







引言
在数据驱动的世界中,企业正在寻求可靠且高性能的解决方案来管理其不断增长的数据需求。本文从一个重视数据安全和合规性的 B2C 金融科技客户的角度来讨论云上云下混合部署的情况下如何利用亚马逊云科技云原生服务、开源社区产品以及第三方工具构建无服务器数据仓库的解耦方法。
Apache EMR(Elastic MapReduce)Serverless 是亚马逊云科技推出的一种全托管的无服务器大数据处理服务。它基于 Apache Spark 和 Apache Hive 计算引擎,提供计算和存储分离的架构,实现架构弹性的同时,增强了性能。
Apache DolphinScheduler 是一种与 Amazon EMR 集群解耦部署的多功能工作流调度程序,可确保高效可靠的数据编排和处理。此外,Amazon Athena 使客户能够使用标准 SQL 执行 Ad-hoc 查询并分析大量数据集,从而无需复杂的基础设施管理。
通过亚马逊云科技控制台实现的开放的集成测试,为这些组件的无缝集成和验证提供了可能,大大加快了工程师的工作效率。对于金融科技客户,Amazon EMR Serverless 可以提供业务线(LOB)级别的精细资源消费分析,从而实现精确监控和成本优化。这一功能在金融领域尤其有价值。因为在该领域,运营敏捷性和成本效益至关重要。
B2C 金融科技客户非常重视数据安全性和合规性。为了解决这些问题,本案客户采用了本地和云混合架构。敏感数据存储在本地。本篇文章讨论了实现本地系统和云环境之间数据无缝同步的具体解决方案。该解决方案使客户能够保持对敏感信息的严格控制,同时受益于云计算的可扩展性和灵活性。
本篇文章着重探讨云上云下数据同步方案的设计。
架构设计
金融科技客户非常关注数据安全和合规性。对于文章中讨论的具体案例,业务数据存储在本地 TiDB 上,而用户行为数据通过 Sensors Data 套件收集,存储在本地 HDFS 上。

Senors Data
(亚马逊云科技大中化区合作伙伴)
扫码了解更多

TiDB 产品服务信息
(亚马逊云科技全球合作伙伴)
扫码了解更多

Senors Data 产品服务信息
扫码了解更多
左右滑动查看更多
这些本地数据源通过 Amazon Direct Connect 连接到亚马逊云科技的 Region。在亚马逊云科技的环境中,数据流经 Interface Endpoint for S3、Amazon PrivateLink,最终访问 Amazon S3 存储桶(如下图所示,存储桶名为 ODS 示例)。接口终端节点由通过 Amazon Route53 托管的 DNS 解析器注册和管理。
然后,数据由 Amazon EMR Serverless Job(Hive 作业或 Spark 作业)处理,以实现数据仓库分层逻辑。不同的分层数据存储在单独的 Amazon S3 存储桶中或同一 Amazon S3 存储桶下的比不同的 Amazon S3 前缀中。这些数据的架构通过 Amazon Glue 数据目录进行管理,并且可以通过 Amazon Athena 控制台进行查询。
第三方 BI 工具通过 JDBC 与 Amazon Athena 进一步集成,实现数据可视化和生成数据报告,满足不同的业务需求,包括监管要求。
EMR Serveless Job 通过在 3 个 Amazon EC2 实例上以集群模式部署的 Apache DolphinScheduler 进行编排。DolphinScheduler 集群与其编排的 Amazon EMR 作业解耦部署,实现了整个系统的高可靠性:一个(Amazon EMR 作业或调度器)发生故障不会影响另一个(调度器或 Amazon EMR 作业)。
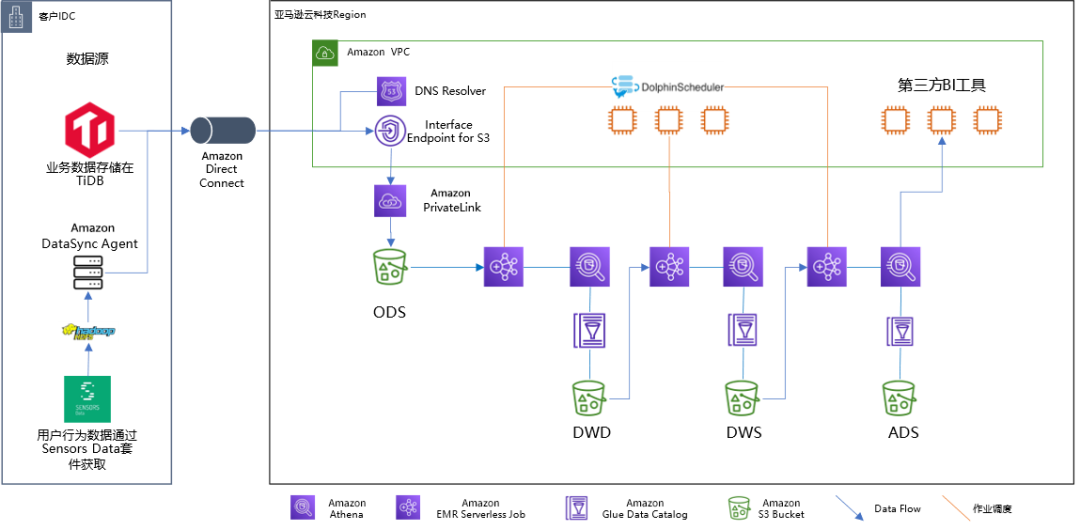
图 1:解决方案系统架构图
云上云下数据同步解决方案
从网络基础设施的角度来看,Amazon Direct Connect 被用来实现客户本地和亚马逊云科技区域之间的连接。在亚马逊云科技环境中,数据流经 Interface Endpoint for S3、Amazon PrivateLink,最终访问 Amazon S3 存储桶(如下图所示,存储桶名为 ODS(示例))。接口终端节点由通过 Amazon Route53 托管的 DNS 解析器注册和管理。
有关进一步的架构、工作机制说明以及部署指南,请参阅 privatelink-interface-endpoints 文档。

privatelink-interface-endpoints
文档
扫码了解更多
从数据传输的角度,设计了软件级双向数据同步解决方案。包括 3 个子场景:
存量数据从本地同步到亚马逊云科技 Region;
增量数据从本地同步到亚马逊云科技 Region;
将数据从亚马逊云科技 Region 反向同步到本地。
对于每个场景,都有特定的要求:
数据同步解决方案应该在源是 TiDB、HDFS,目标是 Amazon S3 的上下文中工作;
需要数据完整性检查机制,确保数据得到一致同步。
表 1 描述了满足每个子场景的特定要求的具体的解决方案。

表 1:云上云下数据同步解决方案设计
具体解决办法解释如下:
存量数据同步 – 利用 TiDB Dumpling 将数据从 TiDB 同步到 Amazon S3
如何实现本地 TiDB 数据同步到 Amazon S3 可以参考导出数据到 Amazon S3 云存储指导。通过执行以下命令,存储在 TiDB 中的数据可以转储为 .csv 文件并存储在 Amazon S3 存储桶中。
./dumpling -u root -P 4000 -h 127.0.0.1 -r 200000 -o "s3://${Bucket}/${Folder}" –filetype csv左右滑动查看完整示意

导出数据到 Amazon S3
扫码了解更多
存量数据同步 – 利用 Amazon DataSync 将数据从本地 HDFS 同步到 Amazon S3
Amazon DataSync 代理应安装在客户本地的服务器上。连接到 Hadoop 集群时,Amazon DataSync 代理充当 HDFS 客户端,与 Hadoop 集群中的主 NameNode 通信,然后从 DataNode 复制文件数据。
可以通过 Amazon DataSync获取该操作指南,将数据从 Hadoop HDFS 同步到 Amazon S3。

Amazon DataSync
扫码了解更多
增量数据同步 – 利用 TiDB Dumpling 和自管理的检查点
为了通过 TiDB Dumpling 工具实现增量数据同步,需要自行管理目标同步数据的检查点。一种推荐的方法是将最后摄取的记录的 ID 存储到特定介质(例如 ElastiCache for Redis、DynamoDB)中,以在执行触发 TiDB Dumpling 的 shell/python 作业时实现自我管理检查点。当然,实现该方案的前提是目标表有一个单调递增的 ID 字段作为主键。
对导出的数据进行过滤,可以获取具体的 TiDB Dumpling 命令。示例命令如下所示。

过滤导出数据
扫码了解更多
./dumpling -u root -P 4000 -h 127.0.0.1 -o /tmp/test --where "id < 100"左右滑动查看完整示意
增量数据同步 – 利用 TiDB CDC Connector 从 TiDB 到 Amazon S3
利用 TiDB CDC Connector 实现 TiDB 到 Amazon S3 的增量数据同步的好处是有原生的 CDC 机制,而且由于后端引擎是 Flink,所以性能很快。然而,这种方法有一个棘手的点或权衡点:需要创建相当多的 Flink 表来映射亚马逊云科技上的 ODS 表。
本 TiDB CDC Connector 操作指南可以通过 Tidb CDC 获取。

Tidb CDC
扫码了解更多
增量数据同步 – 利用 EMR Serverless Job 将数据从 Glue Catalog 表反向同步到 TiDB 表
大多数数据从客户的本地流向亚马逊云科技。但是,存在这样的场景:根据特定业务的需要,数据从亚马逊云科技反向流向客户本地。
数据着陆亚马逊云科技后,将通过使用特定表结构创建的 Amazon Athena 表通过 Glue 数据目录进行打包/管理。表 DDL 脚本如下所示:
CREATE EXTERNAL TABLE IF NOT EXISTS `table_name`(
`id` string,
……
`created_at` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
LOCATION 's3://bucket_name/prefix_name/';左右滑动查看完整示意
在这种情况下,Amazon EMR Serverless Spark Job 可以完成将数据从 Amazon Glue 表反向同步到客户本地表的工作。
如果 Spark 作业是用 Scala 编写的,示例代码如下:
package com.example
import org.apache.spark.sql.{DataFrame, SparkSession}
object Main {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("<app name>")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
spark.sql("use default")
var df=spark.sql("select * from <glue table name>")
df.write
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://tidbcloud_endpoint:4000/namespace")
.option("dbtable", "table_name")
.option("user", "use_name")
.option("password", "password_string")
.save()
spark.close()
}
}左右滑动查看完整示意
通过 SBT 将 Scala 代码打包为 .jar 文件后,可以通过以下 Amazon CLI 命令将作业提交到 Amazon EMR Serverless 引擎:
export applicationId=00fev6mdk***
export job_role_arn=arn:aws:iam::<aws account id>:role/emr-serverless-job-role
aws emr-serverless start-job-run \
--application-id $applicationId \
--execution-role-arn $job_role_arn \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-sql-test-nov23rd/scripts/dec13-1/scala-glue_2.13-1.0.1.jar",
"sparkSubmitParameters": "--conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.driver.cores=1 --conf spark.driver.memory=3g --conf spark.executor.cores=4 --conf spark.executor.memory=3g --jars s3://spark-sql-test-nov23rd/mysql-connector-j-8.2.0.jar"
}
}'左右滑动查看完整示意
如果 Spark 作业是用 Pyspark 编写的,示例代码如下:
代码类内容使用import os
import sys
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("app1")\
.enableHiveSupport()\
.getOrCreate()
df=spark.sql(f"select * from {str(sys.argv[1])}")
df.write.format("jdbc").options(
driver="com.mysql.cj.jdbc.Driver",
url="jdbc:mysql://tidbcloud_endpoint:4000/namespace ",
dbtable="table_name",
user="use_name",
password="password_string").save()
spark.stop()左右滑动查看完整示意
可以通过以下 Amazon CLI 命令将该作业提交到 EMR Serverless 引擎:
export applicationId=00fev6mdk***
export job_role_arn=arn:aws:iam::<aws account id>:role/emr-serverless-job-role
aws emr-serverless start-job-run \
--application-id $applicationId \
--execution-role-arn $job_role_arn \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-sql-test-nov23rd/scripts/dec13-1/testpython.py",
"entryPointArguments": ["testspark"],
"sparkSubmitParameters": "--conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.driver.cores=1 --conf spark.driver.memory=3g --conf spark.executor.cores=4 --conf spark.executor.memory=3g --jars s3://spark-sql-test-nov23rd/mysql-connector-j-8.2.0.jar"
}
}'左右滑动查看完整示意
上述 Pyspark 代码和 Amazon CLI 命令同时实现了外部传参:提交作业时将表名传输到 SQL 语句中。
自研的数据完整性检查
完备的数据完整性校验通过在源库上创建校验库,选择非空唯一字段计算校验值和行数,在目标库上使用与源库相同的字段计算校验值和行数,比较源库和目标库的校验值和行数实现。如果校验结果是不一致,那么需要手动对比和调整。这种校验方式的前提条件是源库和目标库都是关系型数据库。
本案中 TiDB 向 Amazon S3 的数据同步,目标端是对象存储而不并是数据库。因此,数据完整性的检验上会有些 trade-off。实战中,采用对比目标数据集的列总数和行总数,以及列名称的方式实现。
Amazon DataSync 数据完整性
Amazon DataSync 利用亚马逊云科技设计的与其连接的存储协议无关的传输协议,在数据移动时执行实时校验和验证。详细信息可以在 configure-data-verification-options 获取。除了实时校验和验证之外,Amazon DataSync 还支持增量传输、内联压缩。
Amazon DataSync 处理传输过程,因此用户无需编写和优化自己的复制脚本,也无需部署和微调商业数据传输工具。内置监控可确保移动文件和对象的数据完整性,并采用自动重试机制,以便到达目标文件存储的内容与原始文件匹配。
总结
金融科技客户非常注重数据安全和合规。为规避潜在的风险,本案例所涉及的客户的做法是将用户的出入金数据、用户的基础数据(统称为业务数据)放在 IDC,而用户的行为数据以及脱敏之后的业务数据放在亚马逊云科技平台中。从亚马逊云科技所服务的全球范围内的 FSI 行业客户看,越来越多的金融科技公司选择将业务数据也存放在亚马逊云科技平台上。
亚马逊云科技为客户提供的云平台及服务在安全和合规方面积累了非常丰富的认证,包括平台整体认证、适配所在国家或地区监管法规的认证、行业认证等等;同时亚马逊云科技也开发了非常丰富的产品服务帮助客户应对数据安全合规角度的各种需求。
参考资料:
https://awsmarketplace.amazonaws.cn/marketplace/pp/prodview-p6ywzvwiqj7lq?sr=0-2&ref_=beagle&applicationId=AWSMPContessa
https://aws.amazon.com/marketplace/pp/prodview-7xendfnh6ykg2?sr=0-1&ref_=beagle&applicationId=AWSMPContessa
https://docs.aws.amazon.com/AmazonS3/latest/userguide/privatelink-interface-endpoints.html
https://docs.pingcap.com/tidb/stable/dumpling-overview#export-data-to-amazon-s3-cloud-storage
https://aws.amazon.com/blogs/storage/using-aws-datasync-to-move-data-from-hadoop-to-amazon-s3
https://docs.pingcap.com/tidb/stable/dumpling-overview#filter-the-exported-data
https://nightlies.apache.org/flink/flink-cdc-docs-master/docs/connectors/cdc-connectors/tidb-cdc
https://docs.aws.amazon.com/datasync/latest/userguide/configure-data-verification-options.html
本篇作者

魏诗洋
亚马逊云科技资深解决方案架构师。专注金融行业云上系统架构及解决方案设计。关注大数据、机器学习在金融行业的应用,以及金融行业监管合规对云上系统架构设计的影响机制。10 年 + 数据领域研发及架构设计经验。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9232
9232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









