







SMT(表面贴装技术)是离散制造业中的一项关键技术,它通过自动化设备将电子元件直接贴装在印刷电路板(PCB)的表面。这种技术支持高密度的电子组件布局,显著提高了产品的可靠性和生产效率。
与传统的穿孔插装技术相比,SMT 实现了更小的组件尺寸和更短的信号传输路径,从而有效降低了制造成本并提升了产品性能。SMT 广泛应用于各类电子设备和产品中,如手机、计算机硬件、消费电子及汽车电子等,是当今电子制造行业的标准技术之一。
本篇文章参考了某全球知名制造企业在中国的灯塔工厂的真实业务场景,该工厂目前使用的 SMT 产线单条价值约 2,000 万人民币,每个贴片头每小时完成约 10 万次粘贴,一个贴片头成本大概在 30-50 万,维修成本昂贵。贴片机在正常情况下可以使用 10 年以上,按照 7*24*365 的不停机的设计,每年需要花费不菲的维修费用。
SiPlace 贴片机通过 PDI 接口每天会产生大量的操作和状态日志,每条产线有 3 台贴片机,3 台机器会分别产生 log 并保存为 .json 格式,每天每台机器 1-2GB 文件(约 1 万 – 2 万个文件)。业务侧希望将这些数据 ETL 后用于机器学习模型的训练,从而通过机器学习的方式做设备的预测性维护(例如贴片机上焊嘴的故障),提高设备的利用率。
整体架构
云边结合架构:边缘负责数据的采集以及预测模型的运行,云端负责数据的 ETL 以及预测模型的开发和训练。
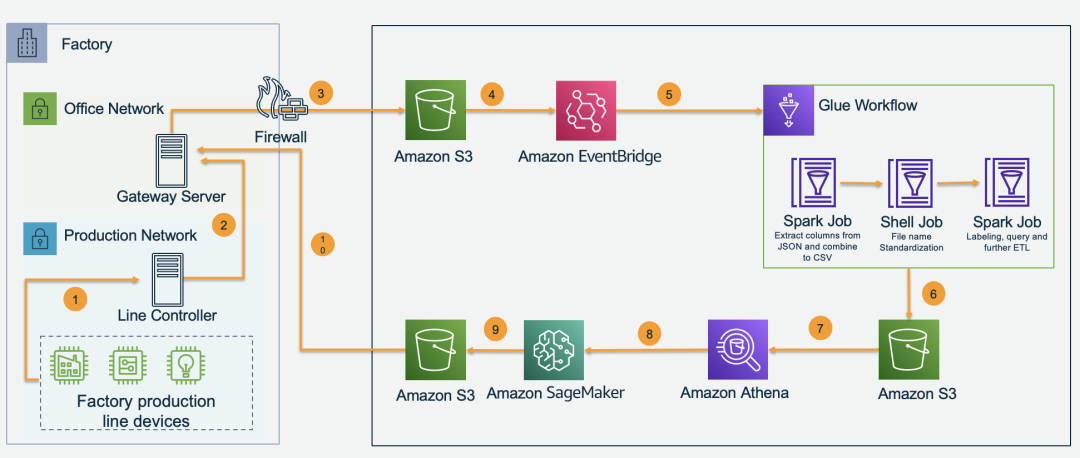
产品线中的贴片机每天都会生成大量的操作和状态记录,这些数据将由生产线控制器收集。
每条产品线的生产线控制器每 5 分钟将日志传输到出厂时的网关服务器(只有此服务器可以访问互联网)。
Gateway Server 每天收集所有日志文件,并使用亚马逊云科技 Python 开发工具包每 10 分钟将日志上传到 Amazon S3。
Amazon S3 中新上传的文件会触发 Amazon EventBridge 中的事件。
Amazon EventBridge 每天都会触发 Glue Workflow 对 ETL 日志(Glue 还将执行一次性任务以 ETL 所有历史数据)。
Glue Workflow 分几个步骤转换文件格式、清理数据、映射基准和其他 ETL 作业,并将最终结果保存到 Amazon S3。
使用 Amazon Athena 查询和检查清理后的数据,获取用于训练的数据。
Amazon SageMaker 使用这些数据训练机器学习模型以进行预测性维护。
模型工件将存储回 Amazon S3。
Gateway Server 下载用于边缘推理的模型工件。
部署配置过程
以下过程仅包含数据 ETL 部分,不包含机器学习模型的开发和训练。由于客户之前在本地主要使用 Python Shell 的方式做数据处理,在云端我们对比了 Shell 方式以及 PySpark 两种引擎。
使用 Python Shell 处理一天的日志数据:
您可以使用真实的产线数据,这里也为您提供了部分样例数据:

样例数据
扫码下载
创建测试用的 Amazon S3 桶,将数据以及在 Shell 脚本上传到对应的桶中,Shell 脚本主要实现从复杂多层嵌套的日志文件中提取出响应的字段,可以保留全部字段也可以进一步做字段的筛选,最终结果将保存为 .csv 的格式方便后续处理。

Shell 脚本
扫码查看
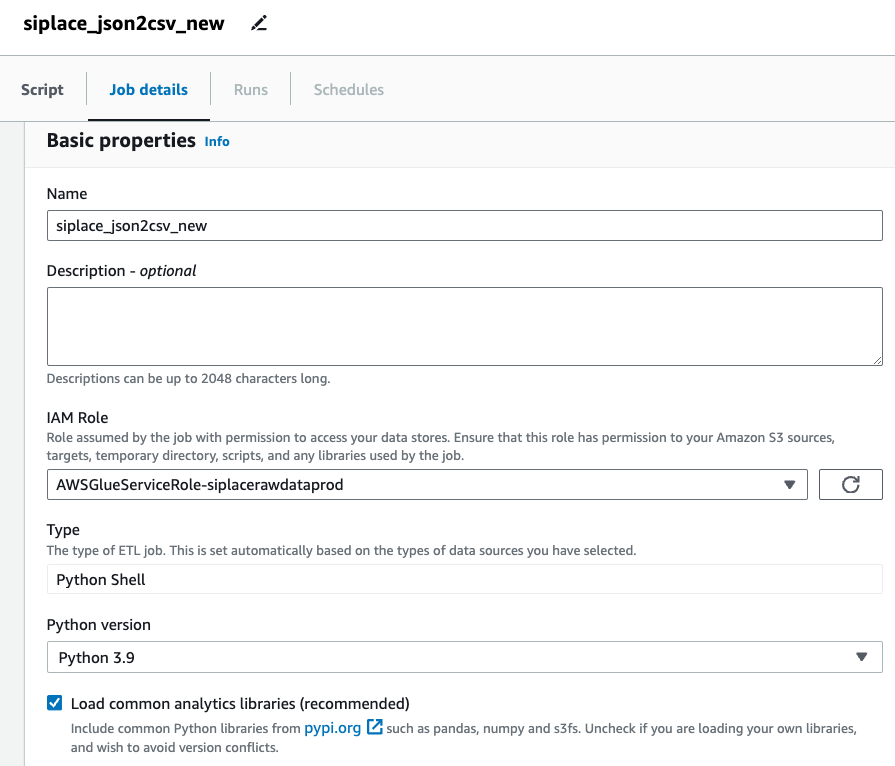
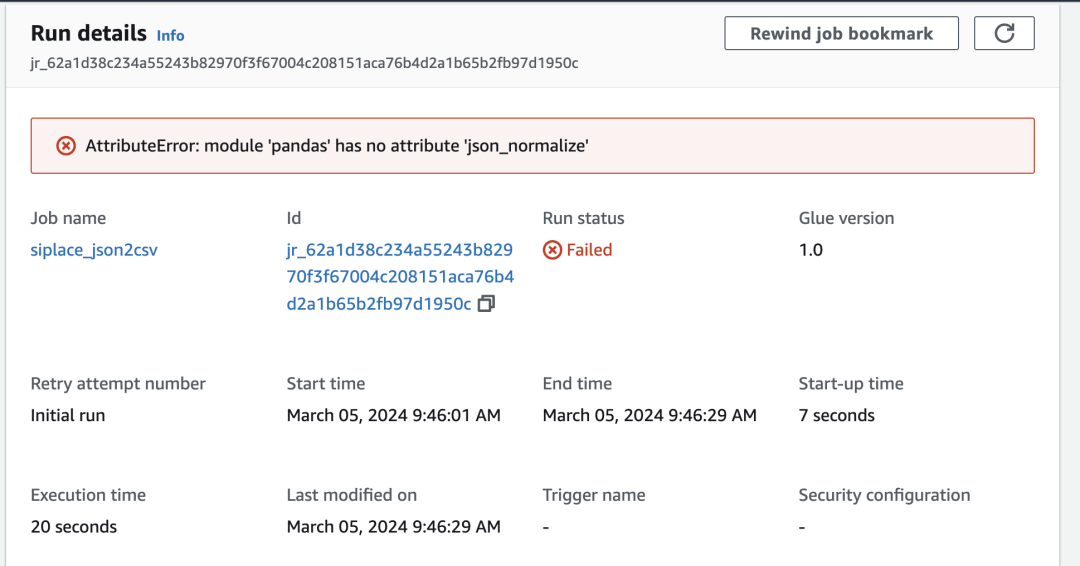
按照向导完成 Glue Job 的创建,类型使用 Python Shell,具体步骤参考下方二维码。由于代码中需要使用 Pandas 库的 json_normalize() 方法,此方法在 Shell 作业运行的环境中默认未提供,即使已经勾选如图 Load common analytics libraries 选项,Job 仍然会中途报错,错误内容为“AttributeError: module ‘pandas’ has no attribute ‘json_normalize’”。

具体步骤
扫码下载
报错类似如下截图:
此时需要通过手动上传 .whl 文件到 Amazon S3 并在 Job 中指定 Amazon S3 路径的方法,如下图所示加载自定义版本的 Pandas。您可以查看 Amazon Glue 提供的列表确认其它所需 library 是否在 Amazon Glue 默认提供的范围内。

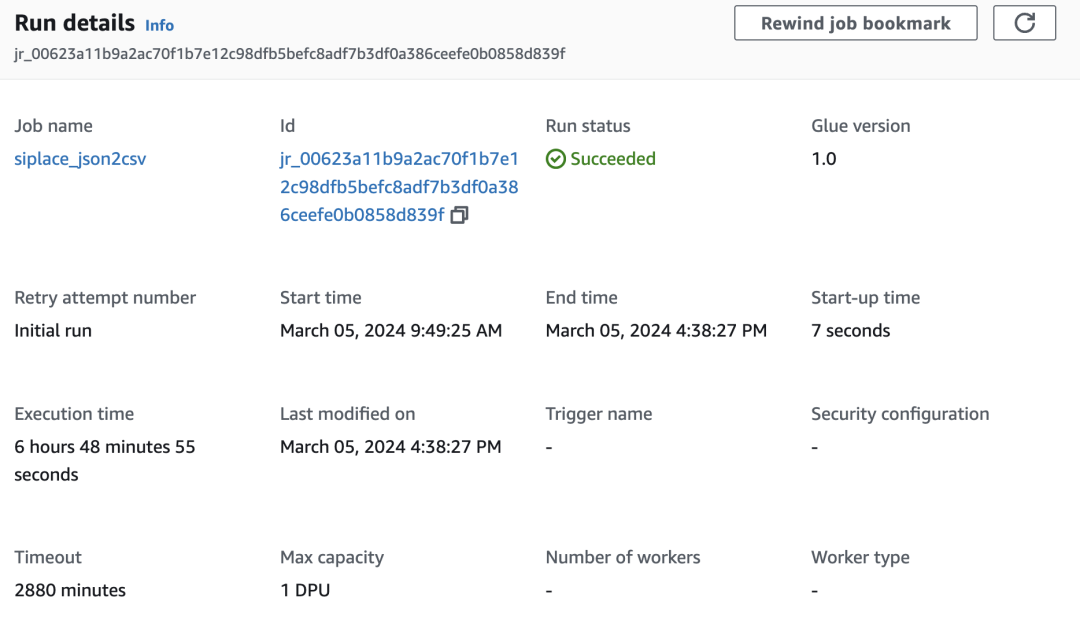
创建完成后即可运行 Amazon Glue 作业进行处理,可以看到一天的数据需要 6-7 个小时才可以完成。由于一般来说用于模型训练的数据至少需要 2-3 年的历史记录,如果继续使用 Shell 的方式的处理效率极低。
使用 PySpark 处理一天的日志数据:
将 PySpark 作业代码下载到您的 Amazon S3 桶中,请扫描下方二维码下载代码。
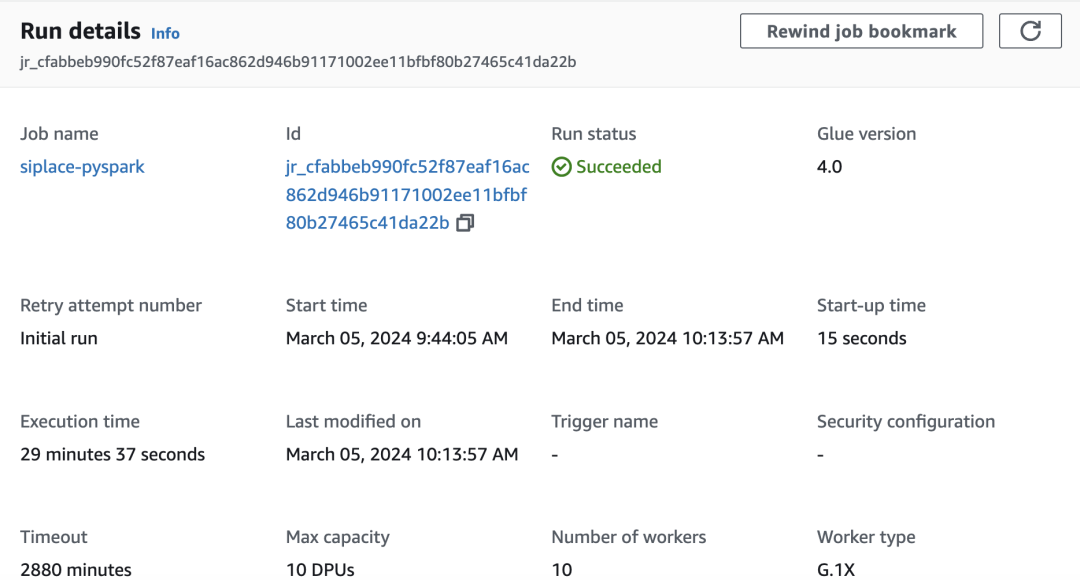
按照 Glue 的向导创建 PySpark 作业,引擎使用 Glue 4.0,Work Type 选择 1X,最大 worker 数量选择 10,具体步骤请参考下方二维码。

PySpark 作业代码
扫码下载

Glue 向导步骤
扫码查看
左右滑动查看更多
在最大 10 个工作节点的配置下,单日作业运行大概为 20-30 分钟。
建议将 .csv 格式的文件转换成 .parquet 格式,.parquet 是一种列式的存储格式,相比 .csv 可以大量提升查询的效率,这一步骤也可以合并到上一步骤中一起执行,代码请参考下文二维码。
笔者在一开始的测试过程中遇到了如下问题,在生成结果 .parquet 文件同时,Amazon S3 桶中还会生成一个 _$folder$ 的文件,这个文件会影响后续消费生成的结果数据。

参考代码
扫码查看

此问题是由于 Apache Hadoop 在运行 Spark 作业时默认会创建这个文件,可以通过增加如下代码解决,笔者已经将这部分代码合并到了 github 的代码中,直接使用即可:
hadoop_conf = sc._jsc.hadoopConfiguration()
hadoop_conf.set("fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
#此处还需要修改默认的fs.s3a.endpoint到对应Region的endpoint,否则会出现An error occurred while calling o66.parquet. doesBucketExist on siplacedemo的错误
hadoop_conf.set("fs.s3a.endpoint", "s3.cn-north-1.amazonaws.com.cn")左右滑动查看完整示意
处理之后的结果文件可以通过 Amazon Athena 查询,相关使用方式请参考下方二维码。笔者在测试过程中使用了 INSTR 方法,需要注意此方法在 Amazon Athena 中不支持,可以使用 STRPOS 方法替代。
原始 SQL 代码:
select substr(column_name, instr(column_name in '-')+ 1) as a,
substr(column_name, 1, instr(column_name in '-')- 1) as b from table_name;左右滑动查看完整示意

使用方式
扫码查看
替换后代码:
SELECT
substr(column_name, strpos(column_name, '-')) AS a,
substr(column_name, 1, strpos(column_name, '-') - 1) AS b
FROM table_name左右滑动查看完整示意
总结
本篇文章来源于某全球知名制造企业在中国的灯塔工厂的真实使用案例,在云端实现工厂内部使用的 SiPlace 贴片机的日志数据清洗,为设备预测性维护项目提供数据基础。Amazon Glue 作为亚马逊云科技上托管的数据 ETL 服务非常适合用于机器学习场景下模型训练数据的准备,包括特征工程部分。
相比传统的 Shell 作业,通过 Spark 可以实现每日数据 ETL 任务在 30 分钟内完成,满足客户的处理时间要求(不到 1 小时)。
对于 SMT 贴片机的日志处理场景,由于文件数量较多(1-2 万),Glue shell 作业需要 7 个小时才能完成,不是最好的选择。
通过使用多个 Glue 作业并行执行,可以在 2 天内处理一年的历史数据。
本篇作者

魏羽
亚马逊云科技高级解决方案架构师,在 IT 行业有从业超过 13 年的工作经验,其中超过 7 年作为公有云架构师角色帮助企业级客户完成业务上云的需求。当前在亚马逊云科技主要负责若干世界 500 强中的制造业和高科技行业客户的上云规划和支持,技术上致力于推广 IoT 和大数据分析相关技术在企业中的应用。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9218
9218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









