









自我学习就是稀疏编码器串联一个Softmax分类器,上一节看到,训练400次,准确率为98.2%
在此基础上,我们可以搭建我们的第一个深度网络:栈式自编码(2层)+Softmax分类器
简单地说,我们把稀疏自编码器的输出作为更高一层稀疏自编码器的输入。
和自我学习很像,似乎就是新加了一层,但是其实不然:
新技巧在于,我们这里有个微调的过程,让残差从最高层向输入层传递,微调整个网络权重。
这个微调对于网络性能的提高非常明显,实际上后面将会看到。
网络结构如图所示:
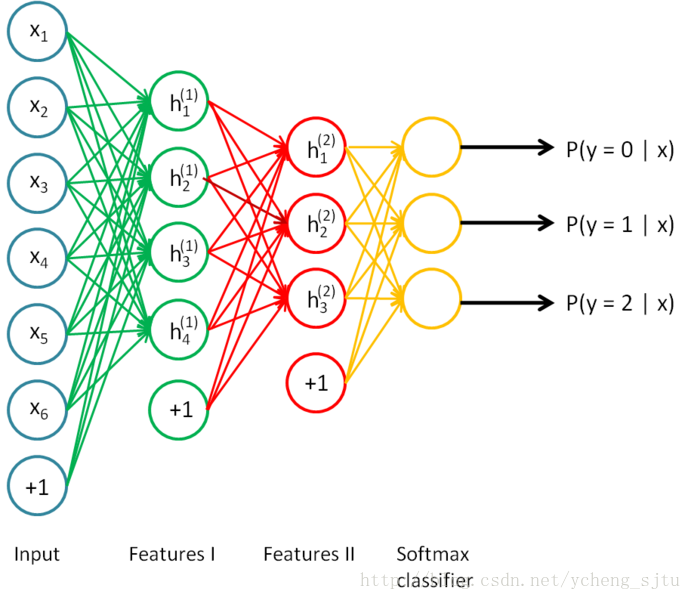
图1
预先加载
minFunc
computeNumericalGradient
display_network
feedForwardAutoencoder
initializeParameters
loadMNISTImages
loadMNISTLabels
softmaxCost
softmaxTrain
sparseAutoencoderCost
train-images.idx3-ubyte
train-labels.idx1-ubyte
训练第一个稀疏编码器
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 400;
options.display = 'on';
[sae1OptTheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
inputSize,hiddenSizeL1, ...
lambda, sparsityParam, ...
beta, trainData), ...
sae1Theta, options);训练第二个稀疏编码器
sae2options.Method = 'lbfgs';
sae2options.maxIter = 400;
sae2options.display = 'on';
[sae2OptTheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
hiddenSizeL1, hiddenSizeL2, ...
lambda, sparsityParam, ...
beta, sae1Features), ...
sae2Theta, sae2options);训练Softmax分类器
smoptions.maxIter = 100;
[softmaxModel] = softmaxTrain(hiddenSizeL2, numClasses, lambda, ...
sae2Features,trainLabels, smoptions);
saeSoftmaxOptTheta = softmaxModel.optTheta(:);微调整个网络
ftoptions.Method = 'lbfgs';
ftoptions.display = 'on';
ftoptions.maxIter = 100;
[stackedAEOptTheta, cost] = minFunc( @(p) stackedAECost(p,...
inputSize,hiddenSizeL2, ...
numClasses, netconfig, ...
lambda,trainData,trainLabels), ...
stackedAETheta, ftoptions);代价函数与梯度
a2=sigmoid(bsxfun(@plus,stack{1}.w*data,stack{1}.b));
a3=sigmoid(bsxfun(@plus,stack{2}.w*a2,stack{2}.b));
temp=softmaxTheta*a3;
temp=bsxfun(@minus, temp, max(temp, [], 1));%防止数据溢出
hypothesis=bsxfun(@rdivide,exp(temp),sum(exp(temp)));%得到概率矩阵
cost=-(groundTruth(:)'*log(hypothesis(:)))/M+lambda/2*sumsqr(softmaxTheta);%代价函数
softmaxThetaGrad=-(groundTruth-hypothesis)*a3'/M+lambda*softmaxTheta;%梯度函数
Delta3=softmaxTheta'*(hypothesis-groundTruth).*a3.*(1-a3);
Delta2=(stack{2}.w'*Delta3).*a2.*(1-a2);
stackgrad{2}.w=Delta3*a2'/M;
stackgrad{2}.b=sum(Delta3,2)/M;
stackgrad{1}.w=Delta2*data'/M;
stackgrad{1}.b=sum(Delta2,2)/M;预测函数
a2=sigmoid(bsxfun(@plus,stack{1}.w*data,stack{1}.b));
a3=sigmoid(bsxfun(@plus,stack{2}.w*a2,stack{2}.b));
[~,pred]= max(softmaxTheta*a3);%记录最大概率的序号而不是最大值经过2个多小时的训练,最终效果非常不错:
BeforeFinetuning Test Accuracy: 86.620%
AfterFinetuning Test Accuracy: 99.800%
可见微调对于深度网络的训练起着至关重要的作用。
欢迎参与讨论并关注本博客和微博以及知乎个人主页后续内容继续更新哦~
转载请您尊重作者的劳动,完整保留上述文字以及文章链接,谢谢您的支持!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









