






* 对于大型的稀疏图,使用邻接链表,相对于用邻接矩阵表示,可以提高算法效率;
* 通用数据结构:数组,链表,树,哈希表;
专用数据结构:栈,队列,优先级队列;
排序:插入排序,希尔排序,快速排序,归并排序,堆排序;
图:邻接矩阵,邻接表;
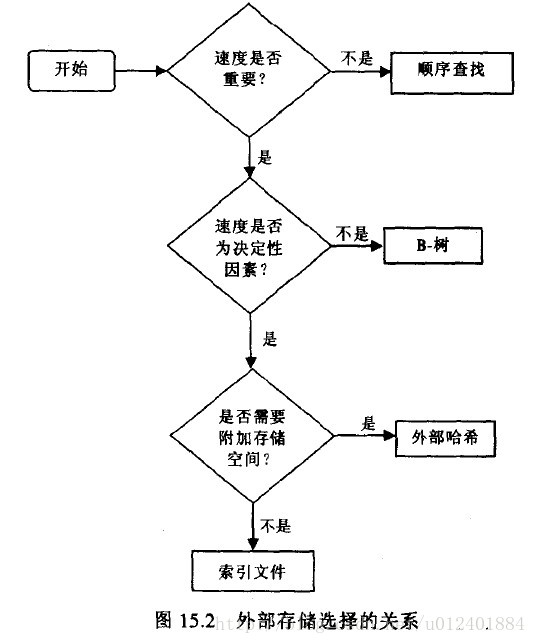
外部存储:顺序存储,索引文件,B-树,哈希方法;
* 请从简单数据结构入手考虑:除非他们明显是太慢了,否则就用数组或链表编写程序,看看结果究竟怎样。如果能在一个可接受的时间内运行完毕,那么就采用他,不必再找别的了。没人会留意用的是数组或别的什么结构,为什么一定要拼命的写出一个平衡树的算法?甚至必须面对成千上万,百万的数据项进行操作时,不妨先看一看数组或链表处理表现的情况,这也还是值得的。只有在实验中发现这些简单结构的性能太慢时,才回头来采用哪些更加复杂的数据结构。
——Robert Lafore的实用主义。
* 数组:数据量较小, 数据量的大小事先可预测;
插入速度重要:使用无序数组;
查找速度重要:使用有序数组+二分查找;
数组删除操作总是很慢;
向量类扩充时,由于要将就得数据拷入一个新的空间中,会造成程序明显的周期性暂停;
* 链表:存储的数据量不能预知,需要频繁的插入删除数据元素,数据量较小;
查找和删除很慢;
* 二叉搜索树:O(logN)级的插入、查找和删除;遍历为O(N)级;如果可以保证数据是随机进入的,就不需要用平衡二叉树;
* 平衡树:红-黑树,2-3-4树;利用树的商用类可以降低编程的复杂性;
* 哈希表:数据存储结构中速度最快;通常用于拼写检查器和作为计算机语言编译器中的符号表;
哈希表需要有额外的存储空间,尤其是对于开放定址法,必须预先精确的知道待存储的数据量;
用链地址法处理冲突的哈希表是最健壮的实现方法;
哈希表不能提供任何形式的有序遍历;

* 栈、队和优先级队列是抽象数据类型(ADT),可以由数组,链表或堆组成;
* 栈通过数组实现很有效率;
* 队可以通过数组,双端链表实现;用链表实现时必须是双端链表,这样才能从一端插入从另一端删除;如果知道会有多少数据量的话,就用数组;否则就用链表;
* 优先级队列可以通过数组,双端链表和堆实现;速度很重要时,使用堆;

* 排序:先尝试一种较慢但简单的排序,例如插入排序;插入排序显得太慢,尝试希尔排序,很容易实现,并且使用起来不会因为条件不同而性能变化差距太大;
只有当希尔排序变得很慢时,才应该使用哪些更复杂但是更快速的排序方法:归并排序,堆排序或快速排序;
归并排序需要辅助存储空间,堆排序需要有一个堆的数据结构,快速排序的时间最短,但是处理非随机性数据时性能不太可靠;对于有可能是非随机性的数据来说,堆排序更加可靠;

* 图:邻接矩阵表示的图的DFS和BFS的时间复杂度为O(V2),V是顶点个数;邻接表表示的图的这两种操作的时间复杂度为O(V+E),E是边的条数;
最小生成树和最短路径在使用邻接矩阵表示时为O(V2),邻接表为O((E+V)logV)级;
* 外部存储:块(Block);为了提高操作速度必须将磁盘的存取速度次数减到最小;
顺序存储:小量数据;
索引文件:使用不同种类的关键字来做多种索引,索引文件存储在磁盘上,只有在需要时才复制进内存;缺点是必须先创建索引,需要对文件进行顺序读取,速度很慢;
B-树:多叉树;O(logN)级,但是编程繁琐;
* 至此,我们到达了对数据结构和算法探索旅程的终点。这个题目很大而且很复杂,没有哪一本书可以让你成为专家,但我们希望本书可以使你学习基础知识更加容易一些。 ——Robert Lafore 《Java数据结构和算法(第二版)》














 9098
9098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









