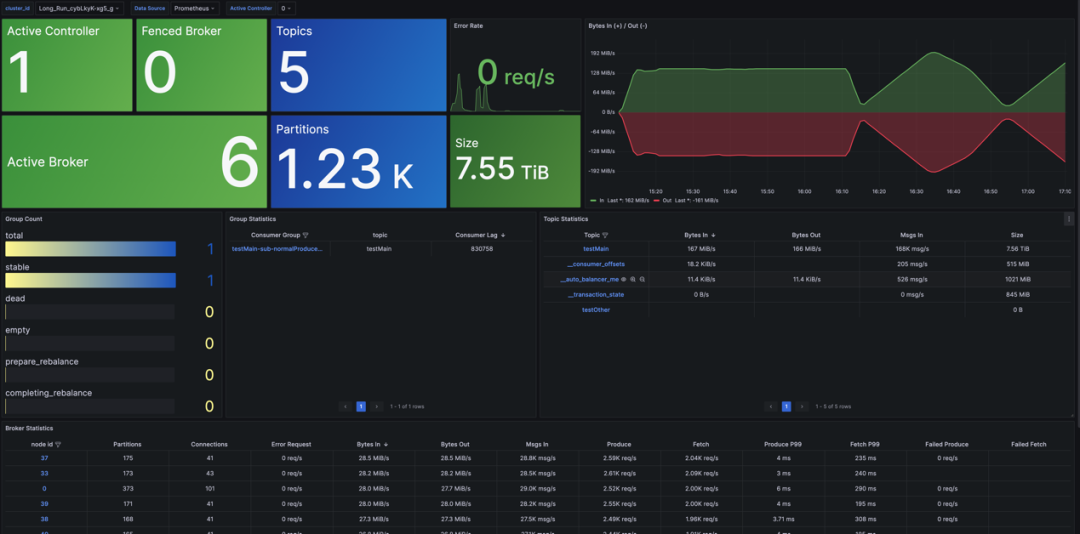
总结与展望
本文介绍了基于云原生理念重新设计的新一代 Apache Kafka 发行版 AutoMQ 的核心优势与在亚马逊云科技上的架构细节,并整理了 AutoMQ 兼容性、云上弹性、性能测试,总结出一定工作负载的成本优势,为用户在云上使用 Apache Kafka 提供了一个新的具有成本和弹性优势的解决方案。
与此同时,AutoMQ 也提供了 RockectMQ 的商业支持版本,并且均已上架亚马逊云科技应用市场。帮助用户更快实现业务价值。
未来,我们将继续研究,AutoMQ Kafka 结合亚马逊云科技云原生服务的数据集成解决方案,例如 Amazon Redshift 的流式摄入,以及 Kafka Connect 插件的实时数据同步、大规模消息队列成本优化等案例。

参考链接(见下方二维码):

AutoMQ 产品介绍
扫码了解更多

AutoMQ 如何实现自平衡
扫码了解更多

Amazon EKS 介绍
扫码了解更多

Karpenter
扫码了解更多
左右滑动查看更多


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9211
9211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









