







前言
本文会介绍流控规则的使用,但是不涉及集群限流,集群限流后续会单独开文章写
流控规则
在dashbaord控制台上,我们可以增加流控规则,如下图
下面我们着重讲解一下源码里面的规则实体,sentinel内部采用的是com.alibaba.csp.sentinel.slots.block.flow.FlowRule 来做流控规则信息的承载,包含如下属性:
resource : 资源名称,用来表示需要限流的资源
limitApp : 针对来源,用来做针对来源限流,默认为:default
grade : 阈值类型, 目前有两种取值类型 1 表示QPS限流, 0 表示线程数限流
count : 流控的单机阈值
strategy : 流控模式,0 . 直接资源(直接限流当前资源,大部分使用这个),1. 关联资源 2.链路限流 这三种模式在下文仔细说明
refResource : 关联资源,在流控模式选择了关联和链路的时候,填写的关联资源/链路就是用这个字段来做承载
controlBehavior : 流控效果, 取值有如下4中, 0 默认,快速失败,1 warm up 预热/冷启动模式 2 ratelimite, 也就是匀速排队模式
- warmup 和ratelimiter 两者结合的模式。 流控效果,本文仅讲快速失败的模式,后面3种会单独文章来进行讲解。
warmUpPeriodSec : warm up模式下,预热的时间,单位:秒
maxQueueingTimeMs : 匀速排队模式下, 最大的等待时间
clusterMode: 是否开启集群限流模式
clusterConfig : 集群 限流配置
controller :流控效果的控制器,根据不同的流控效果,注入不同的控制器
上面就是流控规则的所有属性, 接下来我们就开始聊一下FlowSlot, 流控规则是如下进行生效的。
FlowSlot
在上篇文章中, 聊了一下sentinel的流控设计,整体的核心设计采用的是责任链模式,其中FlowSlot就是负责流控规则的判断的。
源码入口:com.alibaba.csp.sentinel.slots.block.flow.FlowSlot
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
// 规则校验
checkFlow(resourceWrapper, context, node, count, prioritized);
// 规则校验通过,执行下一个slot
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
void checkFlow(ResourceWrapper resource, Context context, DefaultNode node, int count, boolean prioritized)
throws BlockException {
// 调用FlowRuleChecker进行规则校验
checker.checkFlow(ruleProvider, resource, context, node, count, prioritized);
}
这个就是FlowSlot的执行规则校验的核心代码,校验的核心代码不在这里面,都在FlowRuleChecker 这个类里面,下面我们看下这个类的checkFlow方法
FlowRuleCheck#checkFlow
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource,
Context context, DefaultNode node, int count, boolean prioritized)
throws BlockException {
// 判断 代码1
if (ruleProvider == null || resource == null) {
return;
}
// 代码2
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
for (FlowRule rule : rules) {
// 代码3
if (!canPassCheck(rule, context, node, count, prioritized)) {
// 代码 4
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}
代码步骤说明(注意看代码编号):
代码1: 这里主要是做了一个规则判断,ruleProvider 这个是用来获取规则列表的,下面的代码就是ruleProvider 的构成
private final Function<String, Collection<FlowRule>> ruleProvider = new Function<String, Collection<FlowRule>>() {
@Override
public Collection<FlowRule> apply(String resource) {
// Flow rule map should not be null.
Map<String, List<FlowRule>> flowRules = FlowRuleManager.getFlowRuleMap();
return flowRules.get(resource);
}
};
可以清晰的看到,这个里面调用了FlowRuleManager , 这个类负责维护FlowRule , 规则的更新,构建,都是这个类来完成
代码2: 获取规则列表
代码3:循环规则列表,调用canPassCheck方法进行校验
代码4:canPassCheck如果返回了false, 说明进行了限流,则抛出异常FlowException , 异常抛出去,说明限流就开始生效了。
canPassCheck
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
// 代码1
String limitApp = rule.getLimitApp();
if (limitApp == null) {
return true;
}
// 代码2
if (rule.isClusterMode()) {
return passClusterCheck(rule, context, node, acquireCount, prioritized);
}
// 代码3
return passLocalCheck(rule, context, node, acquireCount, prioritized);
}
步骤说明:
代码1: 获取限流的app,这里默认会赋值 default ,如果没有设置,则说明有问题,在数据有问题的情况下,是选择不做限流处理,直接返回true
代码2:判断是否为集群限流 ,如果是集群限流,则走集群限流的逻辑,本文不涉及集群限流的讲解
代码3:本地限流算法执行。
passLocalCheck
下面看一下本地限流算法执行
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
// 代码1
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
// 代码2
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}
步骤说明:
代码1: 获取数据统计的Node, 这个Node里面存储了通过的QPS, 响应时间,blockQps, success等各类信息。可以直接通过这个Node里面的信息判断当前请求是否达到阈值。
static Node selectNodeByRequesterAndStrategy(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node) {
// The limit app should not be empty.
String limitApp = rule.getLimitApp();
int strategy = rule.getStrategy();
String origin = context.getOrigin();
// 限流APP和来源APP一致, && 来源APAP不属于default 和other
if (limitApp.equals(origin) && filterOrigin(origin)) {
// 从这里可以看出,需要指出来源限流,那么流控模式必须是直接来源
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// 返回OriginNode
return context.getOriginNode();
}
// 获取关联Node
return selectReferenceNode(rule, context, node);
} else if (RuleConstant.LIMIT_APP_DEFAULT.equals(limitApp)) {
// 匹配默认的default ,
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// Return the cluster node.
// 如果是直接限流当前资源,则拿ClusterNode
return node.getClusterNode();
}
// 获取关联Node
return selectReferenceNode(rule, context, node);
} else if (RuleConstant.LIMIT_APP_OTHER.equals(limitApp)
&& FlowRuleManager.isOtherOrigin(origin, rule.getResource())) {
// 限流app为other, 并且当前的origin存在规则里面,则
if (strategy == RuleConstant.STRATEGY_DIRECT) {
return context.getOriginNode();
}
// 获取关联Node
return selectReferenceNode(rule, context, node);
}
return null;
}
上面根据限流模式和限流来源获取Node,需要注意的一点是,如果设置的是根据来源限流,那么流控模式必须是 直接 否则的话会根据关联资源来获取Node, 导致实际没有统计到来源。
static Node selectReferenceNode(FlowRule rule, Context context, DefaultNode node) {
String refResource = rule.getRefResource();
int strategy = rule.getStrategy();
if (StringUtil.isEmpty(refResource)) {
return null;
}
// 如果流控模式是关联资源,则获取关联资源的ClusterNode
if (strategy == RuleConstant.STRATEGY_RELATE) {
return ClusterBuilderSlot.getClusterNode(refResource);
}
// 如果流控模式是 链路限流
if (strategy == RuleConstant.STRATEGY_CHAIN) {
// 关联资源不等于 当前上下文名称不一样,说明不是这个链路,返回null
if (!refResource.equals(context.getName())) {
return null;
}
// 等于的话,则返回DefaultNode
return node;
}
// No node.
return null;
}
上面的代码涉及到了流控规则里面的流控模式,这里单独说一下。
直接
strategy == RuleConstant.STRATEGY_DIRECT
针对指定的资源做限流,只要配置里面的资源名称达到阈值,则会直接开始进行限流,这种一般是默认使用的
关联资源
strategy == RuleConstant.STRATEGY_RELATE
关联是什么意思呢?
当关联的资源达到阀值,就限流自己
也就是说给资源A配置了关联资源B, 那么资源B达到了设置的阈值,则限流A资源。
链路模式
只记录链路入口的流量,下面说明一下说明是链路限流
private PigeonService pigeonService;
@RequestMapping("test-xx")
public void test() {
pigeonService.test();
}
@RequestMapping("test-yy")
public void testyy() {
pigeonService.test();
}
test-xx 和test-yy都调用这个pigeonService.test() 这个服务,
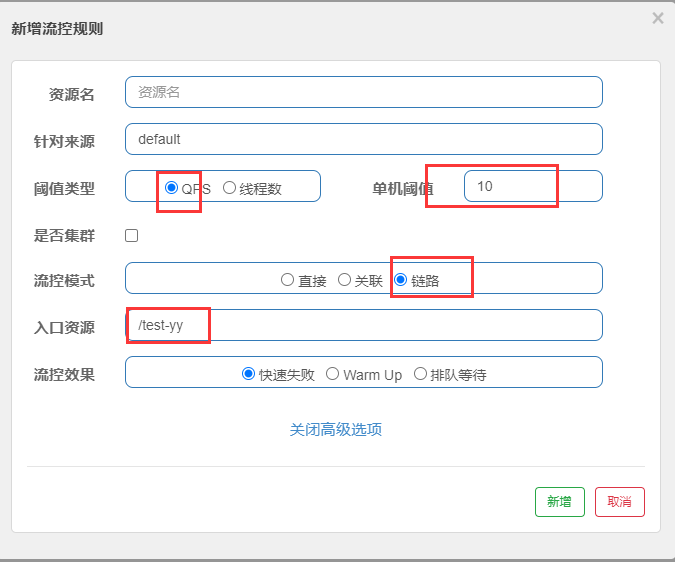
流控规则配置的跟上面一样, 入口资源指定了test-yy , 这种设置的 调用test-xx不会有流量控制,调用test-yy会有流量控制。
所以在上面的源码中,是使用refResource和context.getName() 来做比较,contextName一般是接口的URL。
// 关联资源不等于 当前上下文名称不一样,说明不是这个链路,返回null
if (!refResource.equals(context.getName())) {
return null;
}
获取关联的Node , 如果是关联资源,则获取关联资源的ClusterNode , 如果流控模式是 链路限流,则需要比对关联资源是否等于 当前上下文名称不一样,如果等于,则返回DefaultNode
上面的代码中,总共出现了三种Node
DefaultNode : 代表同个资源在不同上下文中各自的流量情况 , 链路限流的时候使用的是这个,因为入口会被不同的线程调用,所以取的是根据contextName走的DefaultNode
ClusterNode : 代表同个资源在不同上下文中总体的流量情况,默认限流和关联资源限流走的是这个,因为这里面体现的是单个资源最直接的数据。
OriginNode : 是一个StatisticNode类型的节点,代表了同个资源请求来源的流量情况 ,指定来源限流使用的是这个, 因为是根据不同的来源来创建OriginNode , 里面统计的也是这个来源的所有时间窗口数据
代码2:
rule.getRater().canPass(selectedNode, acquireCount, prioritized);
在代码1里面属于获取selectedNode , Node 里面包含了限流拥有的统计信息。 代码2主要就是根据不同的流控效果,来执行不同Controller里面的canPass方法, 本文只介绍DefaultController , 这个是默认的快速失败的流控效果。
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 代码1
int curCount = avgUsedTokens(node);
// 代码2
if (curCount + acquireCount > count) {
// 代码3
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
node.addOccupiedPass(acquireCount);
sleep(waitInMs);
// PriorityWaitException indicates that the request will pass after waiting for {@link @waitInMs}.
throw new PriorityWaitException(waitInMs);
}
}
return false;
}
return true;
}
步骤说明:
代码1:
根据阈值类型,获取线程数或者当前通过的QPS
private int avgUsedTokens(Node node) {
if (node == null) {
// 默认值 0
return DEFAULT_AVG_USED_TOKENS;
}
// 阈值类型判断
return grade == RuleConstant.FLOW_GRADE_THREAD ? node.curThreadNum() : (int)(node.passQps());
}
代码2:
curCount 是根据阈值类型拿出来的当前阈值, acquireCount 是本次申请通过的数量,一般来说为1, count 是规则里面配置的限流阈值。 通过curCount + acquireCount > count 来判断 是否超过阈值了。
注意: 这个地方有一个问题,就是这个判断公式是一个非原子性的, curCount是从Node里面取出来,但是对Node进行统计的是在StatisticSlot 进行统计的,在高并发场景下,如果有多个线程执行到了这个位置curCount + acquireCount > count , 那么得到的结果就不是绝对正确的,会存在一定误差。 所以sentinel的限流,不是绝对准确的,
这种缺陷是基于他的责任链设计,每个slot负责各自的功能,一个统计,一个判断,两者没有在一起,这就必然导致了会有并发问题。 解决方法也有,简单粗暴的加个锁上去。 但是截至到目前位置,sentinel官方好像并没有打算修复这个问题,所以我认为这种高并发下的误差问题是无伤大雅的, 基于性能和准确性的一个综合考量。毕竟限流这种场景要求的准确性并不是很高, qps20 和qps25, 并不会对系统造成很大的影响
代码3:
判断当前的请求是否具有优先级,如果优先级比较高的话,当前时间窗口不够的话,会向接下来的时间借一点流量,保证优先级比较高的请求不会因为偶尔的突发流量而被拒绝掉
sharedCode源码交流群,欢迎喜欢阅读源码的朋友加群,添加下面的微信, 备注”加群“ 。

















 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









