






深度学习(Deep Learning),自然语言处理(NLP)及其表达(Representation)
简介
过去几年中,深度神经网络在模式识别领域占据着统治地位。他们在诸多计算机视觉任务领域,将之前的最好算法彻底击败。语言识别也正朝着这个方向发展。
They blew the previous state of the art out of the water for many computer vision tasks.
尽管如此,我们不禁要问,DNN(Deep Neural Networks)为什么这么好?
本文列举了一些将DNN在自然语言处理方面的出色成果。通过这种方式,我希望对于DNN为何有效果提供一个不错的答案。
单隐含层神经网络
带有一个隐含层的神经网络具有通用性(Universality):给定足够的隐藏节点,它能够你和任意函数。这是一个经常被引用,但是被误解的“定理”。
这基本上是正确的,因为隐含层可以被当成是查找表(lookup table)来使用。
为简明起见,先考虑感知机(perception)网络。感知机是非常简单的神经元,超出阈值就激活,反之不激活。感知机网络的都以二进制作为输入和输出。
需要注意的是可能的输入类型是有限的。对于每一个可能的输入,我们都可以在隐含层构建一个仅对其激活的神经元。然后我们可以利用隐藏层与输出层直接的连接来控制输出层的特定样本。如图1所示。
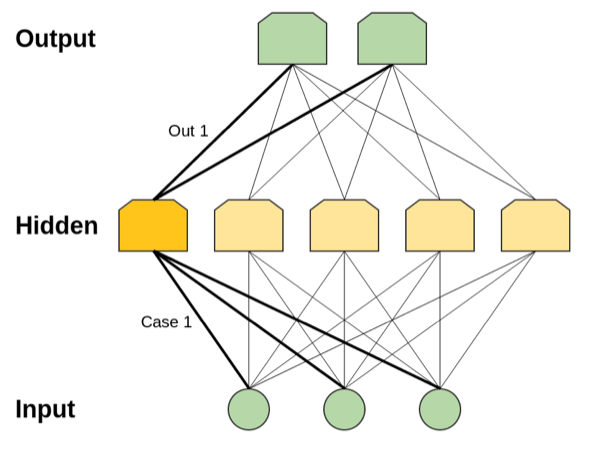
事实上,具有单层的神经网络是通用的。但是这完全没有什么值得让人感到兴奋的地方。你的模型能够达到和查找表格一样的能力,但这并不是让人觉得这个模型很好的有力依据。这是表示,你的模型仅仅只是有可能完成相应任务而已。
通用性意味着网络可以拟合你任意给定的数据。但是却并不意味着能够以合理方式生成合理的新数据点。
因此,通用性并不能很好地解释为何神经网络效果这么好。真正的原因是更加微妙的,为了理解这些,我们需要首先去理解一些具体的结果。
单词嵌入(Word Embedding)
我希望通过介绍一个深度学习中的有趣实例来作为开始:单词嵌入。我认为单词嵌入是目前深度学习中最有趣的研究领域,尽管这个问题Bengio等人在10年前就已经提出了。此外,我认为这是从直觉上理解为何深度学习如此有效的最好方式。
一个单词嵌入操作:
单词嵌入定义了语言中的单词到高维向量的一个映射函数(可能是从200维到500维)。例如:
W(“cat”) = (0.2, -0.4, 0.7, …)
W(“mat”) = (0.0, 0.6, -0.1, …)
通常函数就是一个查找表格,由一个矩阵 θ 参数化,其中每个词占一行:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









