









基本概念
ByteArrayInputStream:字节数组输入流,继承自 InputStream。它会在内存中创建一个字节数组缓冲区,从输入流读取的数据保存在该字节数组缓冲区中。
ByteArrayOutputStream:字节数组输出流,继承自OutputStream是与 ByteArrayInputStream 相对应的输出流。
实例探究
1.ByteArrayInputStream
下面来看一个完整的实例。
public class Test {
// 英文字母
private static final byte[] ArrayLetters = {
0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67,
0x68, 0x69, 0x6A, 0x6B, 0x6C, 0x6D, 0x6E,
0x6F, 0x70, 0x71, 0x72, 0x73, 0x74, 0x75,
0x76, 0x77, 0x78, 0x79,0x7A };
private static final int LEN = 5;
public static void main(String[] args) throws IOException {
read();
}
private static void read() {
ByteArrayInputStream bis = new ByteArrayInputStream(ArrayLetters);
// 逐个读取字节,输出 a,b,c,d,e
for (int i = 0; i < LEN; i++) {
if (bis.available() != -1) {
int count = bis.read();
System.out.print((char) count);
}
}
System.out.println();
// 判断是否支持标记操作
if (!bis.markSupported()) {
return;
}
// 标记当前字节,即 f(与 reset 配套使用)
bis.mark(0);
// 跳过5个字节,跳过 f,g,h,i,j
bis.skip(5);
//按照字节数组读取,输出结果 k,l,m,n,o
byte[] buf = new byte[LEN];
bis.read(buf, 0, LEN);
System.out.print(new String(buf));
System.out.println();
// 重置字节流,回到 mark 的位置,重新读取字符数组,输出 f,g,h,i,j
bis.reset();
bis.read(buf, 0, LEN);
System.out.print(new String(buf));
}2.ByteArrayOutputStream
public static void main(String[] args) throws IOException {
write();
}
private static void write() throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream(ArrayLetters.length);
// 按字节写入,输出 a
bos.write(0x61);
System.out.println(bos.toString());
// 按字节数组写入,输出 a,b,c,d
bos.write(ArrayLetters, 1, 3);
System.out.println(bos.toString());
// 缓冲数组中的字节数量,输出 4
int size = bos.size();
System.out.println(size);
// 转换成字节数组,输出 a,b,c,d
byte[] buf = bos.toByteArray();
System.out.println(new String(bos.toByteArray()));
//将内容输出到其他流
bos.writeTo(new ByteArrayOutputStream(size));
}源码分析
1.ByteArrayInputStream
首先来看它的类结构,如下图所示。
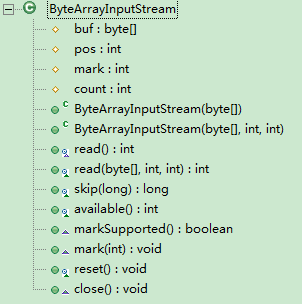
通过类结构图,我们知道它定义了4个成员变量。
//缓冲数组
protected byte buf[];
//索引位置,表示当前读取的位置
protected int pos;
//标记位,标记当前读取的位置
protected int mark = 0;
//要读取的字节数组的长度
protected int count;成员变量的具体意义结合下面的构造函数就能一目了然。
public ByteArrayInputStream(byte buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public ByteArrayInputStream(byte buf[], int offset, int length) {
this.buf = buf;
this.pos = offset;
this.count = Math.min(offset + length, buf.length);
this.mark = offset;
}接下来着重来看它的 read 方法。
//按字节读取
public synchronized int read() {
//判断索引位置,并取出数组上相应位置的值。读取完毕返回 -1。
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
//按字节数组读取
public synchronized int read(byte b[], int off, int len) {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
}
//判断缓冲数组的字节是否已经全部读取
if (pos >= count) {
return -1;
}
//判断要读取的字节数量是否超出了缓冲数组中剩余的字节数量
if (pos + len > count) {
len = count - pos;
}
if (len <= 0) {
return 0;
}
//重点-->将缓冲数组上的字节(从索引位置开始)复制到当前数组中
System.arraycopy(buf, pos, b, off, len);
pos += len;
return len;
}最后再来看看类中剩余的几个方法。
//表示要跳过的字节,通过改变数组的索引位置实现
public synchronized long skip(long n) {
if (pos + n > count) {
n = count - pos;
}
if (n < 0) {
return 0;
}
pos += n;
return n;
}
//返回缓冲数组中剩余可读取的字节数量
public synchronized int available() {
return count - pos;
}
//表示字节数入流默认支持标记
public boolean markSupported() {
return true;
}
//标记字节
public void mark(int readAheadLimit) {
mark = pos;
}
//释放标记的字节
public synchronized void reset() {
pos = mark;
}
//关闭流,是个空方法,说明缓冲数组输入流不需要关闭流操作
public void close() throws IOException {
}2.ByteArrayOutputStream
首先来看它的类结构,如下图所示。

通过类结构图,我们知道它定义了2个成员变量,意义与 ByteArrayInputStream 中的成员变量一样,这里不再阐述。接下来看它的构造方法。
public ByteArrayOutputStream() {
this(32);
}
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: " + size);
}
buf = new byte[size];
}观察代码发现 ByteArrayOutputStream 的操作跟 ByteArrayInputStream 一样,也是通过缓冲数组完成。如果不指定缓冲数组的大小,默认为32。再来着重看看它的 write 方法。
//按字节写入
public synchronized void write(int b) {
int newcount = count + 1;
//判断下一次写入时长度如果超出缓冲数组的容量,则创建新的缓冲数组并将内容复制进入
if (newcount > buf.length) {
buf = Arrays.copyOf(buf, Math.max(buf.length << 1, newcount));
}
//关键-->写入操作
buf[count] = (byte) b;
count = newcount;
}
//按字节数组写入
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) || ((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
int newcount = count + len;
if (newcount > buf.length) {
buf = Arrays.copyOf(buf, Math.max(buf.length << 1, newcount));
}
//关键-->写入操作
System.arraycopy(b, off, buf, count, len);
count = newcount;
}最后再来看看它的其他方法。
//重点 -->将内容输出到其他流
public synchronized void writeTo(OutputStream out) throws IOException {
out.write(buf, 0, count);
}
public synchronized void reset() {
count = 0;
}
//转化成字节数组
public synchronized byte toByteArray()[] {
return Arrays.copyOf(buf, count);
}
public synchronized int size() {
return count;
}
public synchronized String toString() {
return new String(buf, 0, count);
}
public synchronized String toString(String charsetName) throws UnsupportedEncodingException {
return new String(buf, 0, count, charsetName);
}
public synchronized String toString(int hibyte) {
return new String(buf, hibyte, 0, count);
}
//同字节数组输入流一样,不用关闭流
public void close() throws IOException {
}















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











