







文章目录
- Hive数据分析实验报告
- 实验要求
- IP地址规划表
- 实验步骤
- 1 数据集预处理
- 2 数据集上传HDFS
- 3 从HDFS中导出数据集至HIVE数据库
- 4 Hive操作
- (1)查看user_log表数据结构
- (2)查看user_log表简单数据结构
- (3)查看日志前10个交易日志的**商品品牌**
- (4)查询前20个交易日志中购买商品时的**时间**和**商品的种类**
- (5)用聚合函数count()计算出表内有多少条行数据
- (6)在函数内部加上distinct,查出**user_id不重复**的数据有多少条
- (7)排除顾客刷单(查询**不重复的数据**)
- (8)查询双11当天有多少人**购买**了商品
- (9)品牌2661,当天**购买**此品牌商品的数量
- (10)查询多少用户当天**点击**了2661品牌的该店
- (11)查询双十一当天男女**购买**商品比例
- (12)查询某一天在该网站**购买**商品超过5次的用户id
- (13)创建姓名缩写表,其中字段大于4条,并使查询插入,最后显示姓名缩写表格数据
Hive数据分析实验报告
实验要求
1 完成本地数据user_log文件上传至HDFS中
2 完成HDFS文件上传至Hive中
用户行为日志user_log.csv,日志中的字段定义如下:
- user_id | 买家id
- item_id | 商品id
- cat_id | 商品类别id
- merchant_id | 卖家id
- brand_id | 品牌id
- month | 交易时间:月
- day | 交易事件:日
- action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- province| 收货地址省份
3 Hive操作
(1)查看user_log表数据结构
(2)查看user_log表简单数据结构
(3)查看日志前10个交易日志的商品品牌
(4)查询前20个交易日志中购买商品时的时间和商品的种类
(5)用聚合函数count()计算出表内有多少条行数据
(6)在函数内部加上distinct,查出user_id不重复的数据有多少条
(7)排除顾客刷单(查询不重复的数据)
(8)查询双11当天有多少人购买了商品
(9)品牌2661,当天购买此品牌商品的数量
(10)查询多少用户当天点击了2661品牌的该店
(11)查询双十一当天男女购买商品比例
(12)查询某一天在该网站购买商品超过5次的用户id
(13)创建姓名缩写表 其中字段大于4条,并使查询插入,最后显示姓名缩写表格数据
IP地址规划表
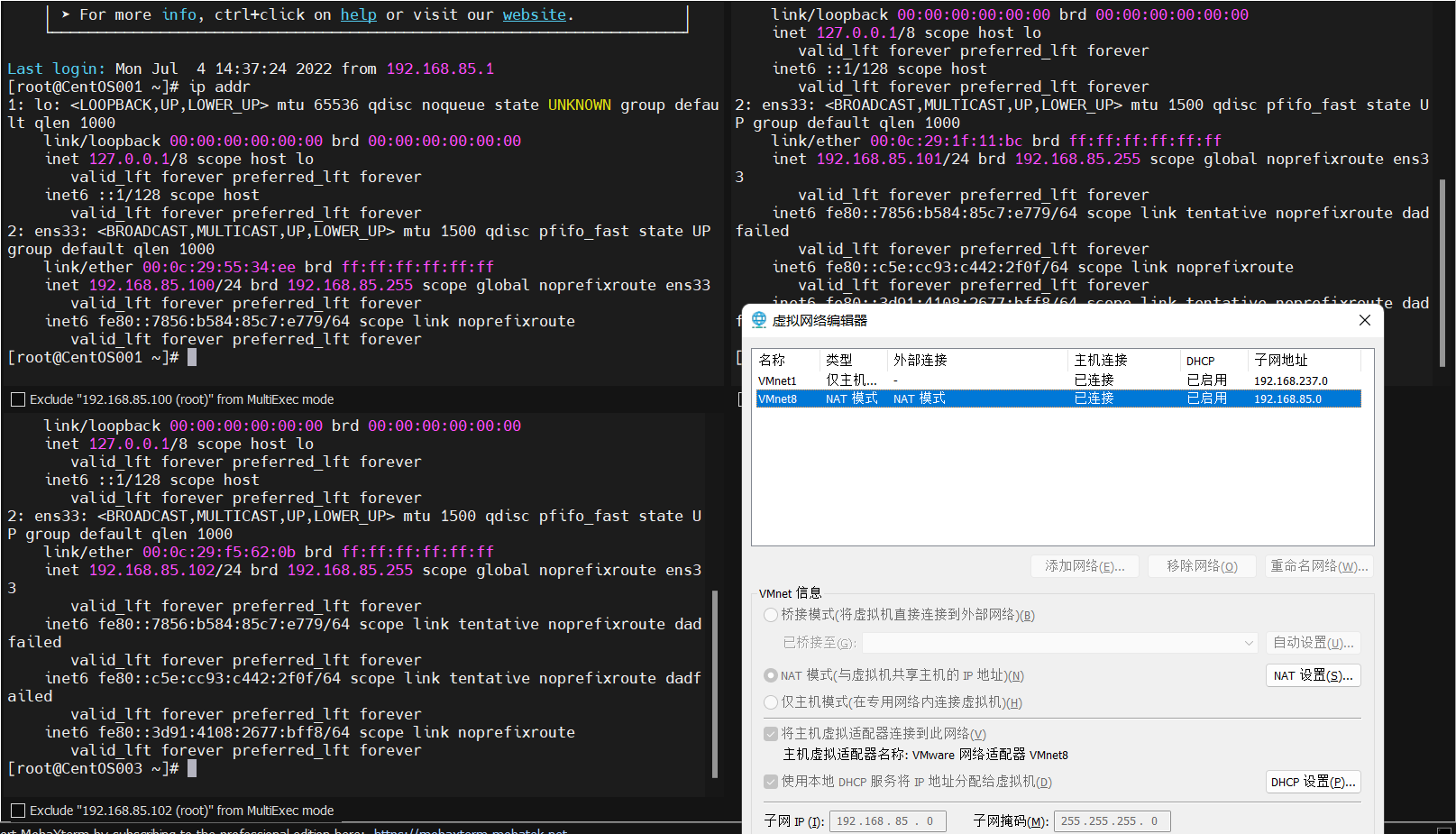
实验步骤
1 数据集预处理
- 安装unzip
yum install unzip
- 创建数据存放文件夹
mkdir /usr/local/dbtaobao/dataset
- 解压数据集zip包
cp -r /mnt/hgfs/data_format.zip /usr/local/dbtaobao/dataset/
cd /usr/local/dbtaobao/dataset/
unzip data_format.zip
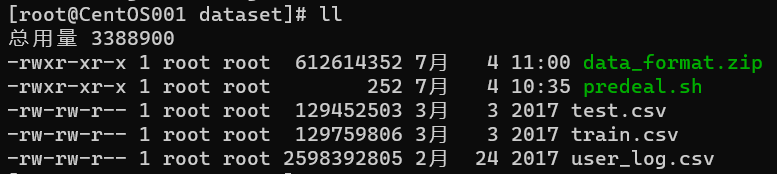
- 查看user_log.csv前5行数据
head -5 user_log.csv

- 删除第一行
sed -i '1d' user_log.csv
-
提取10000条user_log中日期为11月11日的数据,并存放于small_user_log中
-
- 创建脚本predeal.sh
infile=$1
outfile=$2
awk -F "," 'BEGIN{
id=0;
}
{
if($6=11 && $7=11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11","$12
if(id==10000){
exit
}
}
}' $infile > $outfile
-
- 为predeal.h提权
chmod +x ./predeal.sh
-
- 运行脚本predeal.sh,查看输出
./predeal ./user_log.csv ./small_user_log.csv

2 数据集上传HDFS
- 在hdfs中创建存放user_log的文件夹
start-all.sh
hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
- 向hdfs推送small_user_log.csv
hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log

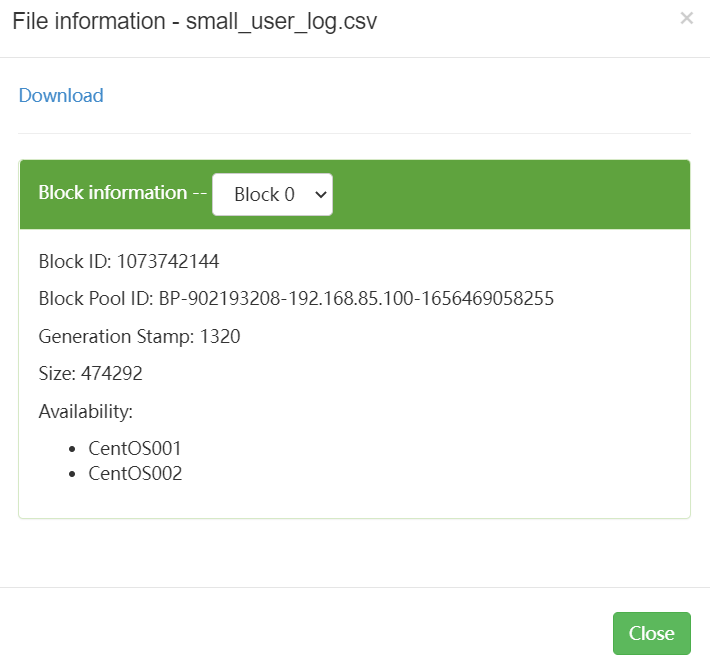
- 查看上传成功的数据文件前10行
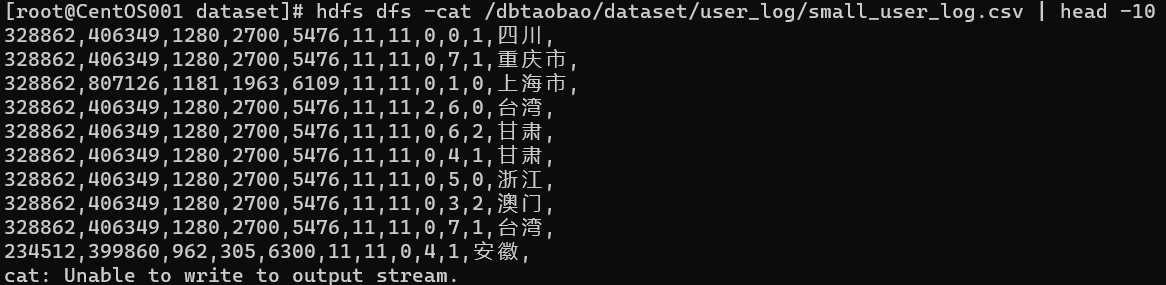
hdfs dfs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10
3 从HDFS中导出数据集至HIVE数据库
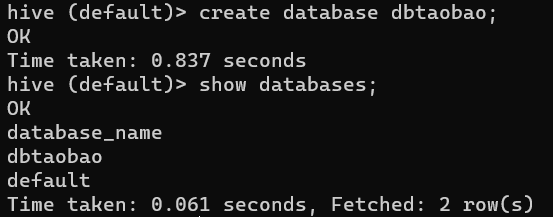
- 创建HIVE数据库dbtaobao
create database dbtaobao;
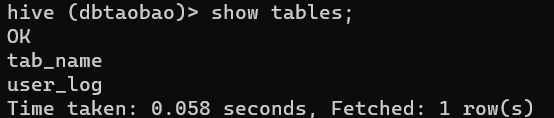
- 创建user_log表
create external table dbtaobao.user_log(user_id int,item_id int,cat_id int,merchant_id int,brand_id int,month string,day string,action int,age_range int,gender int,province string) comment 'Welcome to Alex dblab, now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile location '/dbtaobao/dataset/user_log';
- 查看表user_log前十行数据
use dbtaobao;
select * from user_log limit 10;

4 Hive操作
(1)查看user_log表数据结构
show create table user_log;
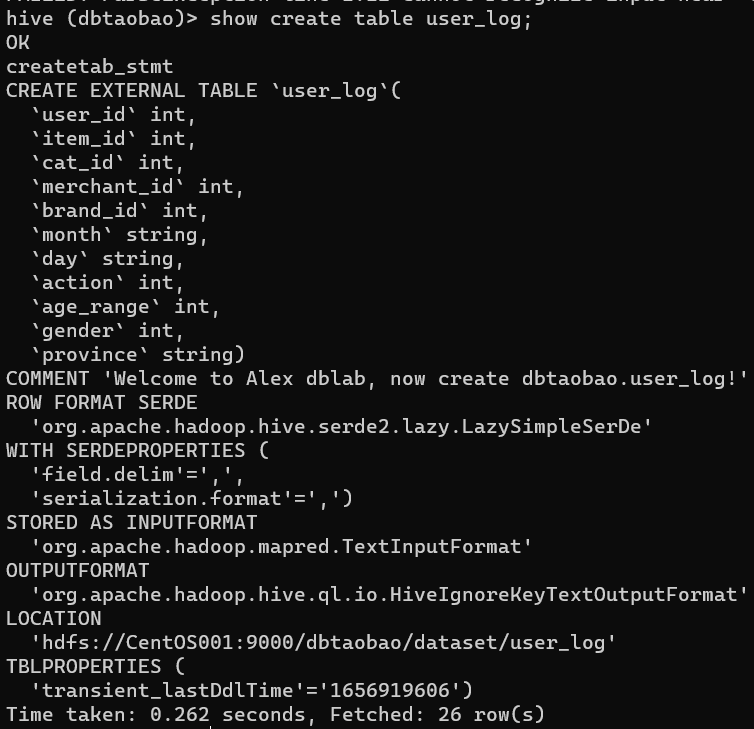
(2)查看user_log表简单数据结构
desc user_log;
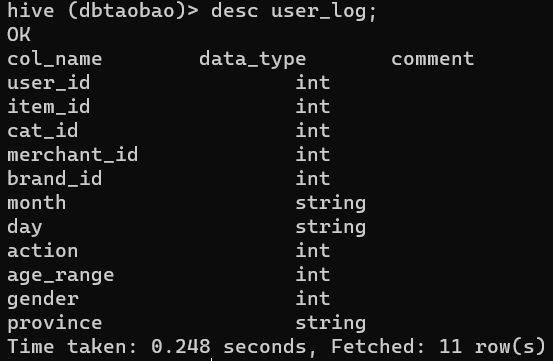
(3)查看日志前10个交易日志的商品品牌
select brand_id from user_log limit 10;
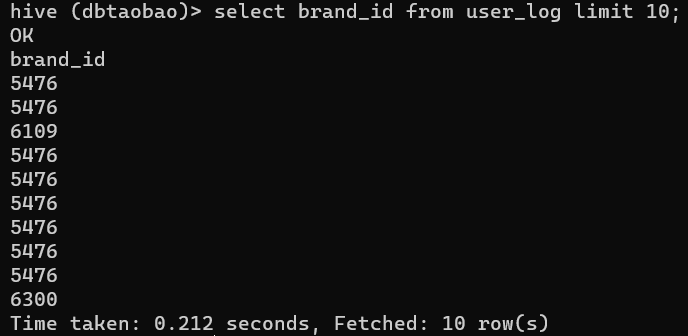
(4)查询前20个交易日志中购买商品时的时间和商品的种类
select month,day,brand_id from user_log limit 20;
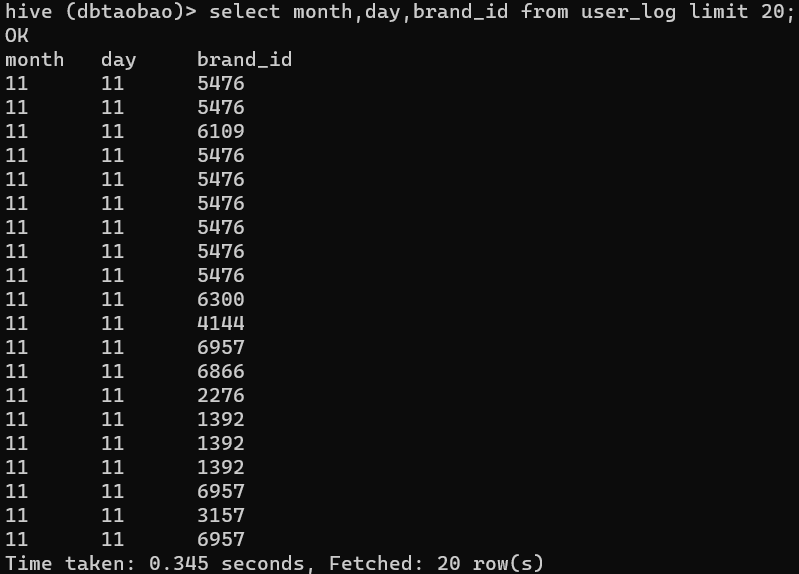
(5)用聚合函数count()计算出表内有多少条行数据
select count(*) from user_log;
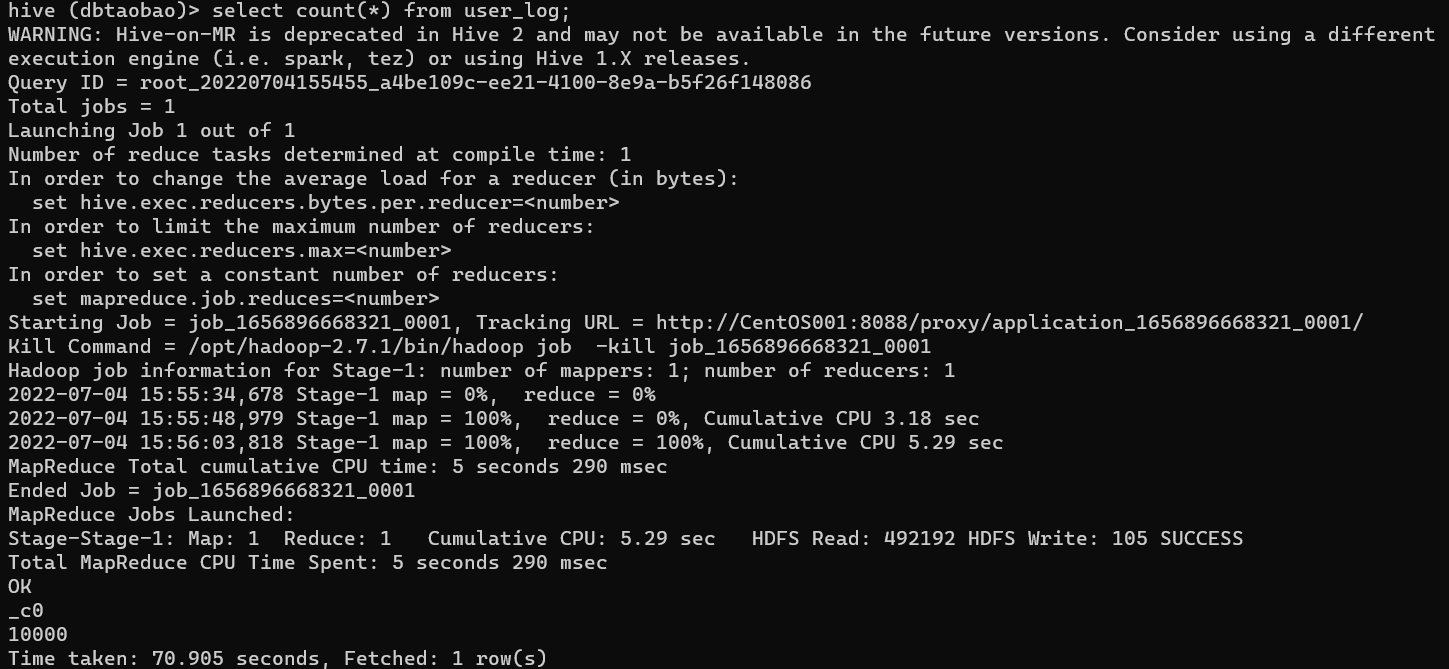
Result : 10000
(6)在函数内部加上distinct,查出user_id不重复的数据有多少条
select count(distinct user_id) from user_log;

Result : 358
(7)排除顾客刷单(查询不重复的数据)
select count(distinct user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province) from user_log;
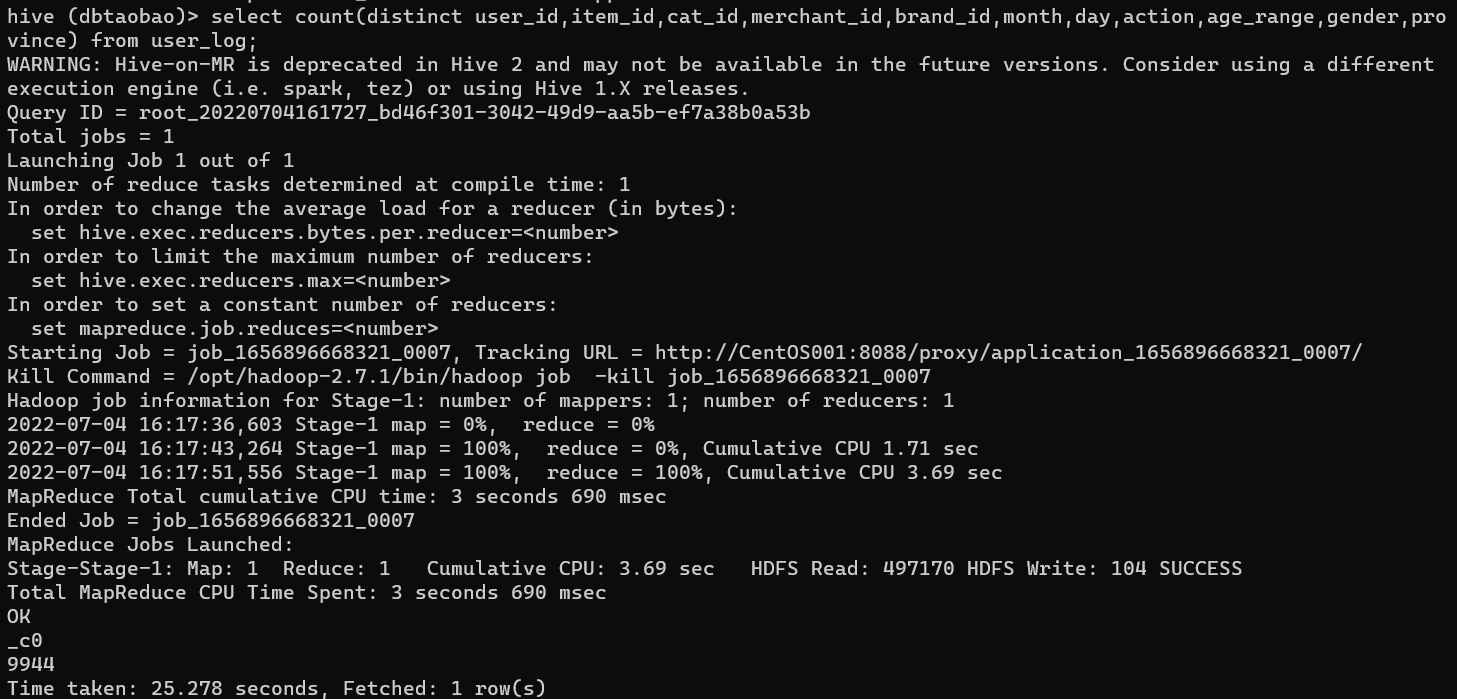
Result : 9944
(8)查询双11当天有多少人购买了商品
select count(distinct user_id) from user_log where action='2';
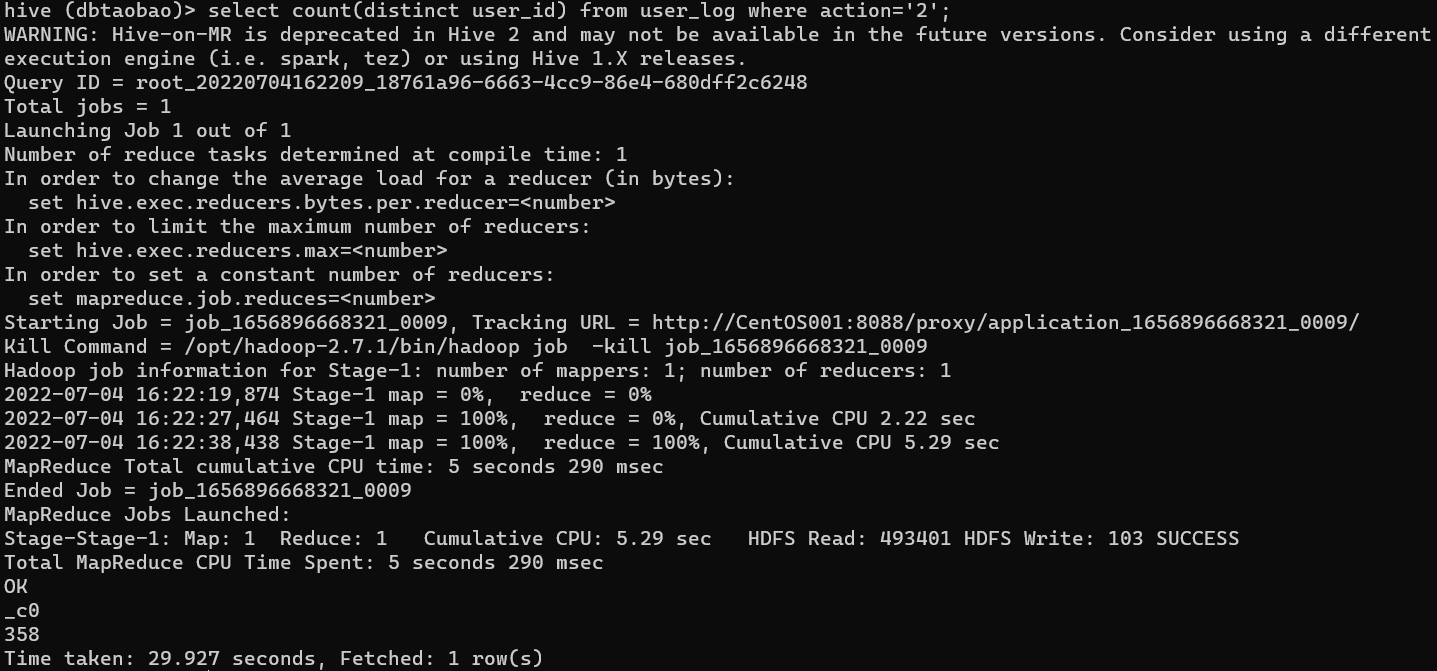
Result : 358
(9)品牌2661,当天购买此品牌商品的数量
select count(*) from user_log where brand_id='2661' and action='2';

Result : 3
(10)查询多少用户当天点击了2661品牌的该店
select count(distinct user_id) from user_log where brand_id='2661' and action='0';
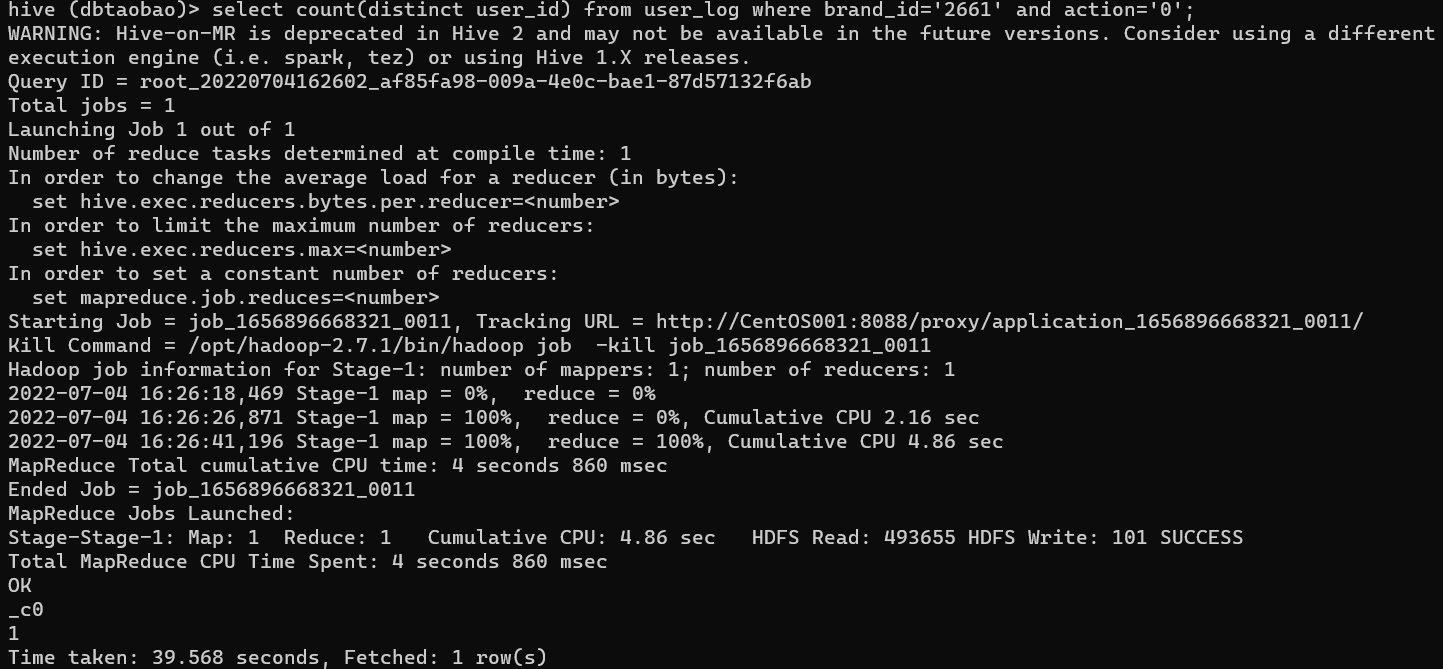
Result : 1
(11)查询双十一当天男女购买商品比例
select count(distinct user_id) from user_log where gender='0' and action='2';
select count(distinct user_id) from user_log where gender='1' and action='2';
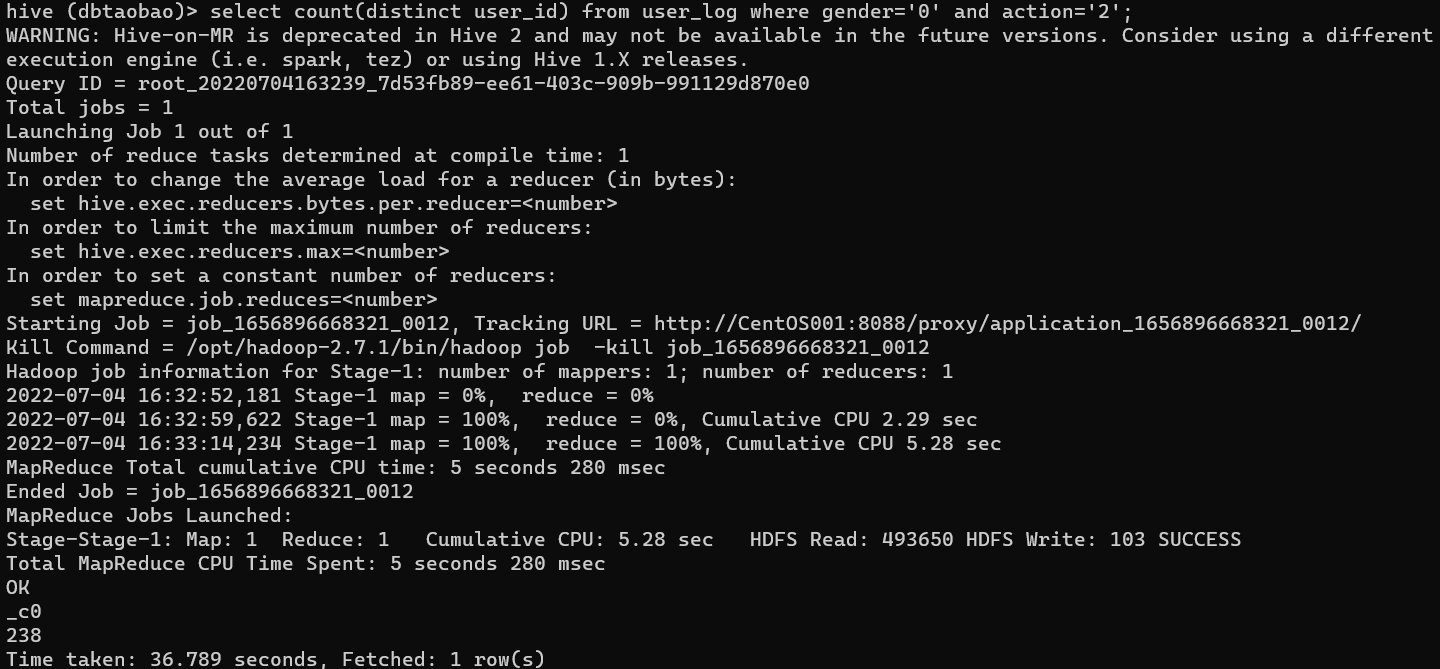
Result : 238 (女)
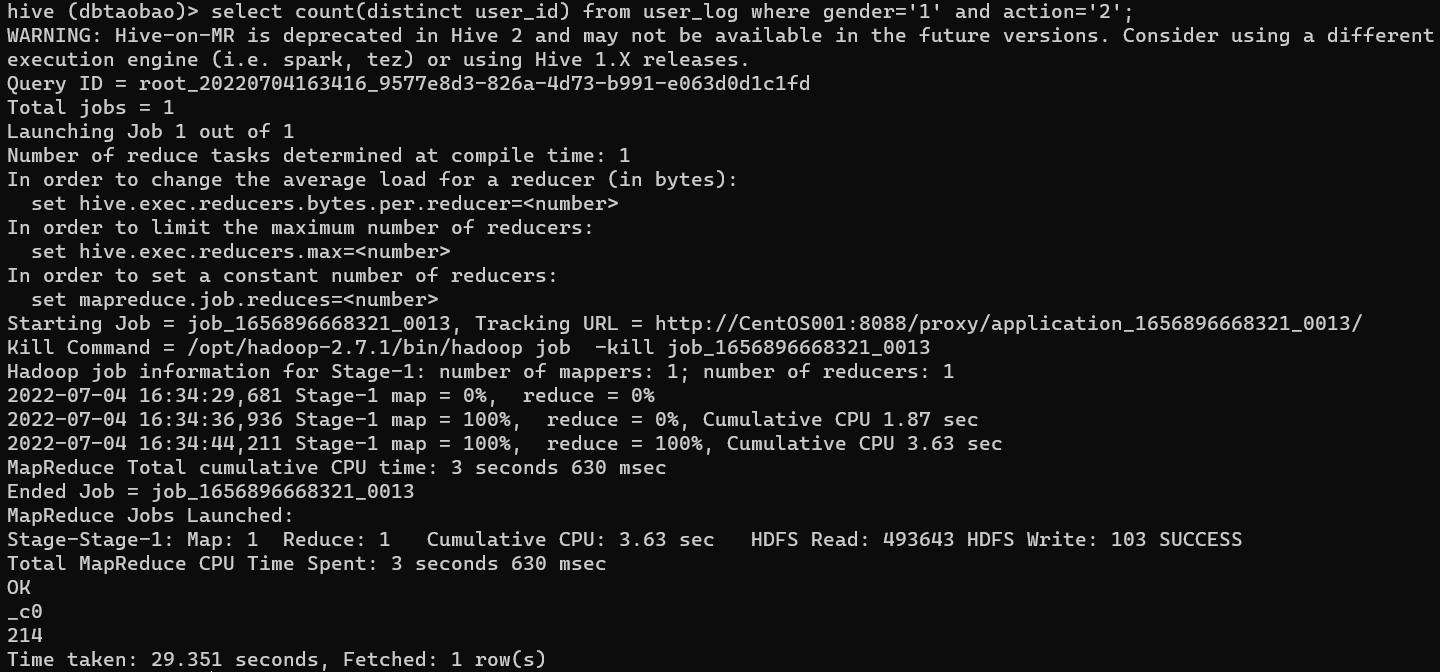
Result : 214 (男)
男 女 比 例 = 214 / 238 = 89.916 % 男女比例 = 214 / 238 = 89.916\% 男女比例=214/238=89.916%
(12)查询某一天在该网站购买商品超过5次的用户id
select user_id from user_log where action='2' group by user_id having count(action='2')>5;

Result :
user_id
1321
6058
16464
18378
23786
26516
32569
35260
41494
47958
55440
61703
69247
70816
71744
84400
106446
106629
153790
161778
171909
173427
179194
186568
188977
196638
203651
211273
212058
212504
217844
219316
234456
242845
249869
251260
256190
261596
270040
272775
274559
278823
278884
283204
284990
289429
310348
310632
320313
328230
330576
332670
333389
345251
356220
356408
366342
370679
378206
379005
389295
396129
407719
409280
422917
(13)创建姓名缩写表,其中字段大于4条,并使查询插入,最后显示姓名缩写表格数据
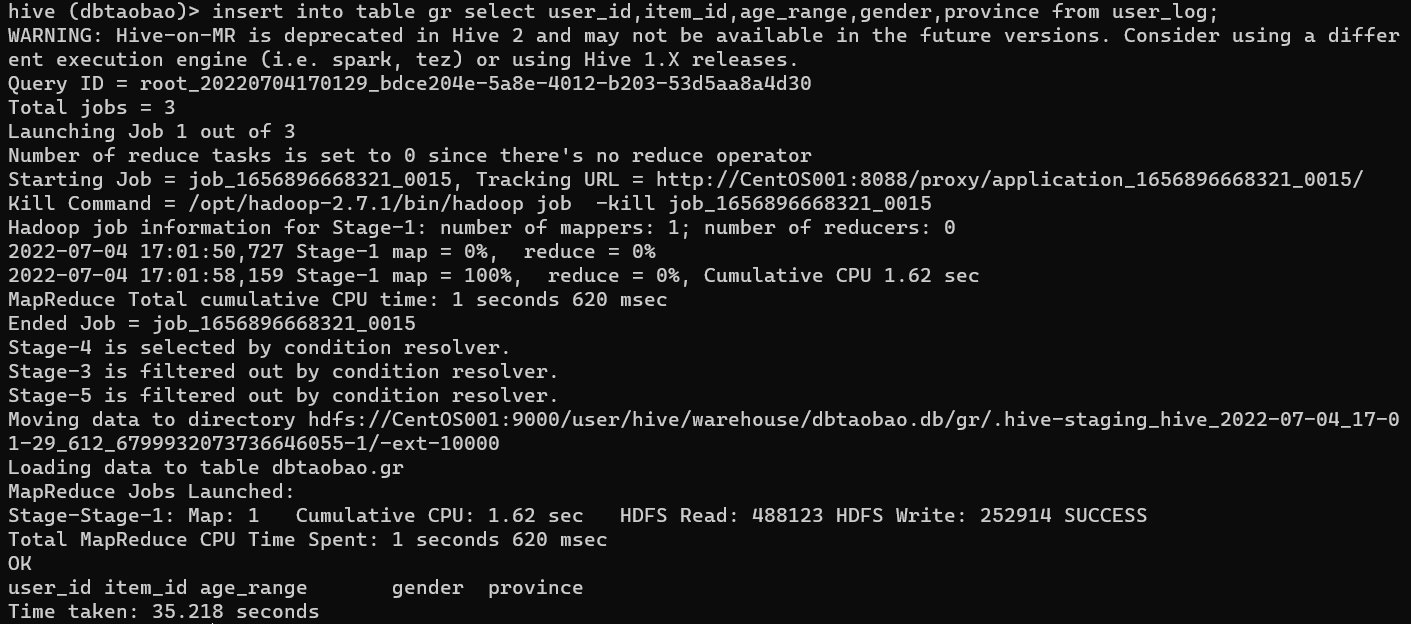
- 创建表gr
create external table dbtaobao.GR(user_id int,item_id int,age_range int,gender int,province string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;

- 从表user_log中导入user_id,item_id,age_range,gender,province数据到表gr
insert into table gr select user_id,item_id,age_range,gender,province from user_log;
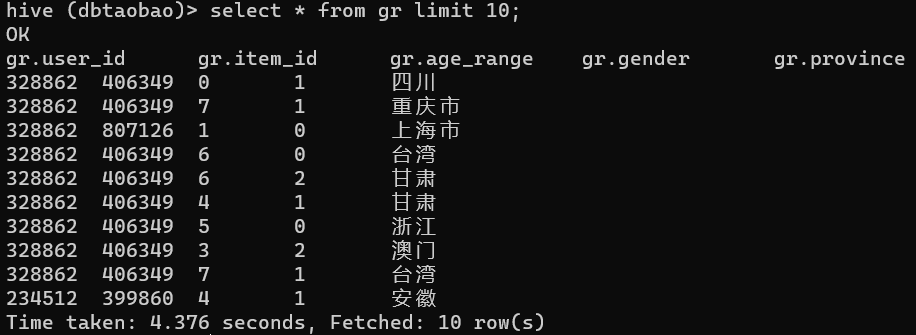
- 查询表gr的前十条数据
select * from gr limit 10;















 1521
1521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









