







基于Hdfs、hive、mysql数据处理案例,闲时自玩项目
数据采集
数据采集方式有很多种,一般在项目中采用数据上报方式。本地为了方便测试则采用读取csv文件。后续python自动抓取数据。
链接: https://pan.baidu.com/s/1cOCe1GXAxtkXCUbvY0MWFw 提取码: r23c
数据量不多,侧重于功能
数据处理
清洗数据,统计分析数据,结果存储HDFS ,加载至HIVE, Sqoop至MYSQL
CSV 数据加载入Hadoop 部分代码
public String transfer(File file, String folderPath, String fileName) throws Exception {
if (!opened) {
throw new Exception("FileSystem was not opened!");
}
boolean folderCreated = fs.mkdirs(new Path(folderPath));
Path filePath = new Path(folderPath, StrUtils.isEmpty(fileName) ? file.getName() : fileName);
boolean fileCreated = fs.createNewFile(filePath);
FSDataOutputStream append = fs.append(filePath);
byte[] bytes = new byte[COPY_BUFFERSIZE];
int size = 0;
FileInputStream fileInputStream = new FileInputStream(file);
while ((size = fileInputStream.read(bytes)) > 0) {
append.write(bytes, 0, size);
}
fileInputStream.close();
return filePath.toUri().toString();
}
将dfs文件加载入hive 部分代码
//表
String yyyyMMdd = hiveTable + DateUtil.formatDate(new Date(), "yyyyMMdd");
//参数
Map<String, String> map = new HashMap<>();
map.put("title", "STRING");
map.put("discountPrice", "STRING");
map.put("price", "STRING");
map.put("address", "STRING");
map.put("count", "STRING");
//创建表 按天分表
hiveDataService.createHiveTable(yyyyMMdd, map);
//将dfs数据加载到hive表
hiveDataService.loadHiveIntoTable(fs.getDfsPath(), yyyyMMdd);
/**
* @param tableName hive表名
* @param parametersMap 表字段值/类型
*/
@Override
public void createHiveTable(String tableName, Map<String, String> parametersMap) {
StringBuffer sql = new StringBuffer("CREATE TABLE IF NOT EXISTS ");
sql.append("" + tableName + "");
StringBuffer sb = new StringBuffer();
parametersMap.forEach((k, v) -> {
sb.append(k + " " + v + ",");
});
sql.append("(" + sb.deleteCharAt(sb.length() - 1) + ")");
sql.append("ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' "); // 定义分隔符
sql.append("STORED AS TEXTFILE"); // 作为文本存储
Log.info("Create table [" + tableName + "] successfully...");
try {
hiveJdbcTemplate.execute(sql.toString());
} catch (DataAccessException dae) {
Log.error(dae.fillInStackTrace());
}
}
/**
* @param filePath dfs文件路径
* @param tableName 表名
*/
@Override
public void loadHiveIntoTable(String filePath, String tableName) {
StringBuffer sql = new StringBuffer("load data inpath ");
sql.append("'" + filePath + "'into table " + tableName);
Log.info("Load data into table successfully...");
try {
hiveJdbcTemplate.execute(sql.toString());
} catch (DataAccessException dae) {
Log.error(dae.fillInStackTrace());
}
}
利用外部表加载dfs数据至分区表
上述代码中有一步为load data 至hive。在于朋友交流中,他提醒可以直接利用
外部加载数据,自此代码如下:
外部表好处
- hive创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变
- 删除表的时候,外部表只删除元数据,不删除数据
- 内部表drop表会把元数据删除
Hive创建外部表
---------------------------------java代码-----------------------------------------
/**
* 利用外部表加载数据
*
* @param tableName hive表名
* @param parametersMap 表字段值/类型
* @param dfsUrl dfs文件地址
*/
@Override
public synchronized void createOuterHiveTable(String tableName, Map<String, String> parametersMap, String dfsUrl) {
StringBuffer sql = new StringBuffer("CREATE EXTERNAL TABLE IF NOT EXISTS ");
sql.append("" + tableName + "");
StringBuffer sb = new StringBuffer();
parametersMap.forEach((k, v) -> {
sb.append(k + " " + v + ",");
});
sql.append("(" + sb.deleteCharAt(sb.length() - 1) + ")");
sql.append(" PARTITIONED BY (day STRING)");
sql.append(" ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' " +
" COLLECTION ITEMS TERMINATED BY '\\002'" +
" MAP KEYS TERMINATED BY '\\003'" +
" LINES TERMINATED BY '\n' "); // 定义分隔符
sql.append("LOCATION '" + dfsUrl + "'"); // 外部表加载hdfs数据目录
Log.info("Create EXTERNAL table [" + tableName + "] successfully...");
try {
hiveJdbcTemplate.execute(sql.toString());
} catch (DataAccessException dae) {
Log.error(dae.fillInStackTrace());
}
}
------------------------------------Sql---------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS xx_outer_partitioned
(
affiliatedbasenum STRING,
locationid STRING,
pickupdate
dispatchingbasenum STRING
)
PARTITIONED BY (day STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
LOCATION '/data/outerClientSummary/';
HIVE分析数据
hive支持sql操作(支持连表操作、排序),支持分区(此功能特别实用,比如数据量庞大时一般会按照天分表,此时就可以利用按天分区)
案列 :统计服装制造商主要城市分布 (因为hive字段与值对应错乱,但是导入至mysql不会错乱)
hive> select count as addr,count(count) from commodity20190315 GROUP BY count;
广东广州 361
浙江杭州 94
广东深圳 87
上海 76
广东东莞 74
江苏苏州 52
浙江嘉兴 24
广东佛山 22
福建泉州 15
北京 14
天津 13
四川成都 12
....... 省略
结果:这是对一千多条的抽样调查,由此可见我们平时的衣物制造商地点广东广州居多。
Sqoop 将分析后HIVE数据导出至MYSQL 主要思想:
sqoop export --connect jdbc:mysql://IP地址:3306/mall --username root --password 123456 --table commodity20190315 --export-dir /hivedata/warehouse/hive.db/commodity20190314 --input-fields-terminated-by ‘,’ --input-null-string ‘\N’ --input-null-non-string ‘\N’
此命令是经过一下错误原因完善出来的。
--export-dir:代表dfs文件目录,则是hive存储数据的地方

错误原因1
19/03/15 09:20:25 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Error parsing arguments for export:
19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: –input-null-string
19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: \N
19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: –input-null-non-string
19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: \N
19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: –input-fields-terminated-by
解决方式 :命令输入错误,注意“-connect”应该是“–connect”杠
错误原因2
19/03/15 09:41:47 ERROR mapreduce.TextExportMapper: Exception:
java.lang.RuntimeException: Can't parse input data: '2019春季新款chic条纹套头毛衣女装学生韩版宽松显瘦百搭长袖上衣,39.98,42.98,广东 广州,350'
at commodity20190314.__loadFromFields(commodity20190314.java:487)
at commodity20190314.parse(commodity20190314.java:386)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:89)
java.lang.Exception: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
Caused by: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:122)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
解决方式 :检查数据是否包含“ ”空格,去掉空格,hive默认分割符–input-fields-terminated-by ‘,’,后续发现mysql表多了id,hive没有导致转码出错。
成功将HIVE数据导入MYSQL

统计/分析
因数据量较小,则想利用python爬取数据,数据量偏少。则通过第三方地址下载。
爬取今日头条
今日头条每天新闻信息在100条左右,最多抓取5天之内的数据。数据量极少。

HIVE数据分析
数据集资源来源:http://dataju.cn/Dataju/web/home 里面包含各种类数据集M-T级文件不等。是一个自娱自玩数据来源的好地址。
总条数
14270481条
hive> select count(*) from commodity20190320;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20190320095041_1829fe55-336b-4481-a869-0b24ea274854
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2019-03-20 09:50:43,908 Stage-1 map = 0%, reduce = 0%
2019-03-20 09:50:45,926 Stage-1 map = 100%, reduce = 0%
2019-03-20 09:50:46,936 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1948148359_0001
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 4150522476 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
14270481
Time taken: 6.276 seconds, Fetched: 1 row(s)
按时间动态分区
commodity20190320此表是通过csv导入的全量数据,包含了时间段。
使用动态分区需要注意设定以下参数:
- hive.exec.dynamic.partition
默认值:false是否开启动态分区功能: 默认false关闭- hive.exec.dynamic.partition.mode
默认值:strict动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。
- hive.exec.max.dynamic.partitions.pernode
默认值:100- 在每个执行MR的节点上,最大可以创建多少个动态分区。
- 该参数需要根据实际的数据来设定。
- 比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
- hive.exec.max.dynamic.partitions
默认值:1000- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
- hive.exec.max.created.files
默认值:100000- 整个MR Job中,最大可以创建多少个HDFS文件。
- 一般默认值足够了,除非你的数据量非常大,需要创建的文件数大于100000,可根据实际情况加以调整。
//查看表结构
hive> desc commodity20190320;
OK
affiliatedbasenum string
locationid string
pickupdate string
dispatchingbasenum string
Time taken: 0.044 seconds, Fetched: 4 row(s)
//创建按月按天分区表
hive> CREATE TABLE commodity_partitioned (
> affiliatedbasenum STRING,
> locationid STRING,
> dispatchingbasenum STRING
> ) PARTITIONED BY (month STRING,day STRING)
> stored AS textfile;
OK
Time taken: 0.238 seconds
//设置动态分区属性
hive> SET hive.exec.dynamic.partition=true;
hive> SET hive.exec.dynamic.partition.mode=nonstrict;
hive> SET hive.exec.max.dynamic.partitions.pernode = 1000;
hive> SET hive.exec.max.dynamic.partitions=1000;
//时间格式 pickupdate = "5/31/2014 23:59:00" 按天分区则获取年月日即可。利用substr函数:substr(affiliatedbasenum,2,1) AS month,substr(affiliatedbasenum,2,9) AS day
//向分区添加数据
hive> INSERT overwrite TABLE commodity_partitioned PARTITION (month,day)
> SELECT locationid,pickupdate,dispatchingbasenum,substr(affiliatedbasenum,2,1) AS month,substr(affiliatedbasenum,2,9) AS day
> FROM commodity20190320;
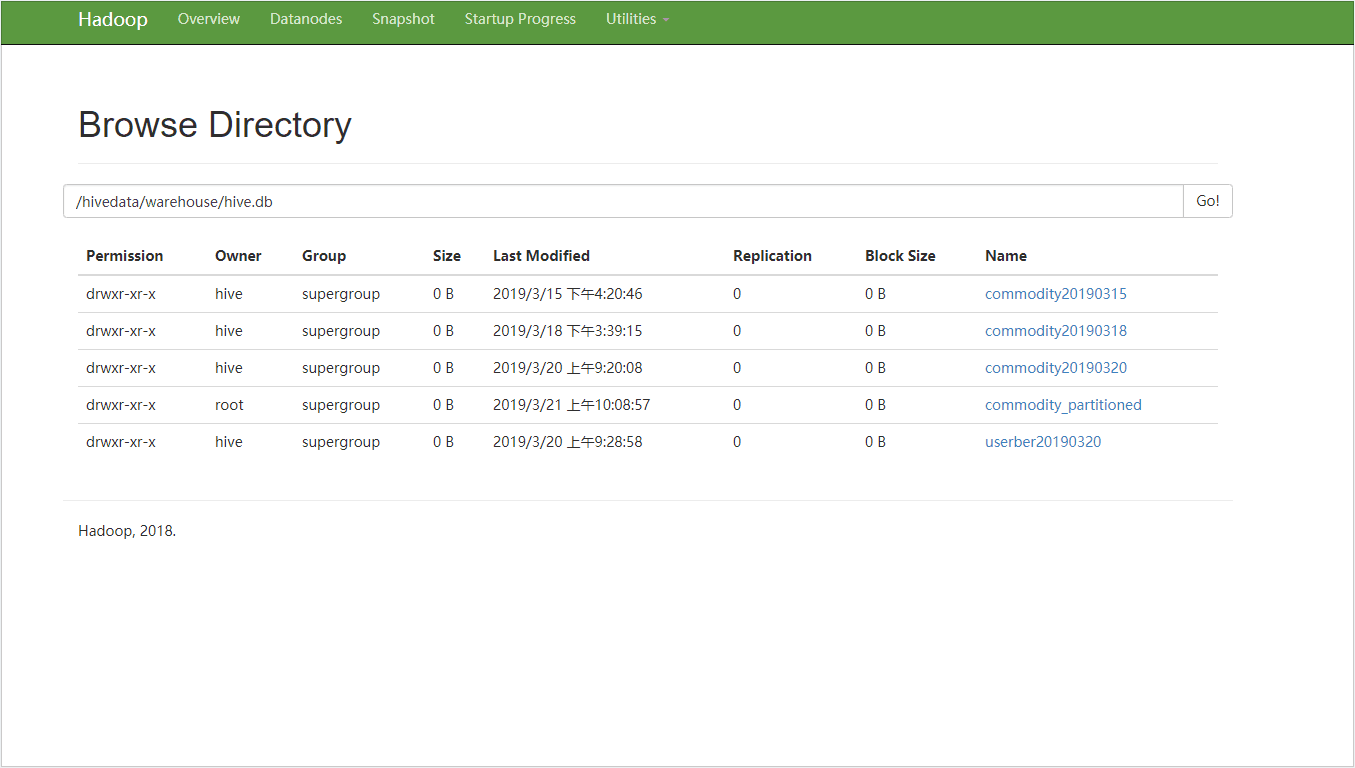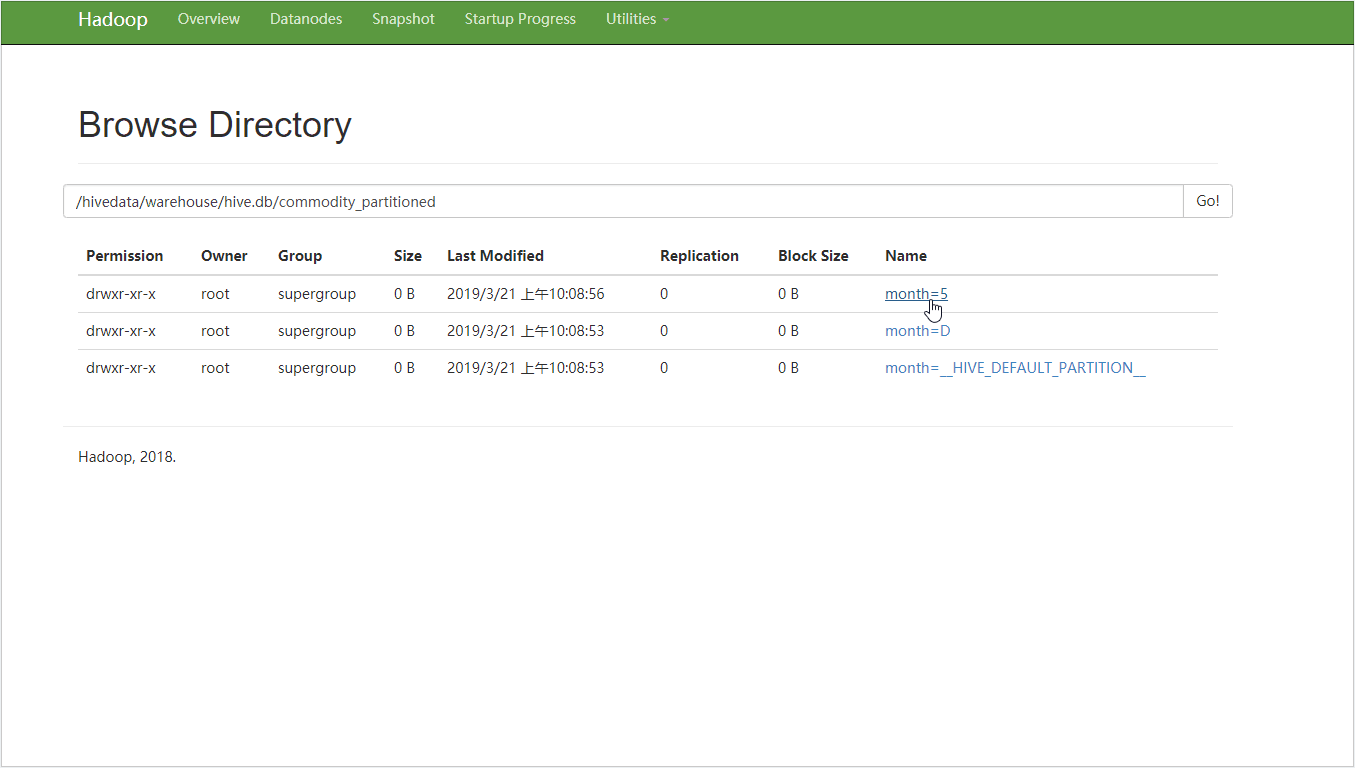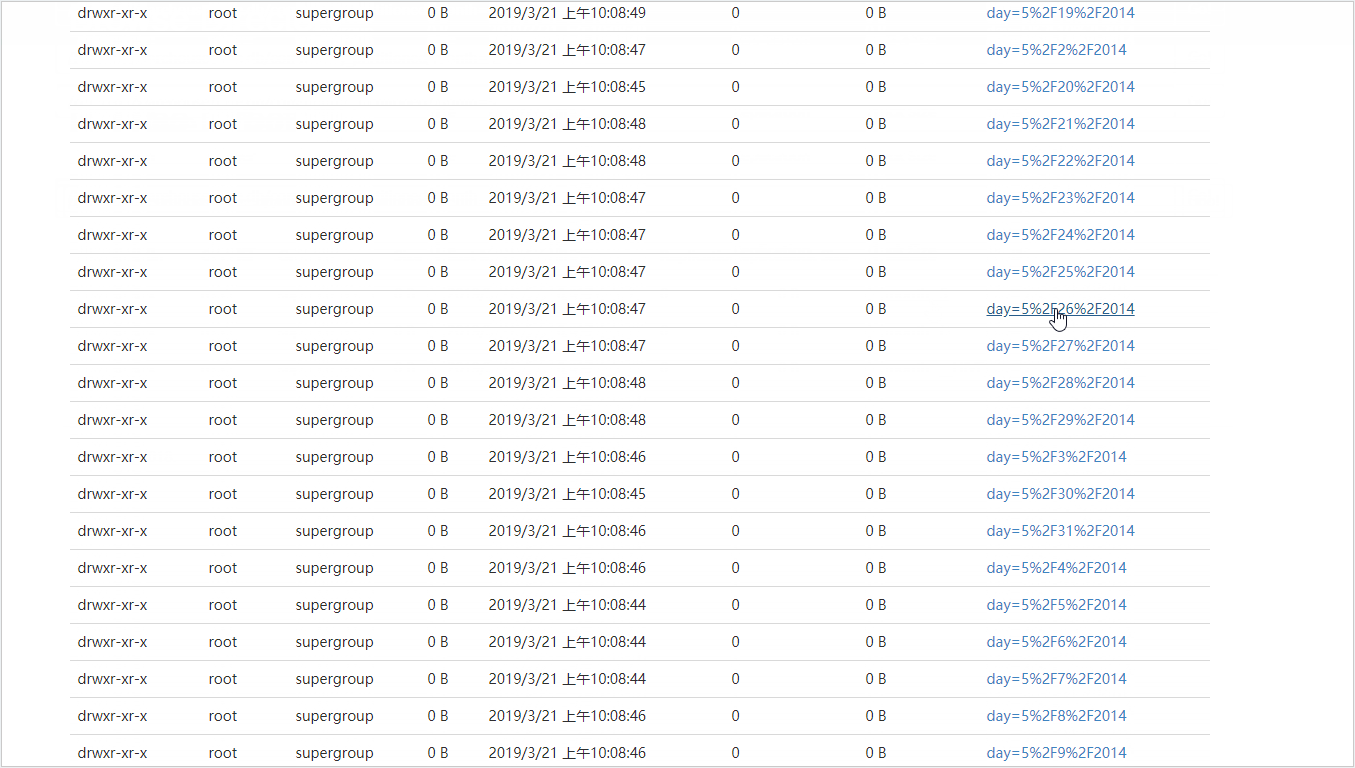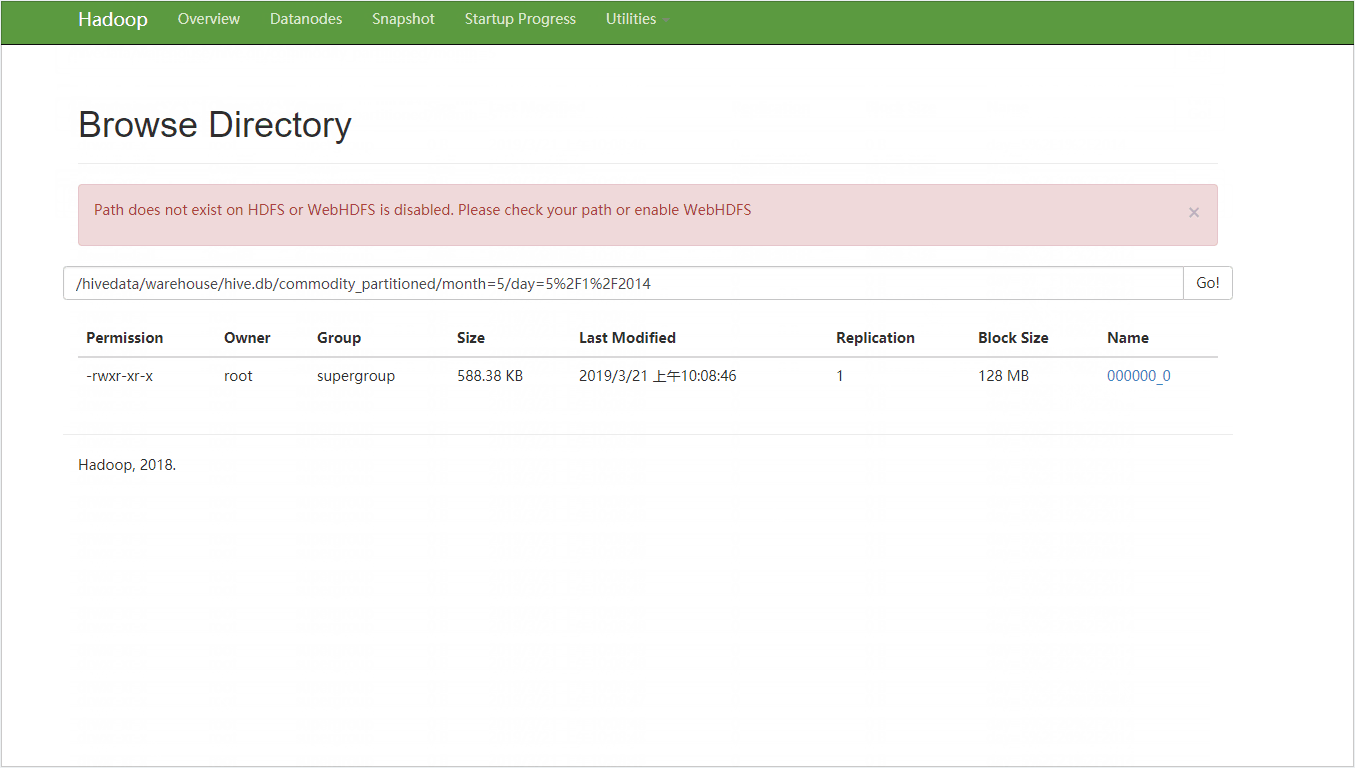
为外部表挂载分区
---------------------------------java代码-----------------------------------------
/**
* @param tableName 外部表名
* @param yyyyMMdd 分区标识
* @param dfsUrl dfs地址
*/
@Override
public void loadOuterHiveDataPartitions(String tableName, String yyyyMMdd, String dfsUrl) {
StringBuffer sql = new StringBuffer("alter table " + tableName);
sql.append(" add partition (day='" + yyyyMMdd + "') location '" + dfsUrl + yyyyMMdd + "/'");
Log.info("Load data into OuterHiveDataPartitions successfully...");
try {
hiveJdbcTemplate.execute(sql.toString());
} catch (DataAccessException dae) {
Log.error(dae.fillInStackTrace());
}
}
---------------------------------Sql-----------------------------------------
alter table uber_outer_partitioned add partition (day='2019-03-21') location '/data/outerClientSummary/2019-03-21'

注意:分区数据支持sql查询
总结
对于大数据初学者的我,这才是我的第一步,都说万事开头难,坚持吧。
- 知道如何把已有的数据采集到HDFS上,包括离线采集和实时采集;
- 知道sqoop是HDFS和其他数据源之间的数据交换工具,支持把数据在HDFS\HIVE\MYSQL互相传输;
- 知道Hadoop的MRV1与Yarn(MRV2)的区别,最主要的单点故障以及性能大大提升。
- JobTracker被RescourceManager替换
- 每一个节点的TaskTacker被NodeManager替换
- Yarn大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗。
- 监测每一个 Job 子任务 (tasks) 状态的程序分布式化了
- Hive外部表被删除时,不会删除元数据,可以直接在外部表基础啊上创建分区表。
- Hive一般作为数据仓库,几乎不会被用作与OLAP操作
- 原因则在于hive数据量庞大时查询速度太慢.
下一章则会着重介绍.
- 原因则在于hive数据量庞大时查询速度太慢.















 6824
6824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











