








本节模拟几个综合应用场景
- SQL On Spark:使用 sqlContext 查询年纪大于等于 10 岁的人名
- Hive On Spark:使用了 hiveContext 计算每年销售额
- 店铺分类,根据销售额对店铺分类,使用 sparkSQL 和 MLLib 聚类算法
PageRank,计算最有价值的网页,使用 sparkSQL 和 GraphX 的 PageRank 算法
以下实验采用 IntelliJ IDEA 调试代码,最后生成 LearnSpark.jar,然后使用 spark-submit
提交给集群运行。1 SQL On Spark
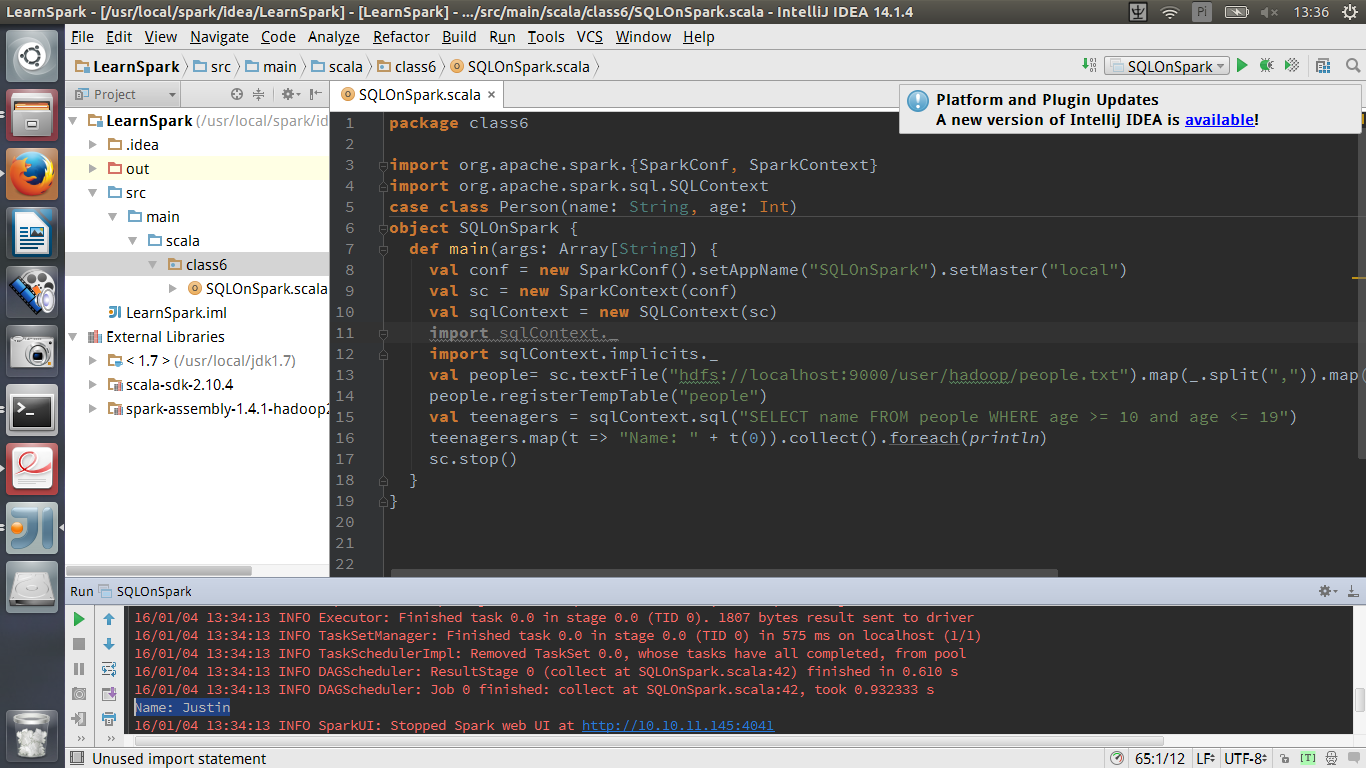
测试程序如下
1 在IDEA中本地运行
package class6
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SQLContext
case class Person(name: String, age: Int)
object SQLOnSpark {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("SQLOnSpark").setMaster("local")
//在 IDEA 中需要在 SparkConf 添加
//setMaster("local")设置为本地运行
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext._
import sqlContext.implicits._
val people= sc.textFile("hdfs://localhost:9000/user/hadoop/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 10 and age <= 19")
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
sc.stop()
}
}
运行结果
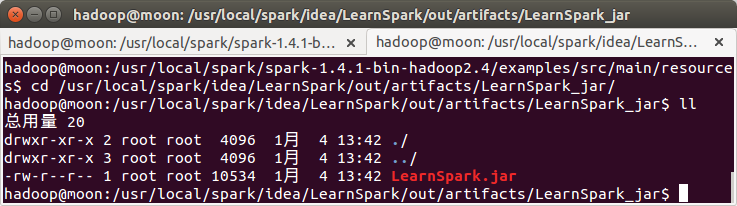
打包提交运行
提交到集群
spark-submit --master spark://moon:7077 --class class6.SQLOnSpark --executor-memory 1g LearnSpark.jar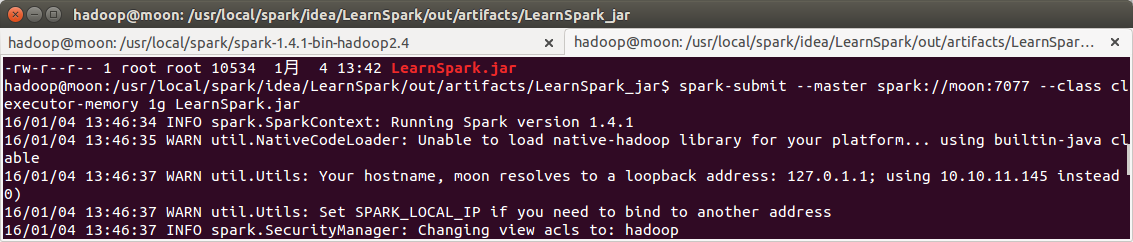
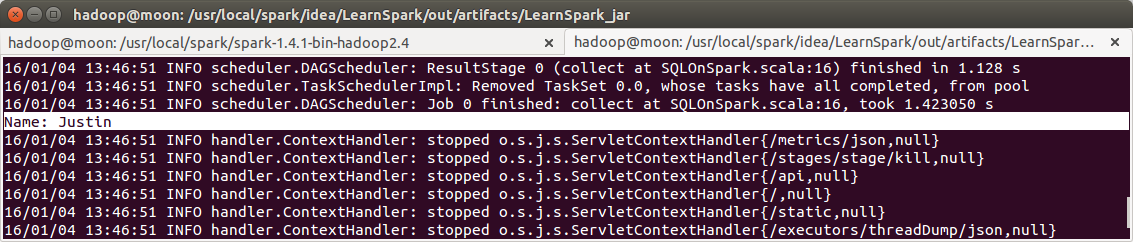
Hive On Spark
package class6
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-4.
*/
object HiveOnSpark {
case class Record(key:Int,value:String)
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("HiveOnSpark")
val sc = new SparkContext(sparkConf)
val HiveContext = new HiveContext(sc)
import HiveContext._
sql("use hive")
sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a " +
"join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on " +
"a.dateid=c.dateid group by c.theyear order by c.theyear")
.collect().foreach(println)
sc.stop()
}
}
打包提交到集群,这里注意确认已经启动hive,如果没有启动,通过命令启动:
$nohup hive --service metastore > metastore.log 2>&1 &打包后提交到集群
spark-submit --master spark://moon:7077 --class class6.HiveOnSpark --executor-memory 1g LearnSpark.jar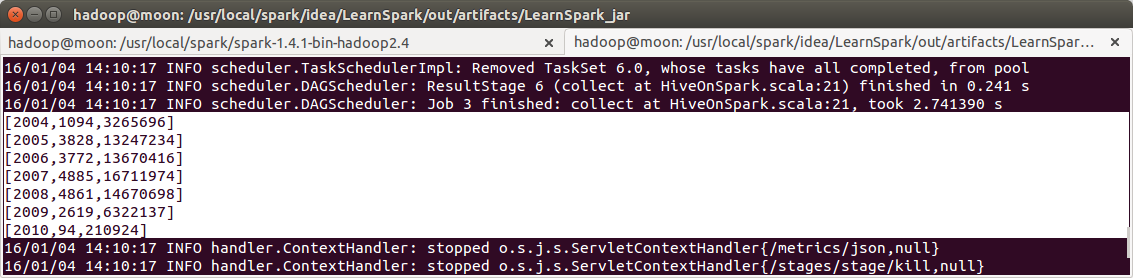
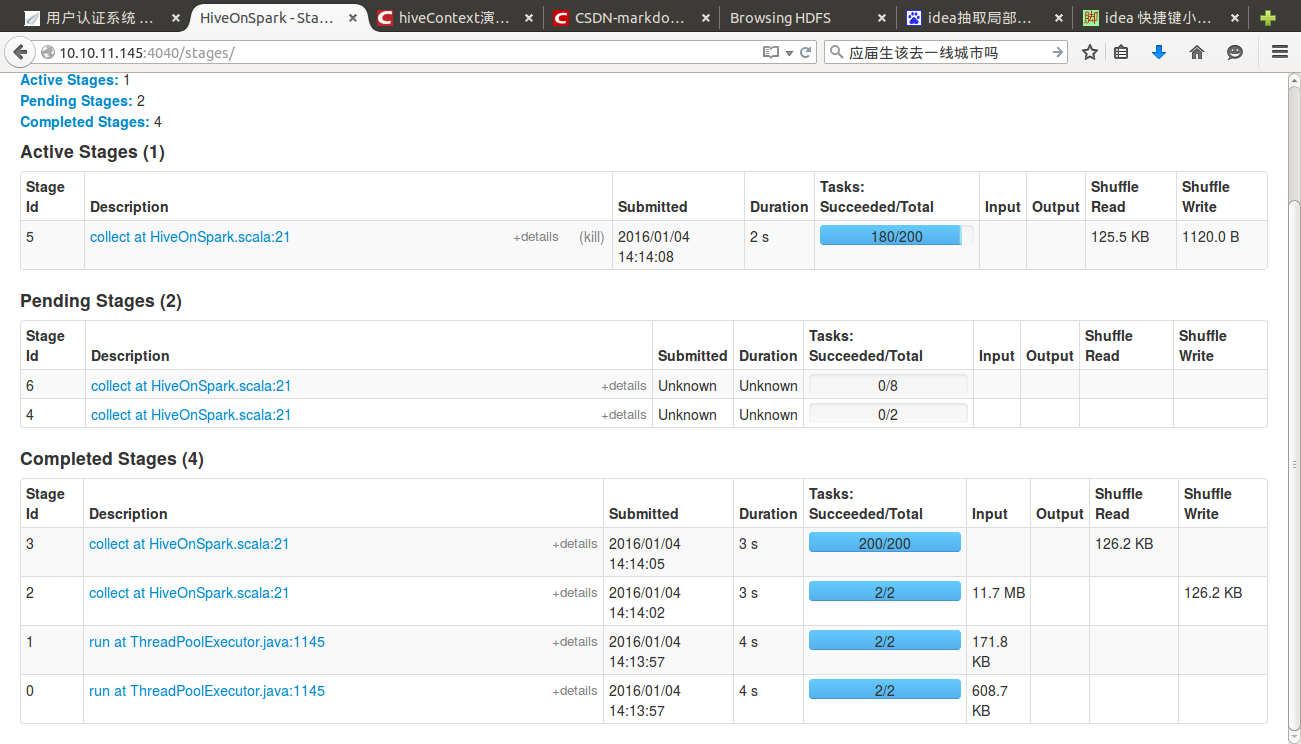
店铺分类
分类在实际应用中非常普遍,比如对客户进行分类、对店铺进行分类等等,对不同类别采取
不同的策略,可以有效的降低企业的营运成本、增加收入。机器学习中的聚类就是一种根据不
同的特征数据,结合用户指定的类别数量,将数据分成几个类的方法。下面举个简单的例子,
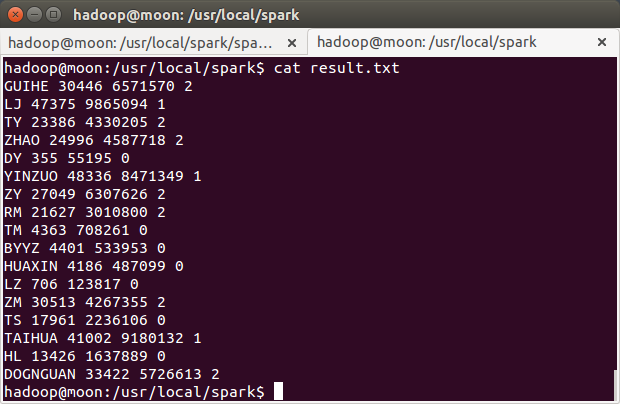
按照销售数量和销售金额这两个特征数据,进行聚类,分出 3 个等级的店铺。
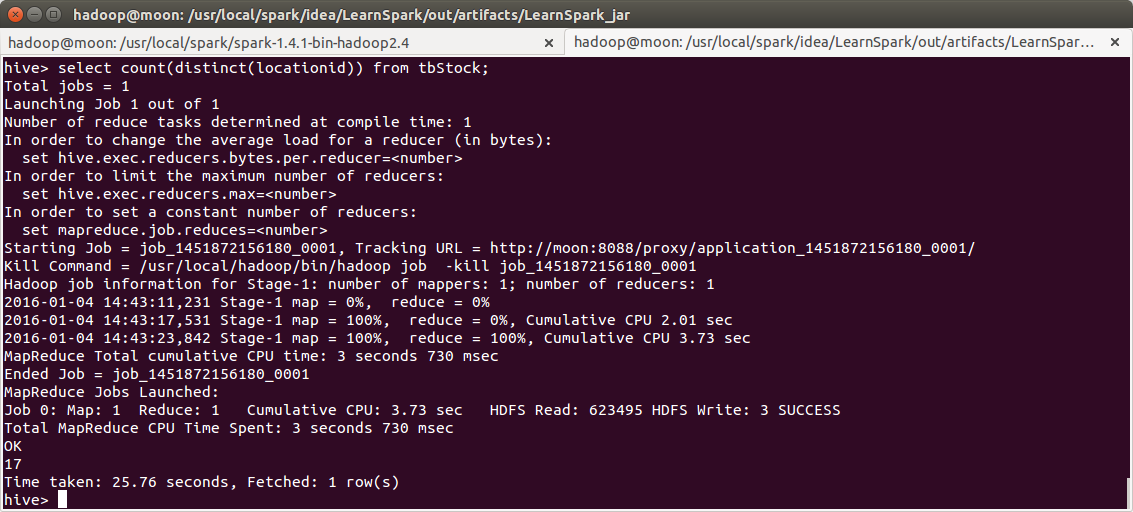
在hive中看到有17个店
代码如下:
package class6
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-4.
*/
object SQLMLlib {
def main(args: Array[String]) {
//屏蔽不必要的日志显示在终端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//设置运行环境
val SparkConf = new SparkConf().setAppName("SQLMLlib")
val sc = new SparkContext(SparkConf)
val hiveContext = new HiveContext(sc)
//使用sparksql查出每个店的销售数量和金额
hiveContext.sql("use hive")
hiveContext.sql("SET spark.sql.shuffle.partitions=20")
val sqldata = hiveContext.sql("select a.locationid, sum(b.qty) " +
"totalqty,sum(b.amount) totalamount from tbStock a join tbStockDetail b on " +
"a.ordernumber=b.ordernumber group by a.locationid")
//将查询数据转换成向量
val parsedData = sqldata.map{
case Row(_,totalqty,totalamount)=>
val features = Array[Double](totalqty.toString.toDouble,
totalamount.toString.toDouble)
Vectors.dense(features)
}
//对数据集聚类,3 个类,20 次迭代,形成数据模型
//注意这里会使用设置的 partition 数 20
val numClusters = 3
val numIterations = 20
val model = KMeans.train(parsedData,numClusters,numIterations)
用模型对读入的数据进行分类,并输出
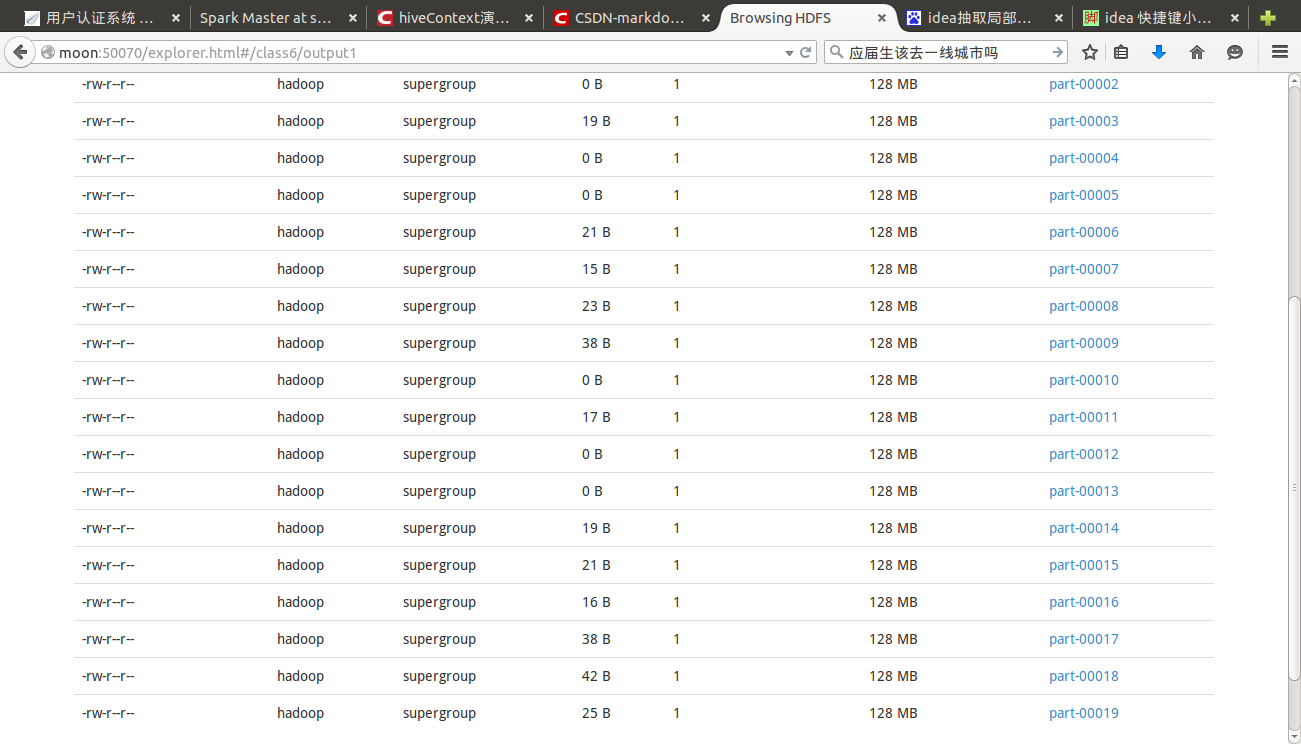
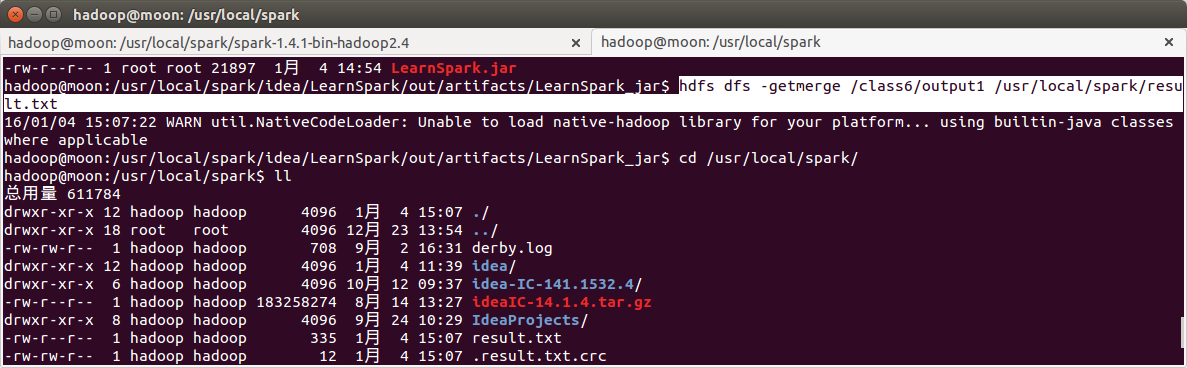
//由于 partition 没设置,输出为 200 个小文件,可以使用 bin/hdfs dfs -getmerge 合并
//下载到本地
val result2 = sqldata.map{
case Row(locationid,totalqty,totalamount)=>
val features =Array[Double](totalqty.toString.toDouble,
totalamount.toString.toDouble)
val linevectore = Vectors.dense(features)
val prediction = model.predict(linevectore)
locationid+" "+totalqty+" "+totalamount+" "+prediction
}.saveAsTextFile(args(0))
sc.stop()
}
}
打包运行,提交时参数为输出目录
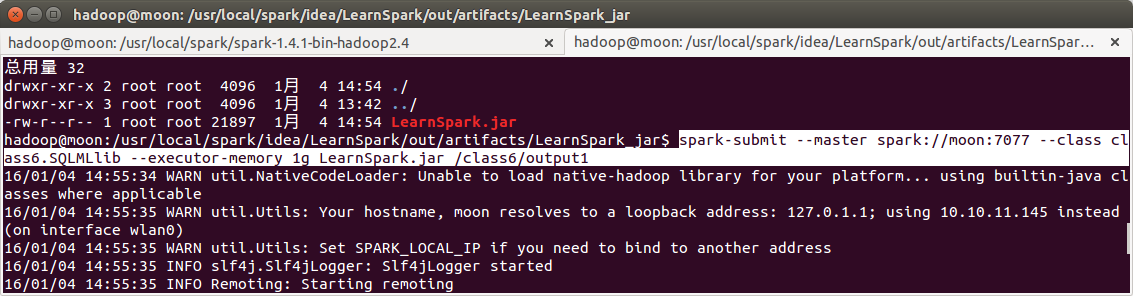
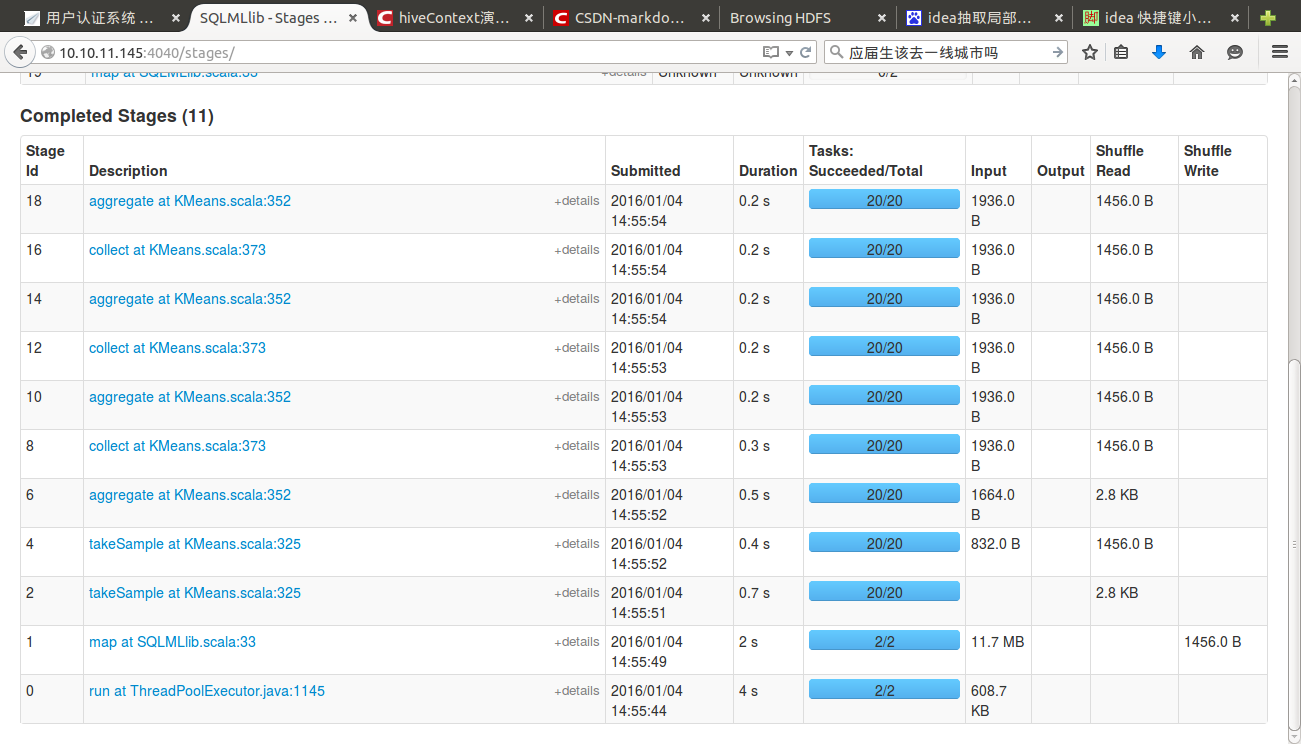
Page Rank
未完,待续。。。。。。















 2145
2145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









