







1基本RDD
1.1 针对各个元素的转化操作
map()、filter()
两个最常用的转化操作是map()和filter()。转化操作map()接收一个函数,把这个函数用于RDD中的每个元素,每个元素经函数的返回结果作为新RDD中对应元素的值。而转化操作filter()则接收一个函数,并将RDD中满足该函数的元素放入新RDD中返回。
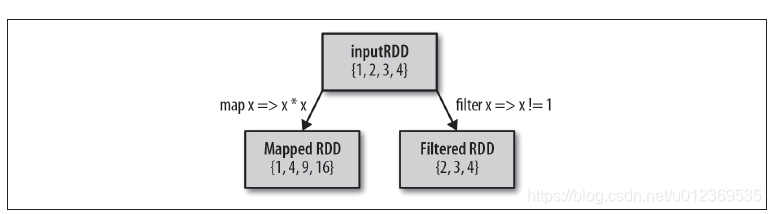
例如,用map()对RDD中的所有数求平方:
val input = sc.parallelize(List(1,2,3,4))
val result = input.map(x => x * x)
println(result.collect().mkString(","))
flatMap()
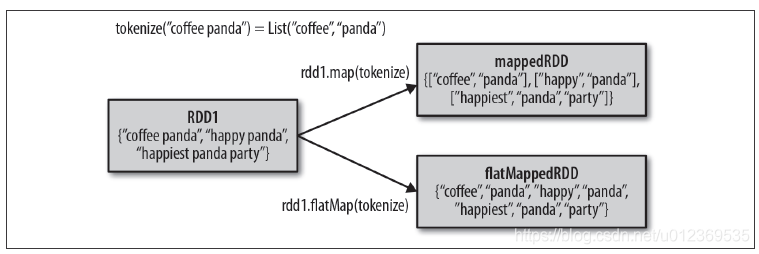
有时候,我们希望对每个输入元素生成多个输出元素。实现该功能的操作叫flatMap()。和map()类似,我们提供给flatMap()的函数被分别应用到了输入RDD的每个元素上。不过返回的不是一个元素,而是一个返回值序列的迭代器。输出的RDD倒不是由迭代器组成的。我们得到的是一个包含各个迭代器可访问的所有元素的RDD。flatMap()的一个简单用途是把输入的字符串切分为单词,如下例所示:
val lines = sc.parallelize(List("hello world", "hi spark"))
val words = lines.flatMap(line => line.split(" "))
words.first() //return "hello"
如下图所示,可以把flatMap()看作将返回的迭代器“拍扁”,这样就得到了一个由各列表中的元素组成的RDD,而不是一个由列表组成的RDD
1.2 伪集合操作
distinct()
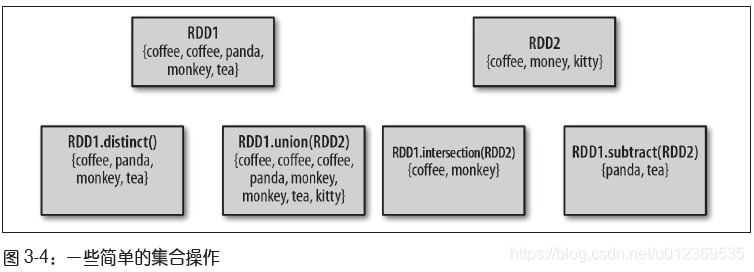
尽管RDD本身不是严格意义上的集合,但它也支持许多数学上的集合操作,比如合并和相交操作。RDD中常常有重复 的元素,如果只要唯一的元素,可以使用RDD.distinct()转化操作来生成一个只包含不同元素的新RDD。不过需要注意的是,distinct()操作的开销很大,因为它需要将所有数据通过网络进行混洗(shuffle),以确保每个元素都只有一份。
union()
最简单的集合操作是union(other),它会返回一个包含两个RDD中所有元素的RDD,并且如果输入的RDD中有重复数据,union()操作也会包含这些重复数据。
intersec()
Spark还提供了intersection(other)方法,只返回两个RDD中都有的元素,它会去掉所有重复的元素(单个RDD内的重复元素也会去重),intersection()也需要通过网络混洗数据来发现共有的元素。
subtract()
subtract(other)函数接收另一个RDD作为参数,返回一个由只存在于第一个RDD中而不存在于第二个RDD中的所有元素组成的RDD,它也需要数据混洗。
cartesian()
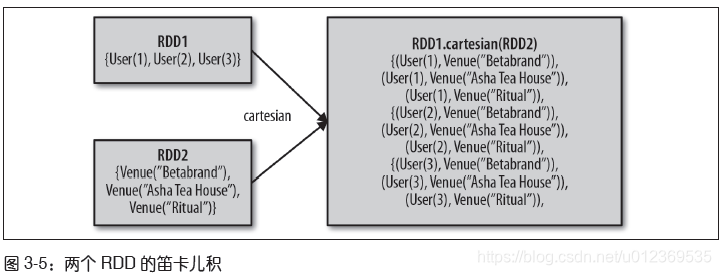
cartesian(other)计算两个RDD的笛卡尔积,会返回所有可能的(a, b)对,其中a是源RDD中的元素,而b则来自另一个RDD。不过要特别注意的是,求大规模RDD的笛卡尔积开销巨大。


1.3 行动操作
reduce()
基本RDD上最常见的行动操作是reduce()。它接收一个函数作为参数,这个函数要操作RDD中两个元素类型的数据并返回一个同样类型的新元素,这个返回的新元素和RDD中的下一个同类型的元素再经函数操作再返回一个新元素,以此迭代下去,如可利用它对RDD进行累加:
val l = sc.parallelize(List(1,2,3,4))
l.reduce((x, y) => x + y)
对于这个x,它代指的是返回值,而y是对RDD各元素的遍历。意思是对sum中的数据进行累加。
fold()
fold()和reduce()类似,接收一个与reduce()接收的函数签名相同的函数,并加了一个初始值参数来作为每个分区第一次调用时的结果。
val l = sc.parallelize(List(1,2,3,4))
l.fold(0)((x, y) => x + y)
这个计算其实 0 + 1 + 2 + 3 + 4,而reduce()的计算是:1 + 2 + 3 + 4,没有初始值,或者说RDD的第一个元素值是它的初始值。
fold()和reduce()都要求函数的返回值类型需要和我们所操作的RDD中的元素类型相同。但有时我们确实需要返回一个不同类型的值。例如,在计算平均值时,需要记录遍历过程中的计数以及元素的数量,这就需要我们返回一个二元组。可以先对数据使用map()操作,来把元素转为该元素和1的二元组,这样reduce()就可以以二元组的形式进行归约了。
aggregate()
aggregate()函数可以返回与RDD中元素类型不相同的结果。与fold()类似,使用aggregate()时,需要提供所期待返回的类型的初始值。然后通过一个函数把RDD中的元素合并起来放入累加器。考虑到每个节点是在本地进行累加的,最终,还需要提供第二个函数来将累加器两两合并。
比如刚才说到的计算平均值,最终我要返回一个二元组(Int,Int),这个二元组的第一个元素是RDD中各元素的累加和,第二个元素是RDD中的元素个数,因此我设置初始值为(0,0),接着我设置第一个函数为:
(x, y) => (x._1 + y, x._2 + 1)
x表示返回值,第一次调用即是初始值(0,0),y就是遍历RDD中的元素,x._1 + y就是RDD中的元素累加,x._2 + 1就是RDD中的元素个数,遍历完成后得到的就是RDD的元素之和及元素个数(累加器)。但是因为我们的计算是分布式计算,每个计算节点都会得到一个累加器,所以需要第二个函数将累加器两两合并
例如第一个节点遍历1和2, 返回的是(3, 2),第二个节点遍历3和4, 返回的是(7, 2),那么将它们合并的话就是3 + 7, 2 + 2,第二个函数为:
(x, y) => (x._1 + y._1, x._2 + y._2)
最终利用aggregate()函数求平均值是这样的:
val l = sc.parallelize(List(1,2,3,4))
val r = l.aggregate(0, 0)(
(x, y) => (x._1 + y, x._2 + 1),
(x, y) => (x._1 + y._1, x._2 + y._2))
val a = r._1 / r._2.toDouble
RDD的一些行动操作会以普通集合或者值的形式将RDD的部分或全部数据返回驱动器程序中。
collect()
把数据返回驱动器程序中最简单、最常见的操作是collect(),它会将整个RDD的内容返回。由于需要将数据复制到驱动器进程中,collect()要求所有数据都必须能一同放入单台机器的内存中。
take(n)
take(n)返回RDD中的n个元素,并且尝试只访问尽量少的分区,因此该操作会得到一个不均衡的集合。需要注意的是,这些操作返回元素的顺序与你预期的可能不一样。
top()
如果为数据定义了顺序,就可以使用top() 从RDD 中获取前几个元素。top() 会使用数据的默认顺序,但我们也可以提供自己的比较函数,来提取前几个元素。
takeSample(withReplacement, num,seed)
有时需要在驱动器程序中对我们的数据进行采样。takeSample(withReplacement, num,seed) 函数可以让我们从数据中获取一个采样,并指定是否替换。
有时我们会对RDD 中的所有元素应用一个行动操作,但是不把任何结果返回到驱动器程序中,这也是有用的。比如可以用JSON 格式把数据发送到一个网络服务器上,或者把数据存到数据库中。不论哪种情况,都可以使用foreach() 行动操作来对RDD 中的每个元素进行操作,而不需要把RDD 发回本地。

参考 《spark快速大数据分析》















 3059
3059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









