






HTTP协议 : 支撑互联网服务的基础.
HTTP分成两部分,一部分是客户端浏览器的处理过程,另外一部分是服务端的处理过程。客户端和服务端的基本通讯模型非常简单,客户发一个请求,服务端接收到请求后返回一个响应结果
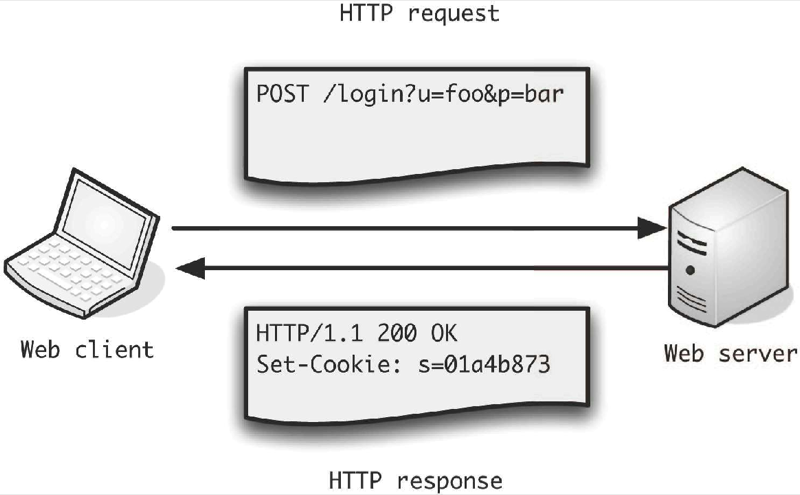
浏览器端
一个HTTP请求再发送到服务端之前是要经过一系列的处理,最后才能到达服务端,大致的步骤是:
- 进行DNS查询,得到服务器的真实IP
- 建立和服务器IP的Socket连接
- 根据HTTP协议规范构建HTTP消息头和消息体,并将之发送到服务端
- 接收到服务端返回的HTTP Response内容,并进行页面的渲染和展示
-
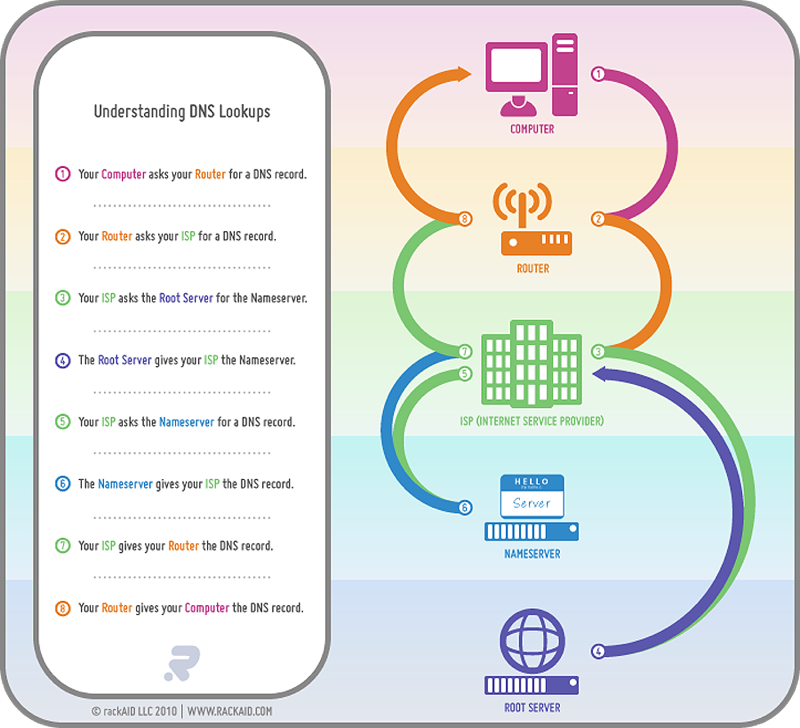
很多同学不知道怎么 google 原因就在DNS的解析
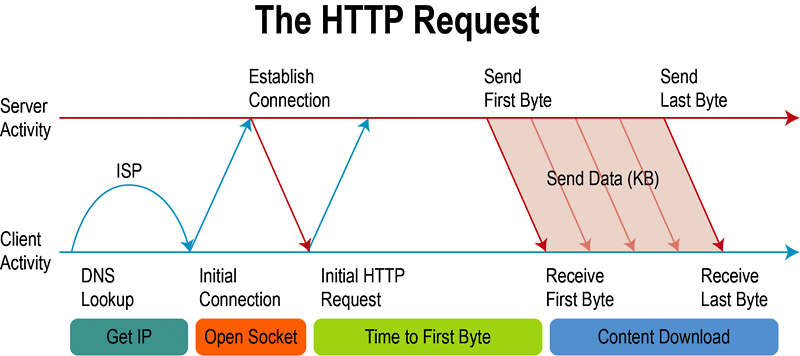
1.建立连接
通过DNS查询获取服务器的真实IP之后,就需要进行网络连接。HTTP协议是构建在TCP/IP之上,类似的还有像FTP、 SMTP、SNMP等协议,这些都是应用层的协议,而TCP/IP是传输层的协议。
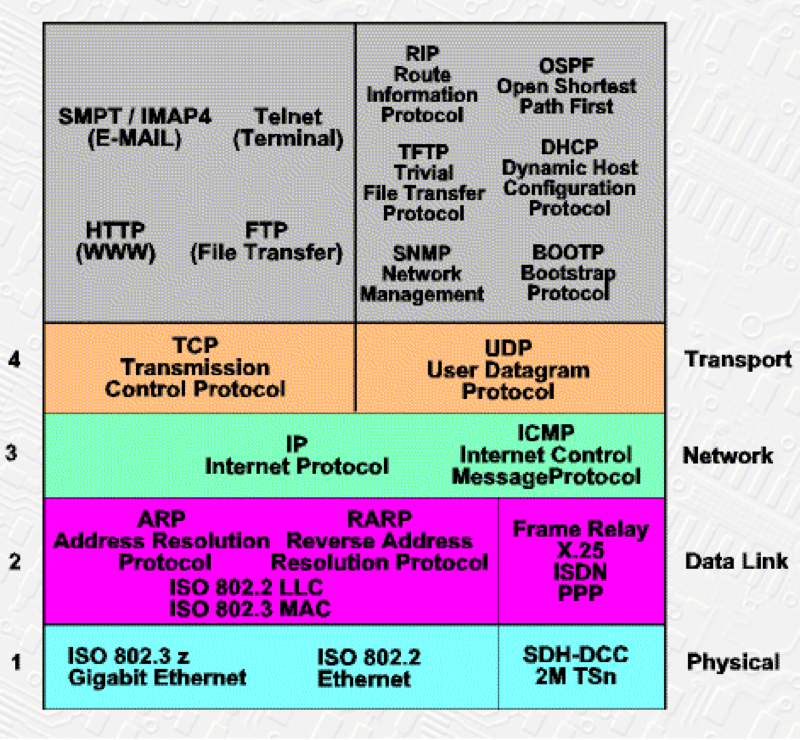
基本的网络层次结构如下所示:
HTTP请求的第一步是通过三次握手的方式建立TCP连接:
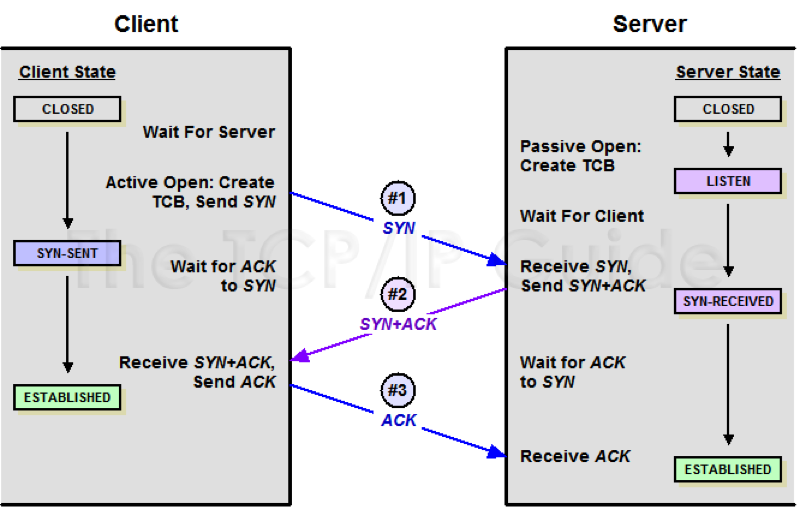
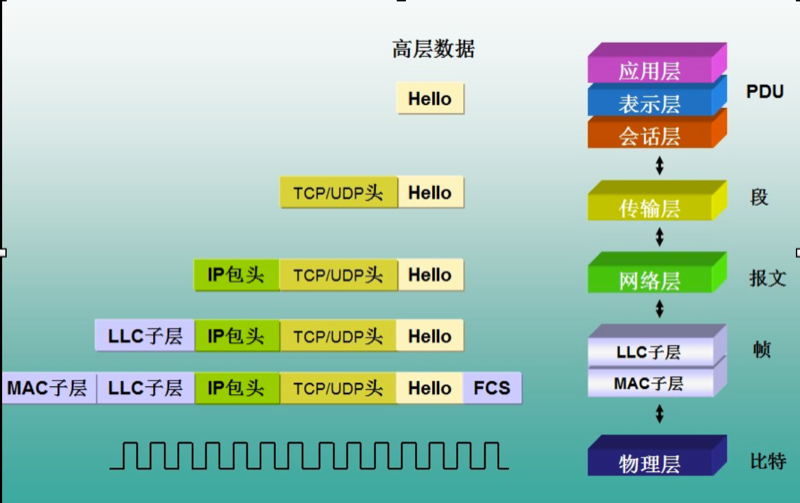
更深入一点,网络通讯模型中,从应用层也就是HTTP层生成原始数据,到TCP层增加TCP头,到IP层增加IP头,一直到物理层,每一层都会添加自己的消息头,到达服务端后再按相反的顺序依次解包
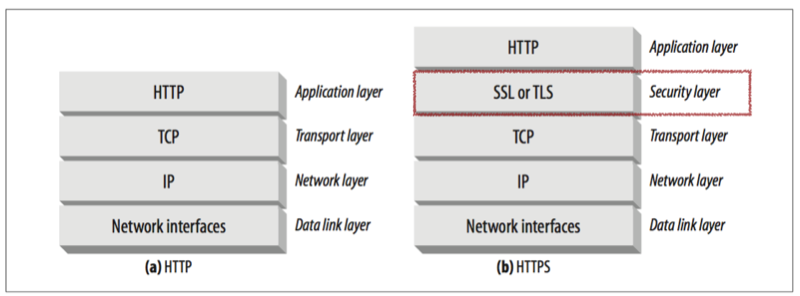
HTTPS是在TCP上面增加了一层SSL/TSL,对明文的HTTP报文进行了加密,防止黑客攻击。
SSL/TSL也是建立在TCP层之上的传输层,它的目的是和服务端协商生成加密的密钥,完成之后报文的传输和HTTP完全一致,只不过一个是明文的,一个是加密后的报文。
2.报文封装
建立TCP或TSL通道到,需要按照HTTP报文协议进行封包。HTTP报文是纯文本的明文,主要包括消息头HTTP Head和消息体HTTP Body两部分。
消息头又分两种,请求时的消息头和响应时的消息头。
前者主要描述请求的主机地址和URL,本地浏览器支持的文本格式、语言和编码方式,浏览器相关的信息,Cookie,是否要保持长连接等信息,
后者主要描述返回的消息内容使用的语言、编码方式、文本格式以及消息体的长度、服务器信息,如果请求头中没有带Cookie的话,响应头可能还包含设置Cookie的信息。
请求时的消息头(Request Header)主要包括:
消息头
Accept : 表示本地浏览器可以接受的媒体类型,比如最常见的:text/html,image/jpeg等,服务端在返回时用Content-Type来指明返回的格式
Accept-Charset : 用来指明可以接受的字符集,如:ascii,utf-8,iso-8859-1等,服务端返回时也在Content-Type中用charset来标明
Accept-Encoding 可接受的编码方式,常见的有非压缩的和压缩格式,比如:gzip,用于减少网络流量传输,提高性能.
Accept-Language : 接受的语言,比如我们中文是 zh_CN ,英文是 us_EN ,可以用权重来标明优先级
From : 请求来自哪里,这里放置的是一个Email,一般用于爬虫,方便对方联系.
Host : 请求的服务器地址和端口
If-Modified-Since : 如果服务端的内容从该字段指定的时间没有发生的变动,服务端返回304,客户端使用缓存中的数据.
Referer : 用来标识这个请求是从哪个URL跳转过来的
User-Agent : 浏览器信息,使用 curl 这种命令行的方式访问的话通常没有这个标识
3.服务器端处理
HTTP在客户端完成封包之后,通过TCP/IP协议将内容发送到服务器端,
服务端通常会使用Apache、Nginx等Web服务器来处理请求,主要是做静态资源文件的处理,比如图片、JS、CSS和Html文件等。
如果是动态资源,比如用户登陆,用户名和密码都是动态输入的,需要到后台数据库进行校验,无法预先生成静态Html文件,因此还需要有专门的模块来处理动态内容。
而Apache本身并不支持动态资源的处理,但它有非常好的可扩展性,通过增加相应的处理模块或者调用后面的应用服务器来完成,比如像PHP这样的脚本语言,可以在Apache上增加mod_php模块来处理.
而像Java这样的编译型语言需要专门的应用服务器Tomcat、Jboss、Jetty等来做业务逻辑的处理,Apache通过HTTP或AJP协议来请求后端的服务。
同时,如果后端是一个集群有多台服务器,还可以用Apache来做负载匀衡,以提高系统的处理能力。
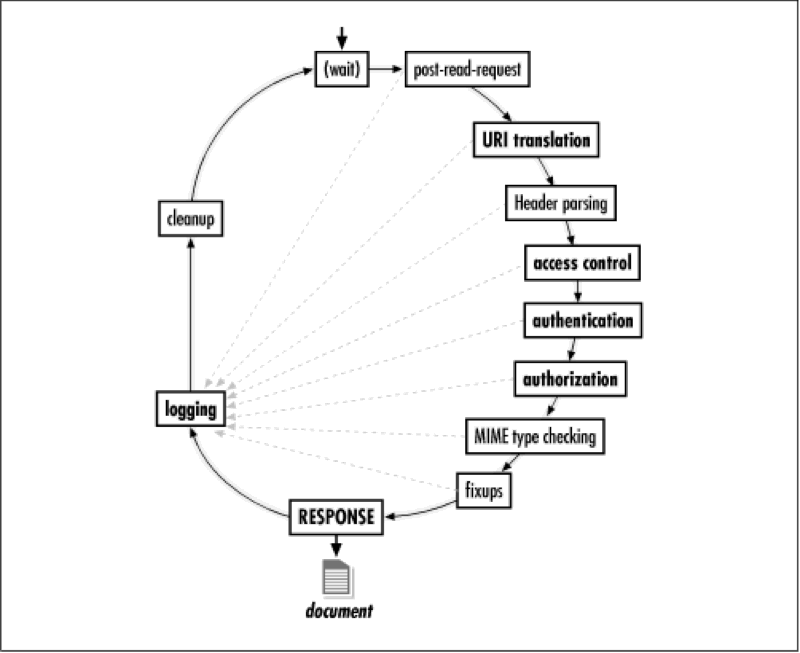
1.wait
打开侦听端口,一般是80端口,等待请求。Apache使用是的prefork模型,和Nginx使用的是epoll模型不一样,是同步阻塞型的模型,每个请求会生成一个对应的进程,当然为了提高响应速度会预先生成一些进程供使用,类似线程池的机制,因此叫prefork。在高并发下,需要打开非常多的进程,CPU来回在进程间切换,导致Apache无法支撑大量并发,而Nginx的epoll模型正式解决这一问题而出现的,号称能支撑几十万的并发请求。Apache还有一种工作模型叫worker,每个进程对应固定的若干个线程,可以支撑更高的并发访问,占用的内存也相对较少。但一般情况prefork比worker方式更高效,因为它比较简单并且稳定,worker中一个线程如果崩溃很可能导致该进程下的所有线程死掉,而prefork模式一个进程只对应一个线程,不会存在这种问题。
2.Post-Read-Request
这一个步只读取Request Line和Request Header,前者就是我们经常看到的HTTP请求的首行,使用浏览器自带的工具查看网络请求时,并不能看到原始的内容,看到是已经经过解析的请求和响应行。不过可以通过Wireshark这样的抓包工具来查看,样例如下:
GET /path HTTP/1.1\r\n
另外就是可以设置环境变量,比如nokeepalived,强制使用短连接进行通讯,或者force-response-1.0强制使用HTTP 1.0 协议。
HTTP请求处理的每一步,都可以放置自己的Hook来实现特别的功能,比如像处理php动态内容的mod_php模块就是通过Hook的方式来实现,如果在第一阶段就想做一些特殊的处理,可以放在这个地方。
3.URI Translation
这个阶段的主要作用就是将URI也就是上面Request Line中的/path映射到实际的文件路径,其中httpd.conf中的DocumentRoot定义的实际文件所在的根路径,Alias设置的文件路径别名都是在这一步实现的。
4.Header Parsing
这个阶段进行请求头检查和解析
5.Access Control
这个阶段主要用来控制访问资源,主要根据主机名、IP地址等,在httpd.conf中的Deny和Order就是用来设置访问控制的,比如为了安全起见,我们暴露在公网的反向代理服务器只允许在我们公司的IP访问,从而可以有限访问外部入侵。
6.Authentication and Authorization
验证和授权
7.MIME Type Checking
这个阶段主要检查资源文件类型,比如资源文件类型、编码格式和语言等。
8.Fix-up
生成响应内容前的一个通用阶段,和Post-Read-Request阶段类似,也是最常用的放置Hook的阶段。
9.Response
生成响应内容,这个是最核心的阶段
10.Logging
记录请求日志
11.Clean up
清理本次请求处理完成后遗留的环境,关闭Socket连接等,是处理的最后一个阶段。
Tomcat
Tomcat首先也是建立侦听,写过Socket程序的人可能对此都不陌生,但现在很多从事Web开发的程序员,从来没有自己写过Socket程序,可能还真不太清楚,就Java程序来说,阻塞式的服务端程序大致如下:
public class Server{
public static void main(String[] args){
try {
ServerSocket ss = new ServerSocket(80);
while(true){
Socket s = ss.accept();
// do something
}
} catch (IOException e) {
e.printStackTrace();
}
}
}不过阻塞式的通讯模式效率低下,如果业务逻辑处理较慢,会导致大量进程阻塞,为了性能会使用更加高效的非阻塞NIO模型。















 6263
6263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









