







Transformer 模型是深度学习中一种「基于注意力机制」的模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本生成和问答系统。
它由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出,突破了传统序列模型(如RNN和LSTM)的限制,特别是在长距离依赖问题上表现出色。它是 ChatGPT 和所有其他 LLM 的支柱。
https://arxiv.org/pdf/1706.03762
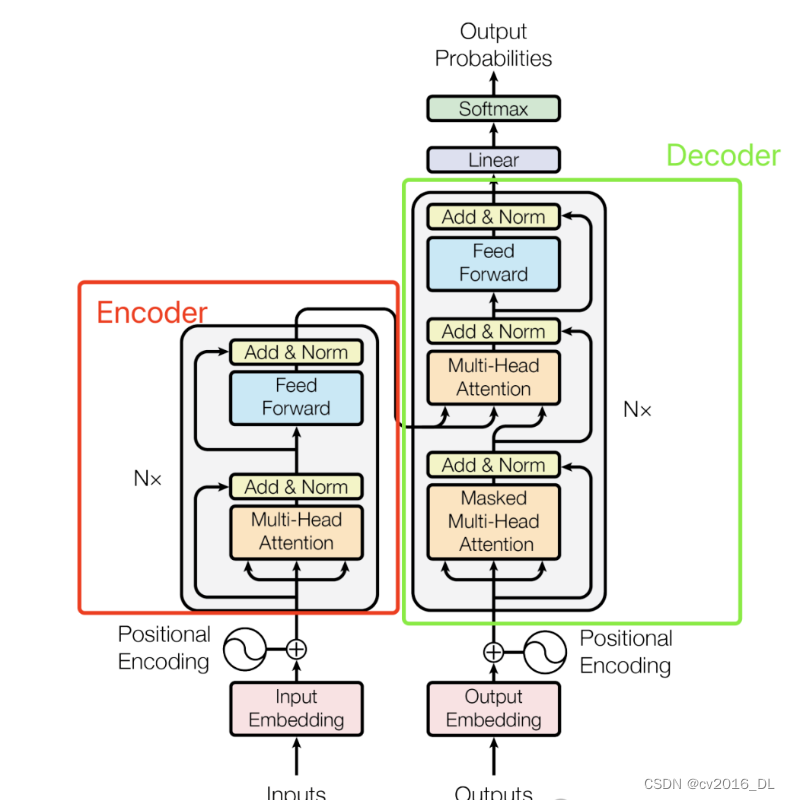
1.模型架构
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成。编码器和解码器各由 N 层相同的子层堆叠而成。
以下是编码器和解码器的详细结构。
1.1编码器(Encoder)
每层编码器包含两个子层:
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈神经网络(Feed-Forward Neural Network)
1.2解码器(Decoder)
每层解码器包含三个子层:
-
多头自注意力机制(Multi-Head Self-Attention)
-
编码器-解码器注意力机制(Encoder-Decoder Attention)
-
前馈神经网络(Feed-Forward Neural Network)
2.Transformer 核心组件
下面,让我们来看看 Transformer 如何将输入文本序列转换为向量表示,又如何逐层处理这些向量表示得到最终的输出。
2.1.输入编码
和常见的 NLP 任务一样,我们首先会使用词嵌入算法(word embedding),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。但为了简化起见,我们这里使用 4 维的词向量来进行讲解。
如下图所示,假设我们的输入文本是序列包含了 3 个词,那么每个词可以通过词嵌入算法得到一个 4 维向量,于是整个输入被转化成为一个向量序列。

2.2位置编码
由于 Transformer 模型依赖于自注意力机制,而自注意力机制本质上是无序的,即它不区分输入序列中各个词的位置顺序,因此需要显式地引入位置信息来帮助模型理解序列的顺序关系。
位置编码的具体实现方式有多种,Transformer 模型中采用了一种基于正弦和余弦函数的方式。
对于输入序列中的每个位置 pos 和每个维度 i,位置编码向量的计算公式如下。
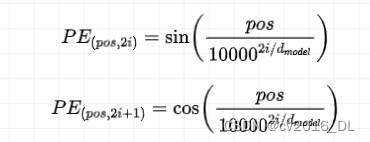
其中:
-
pos 表示序列中词语的位置。
-
i 表示位置编码向量的维度索引。
- <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









