







目的
对比Hive、集算器、Impala这三种大数据解决方案在分组汇总和关联计算时的性能差异。
硬件环境
PC数量:4
CPU:Intel Core i5 2500(4核)
RAM:16G
HDD:2T/7200rpm
Ethernet adapter:1000M
软件环境
操作系统:CentOS6.4
JDK:1.6
Hadoop/hdfs 2.2.0
测试对象
Hive 0.11.0
集算器 3.1
Impala 1.2.0
数据采样
1、每次测试前重启PC;
2、执行任务前在日志中打印开始时间;
3、执行任务后在日志中打印结束时间;
4、用结束时间减去开始时间作为参考结果。
1-4重复三次,取参考结果的平均值作为本次测试最终结果。
测试方案
Hive/Impala是类SQL语言,适合常规简单计算,算法过于复杂则难以实现;集算器是过程性语言,适合复杂的数据计算。因此,测试采用简单的分组汇总和关联计算,使两类语言都能实现。
本测试报告使用了CDH5.0beta里集成的hdfs和hive而不是单独发行的hadoop,这是由于Hadoop的安装部署比较复杂,测试环境总是出现故障,而CDH相对容易。
集算器既支持HDFS也支持本地硬盘,后者更快一些;而hive\Impala只支持HDFS。为了测试三种解决方案的极限性能,集算器使用本地硬盘测试,并事先将数据拆分为多个文件;而Hive\Impala则使用HDFS。
窄表的分组汇总测试
数据样本:
列数:11
行数:5亿行
文本状态下所占空间:120.6G。
数据结构:personid int,name string,sex int,cityid int,birthday int,degreeint,col1 string,col2 int,col3 int,col4 int,col5 string
测试案例:
1、1列分组1列汇总
Hive: select personid%10000, sum(col3) from p_narrow group by personid%10000
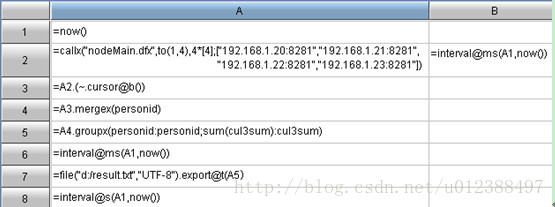
集算器:代码分为三部分,分别是:汇总机程序、节点机主程序、节点机子程序。
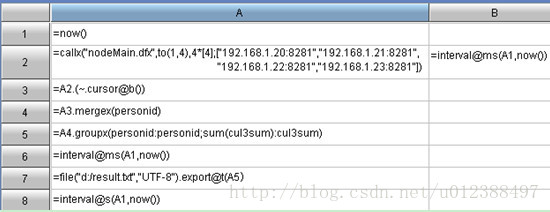

Impala: select personid%10000, sum(col3) from p_narrow group by personid%10000
2、1列分组4列汇总
Hive: select personid%10, count(col1), max(col2),sum(col3), count(col5) from p_narrow groupby personid%10
集算器:
将汇总机程序A5格改为:
=A4.groupx(personid:personid;count(cul1count):cul1count,max(cul2count):cul2count,sum(cul3sum):cul3sum,count(cul5):cul5count)
节点机主程序A5格改为:
=A4.groups@o(personid:personid;count(col1count):cu1count,max(col2count):cul2count,sum(col3sum):cul3sum,count(col5):cul5count)
节点机主程序A1格改为:
=cursor.groups(personid%10000:personid; count(col1count):co1count, max(col2count): col2count, sum(col3sum):col3sum,count(col5):col5count)
Impala:select personid%10, count(col1), max(col2),sum(col3), count(col5) from p_narrow group by personid%10
3、4列分组1列汇总
Hive: select personid%10, cityid%10, birthdayid%10,col4%10 from p_narrow group bypersonid%10,cityid%10,birthdayid%10,col4%10
集算器:
将汇总机程序A5格改为:
=A4.groupx(personid:personid,cityid:cityid, birthdayid:birthdayid, col4:col4; sum(cul3sum):cul3sum)
节点机主程序A5格改为:
=A4.groups@o(personid:personid, cityid:cityid,birthdayid:birthdayid, col4:col4; sum(col3sum):cul3sum)
节点机主程序A1格改为:
=cursor.groups(personid%10:personid, cityid%10:cityid,birthdayid%10:birthdayid, col4%10:col4; sum(col3sum):col3sum)
Impala: select personid%10, cityid%10,birthdayid%10, col4%10 from p_narrow group bypersonid%10,cityid%10,birthdayid%10,col4%10
4、4列分组,4列汇总
Hive: select personid%10, cityid%10,birthdayid%10, col4%10, count(col1), max(col2), sum(col3), count(col5) from p_narrow group bypersonid%10,cityid%10,birthdayid%10,col4%10
集算器:
将汇总机程序A5格改为:
=A4.groupx(personid:personid,cityid:cityid, birthdayid:birthdayid, col4:col4;count(cul1count):cul1count,max(cul2count):cul2count,sum(cul3sum):cul3sum,count(cul5):cul5count)
节点机主程序A5格改为:
=A4.groups@o(personid:personid, cityid:cityid, birthdayid:birthdayid, col4:col4; count(col1count):cu1count,max(col2count):cul2count,sum(col3sum):cul3sum,count(col5):cul5count)
节点机主程序A1格改为:
=cursor.groups(personid%10:personid, cityid%10:cityid, birthdayid%10:birthdayid,col4%10:col4; count(col1count):co1count, max(col2count):col2count, sum(col3sum):col3sum, count(col5):col5count)
Impala: select personid%10, cityid%10, birthdayid%10,col4%10, count(col1), max(col2), sum(col3), count(col5) from p_narrow group bypersonid%10,cityid%10,birthdayid%10,col4%10
测试结果:
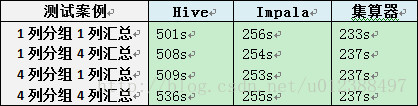
宽表的分组汇总测试
数据样本:
表名:p
列数:106
行数:6千万
文本状态下所占空间:127.9G。
数据结构:personid int,name string,sex int,cityid int,birthday int,degree int,col1int,col2 int,col3 int,col4 int,col5 int,col6 int,col7 int,col8 int,col9 int,col10int,col11 int,col12 int,col13 int,col14 int,col15 int,col16 int,col17 int,col18int,col19 int,col20 int,col21 int,col22 int,col23 int,col24 int,col25 int,col26int,col27 int,col28 int,col29 int,col30 int,col31 int,col32 int,col33 int,col34int,col35 int,col36 int,col37 int,col38 int,col39 int,col40 int,col41 int,col42int,col43 int,col44 int,col45 int,col46 int,col47 int,col48 int,col49 int,col50int,col51 int,col52 int,col53 int,col54 int,col55 int,col56 int,col57 int,col58int,col59 int,col60 int,col61 int,col62 int,col63 int,col64 int,col65 int,col66int,col67 int,col68 int,col69 int,col70 int,col71 int,col72 int,col73 int,col74int,col75 int,col76 int,col77 int,col78 int,col79 int,col80 int,col81 int,col82int,col83 int,col84 string,col85 string,col86 string,col87 string,col88 string,col89string,col90 string,col91 string,col92 string,col93 string,col94 string,col95 string,col96string,col97 string,col98 string,col99 string,col100 string
测试案例:
1、1列分组1列汇总
Hive: select personid%10000, sum(col3) from p group by personid%10000
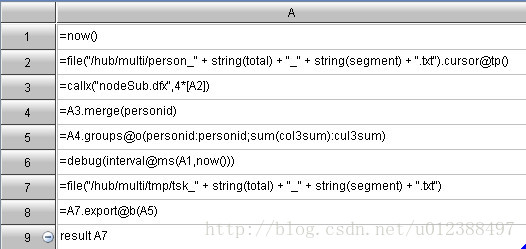
集算器:代码分为三部分,分别是:汇总机程序、节点机主程序、节点机子程序。
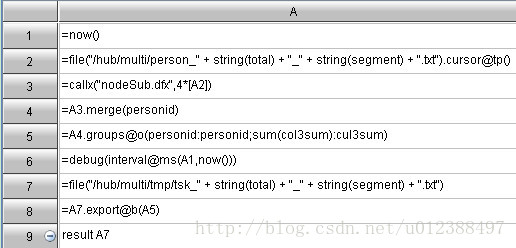

Impala: select personid%10000, sum(col3) from p group by personid%10000
2、1列分组4列汇总
Hive: select personid%10, count(col1), max(col2), sum(col3), count(col5)from p group by personid%10
集算器:
将汇总机程序A5格改为:
=A4.groupx(personid:personid;count(cul1count):cul1count,max(cul2count):cul2count,sum(cul3sum):cul3sum,count(cul5):cul5count)
节点机主程序A5格改为:
=A4.groups@o(personid:personid;count(col1count):cu1count,max(col2count):cul2count,sum(col3sum):cul3sum,count(col5):cul5count)
节点机主程序A1格改为:
=cursor.groups(personid%10000:personid; count(col1count):co1count, max(col2count): col2count, sum(col3sum):col3sum,count(col5):col5count)
Impala:select personid%10, count(col1), max(col2),sum(col3), count(col5) from p group by personid%10
3、4列分组1列汇总
Hive: select personid%10, cityid%10, birthdayid%10, col4%10 from p group bypersonid%10,cityid%10,birthdayid%10,col4%10
集算器:
将汇总机程序A5格改为:
=A4.groupx(personid:personid,cityid:cityid, birthdayid:birthdayid, col4:col4; sum(cul3sum):cul3sum)
节点机主程序A5格改为:
=A4.groups@o(personid:personid, cityid:cityid,birthdayid:birthdayid, col4:col4; sum(col3sum):cul3sum)
节点机主程序A1格改为:
=cursor.groups(personid%10:personid, cityid%10:cityid,birthdayid%10:birthdayid, col4%10:col4; sum(col3sum):col3sum)
Impala: select personid%10, cityid%10,birthdayid%10, col4%10 from p group bypersonid%10,cityid%10,birthdayid%10,col4%10
4、4列分组,4列汇总
Hive: select personid%10, cityid%10, birthdayid%10, col4%10,count(col1), max(col2), sum(col3), count(col5) from p group by personid%10,cityid%10,birthdayid%10,col4%10
集算器:
将汇总机程序A5格改为:
=A4.groupx(personid:personid,cityid:cityid, birthdayid:birthdayid, col4:col4;count(cul1count):cul1count,max(cul2count):cul2count,sum(cul3sum):cul3sum,count(cul5):cul5count)
节点机主程序A5格改为:
=A4.groups@o(personid:personid, cityid:cityid,birthdayid:birthdayid, col4:col4; count(col1count):cu1count,max(col2count):cul2count,sum(col3sum):cul3sum,count(col5):cul5count)
节点机主程序A1格改为:
=cursor.groups(personid%10:personid, cityid%10:cityid,birthdayid%10:birthdayid, col4%10:col4; count(col1count):co1count,max(col2count): col2count, sum(col3sum):col3sum, count(col5):col5count)
Impala: select personid%10, cityid%10, birthdayid%10, col4%10,count(col1), max(col2), sum(col3), count(col5) from p group by personid%10,cityid%10,birthdayid%10,col4%10
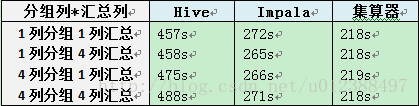
测试结果:
http://hi.baidu.com/datanalysis/item/3e30faef530f8028595dd874















 1825
1825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









