







因为官网的使用的很不方便,各个参数没有详细的说明,也查不到很好的资料了。所以决定使用python配合NLTK来获取Constituency Parser和Denpendency Parser。
一、安装python
操作系统win10
jdk(版本1.8.0_151)
anaconda(版本4.4.0),python(版本3.6.1)
略
二、安装NLTK
pip install nltk安装完成之后进入python命令中,输入
import nltk
nltk.download()如图所示:

然后就会弹出一个框,具体我目前也不是很懂,大概就是提供的一些资源包,所以我就全部先download
如图所示:
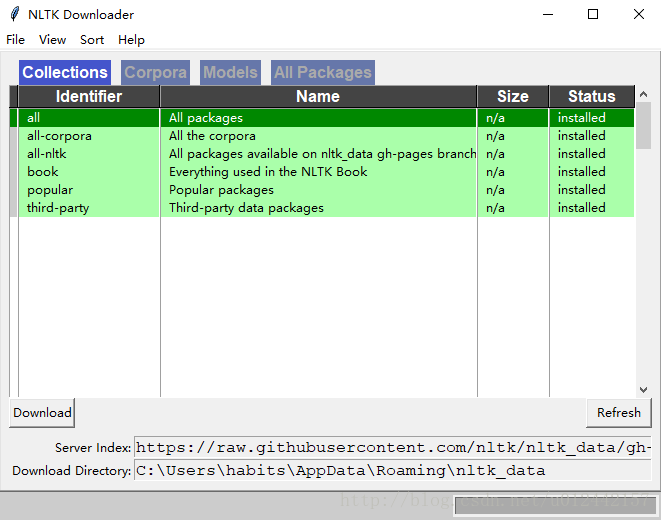
这样就完成了。
三、stanford parser与NLTK
在不设置classpath的情况下,简单实用stanford parser的几个简单的demo
1.Constituency Parser
# -*- coding: utf-8 -*-
import os
from nltk.parse.stanford import StanfordParser
os.environ['STANFORD_PARSER'] = './model/stanford-parser.jar'
os.environ['STANFORD_MODELS'] = './model/stanford-parser-3.8.0-models.jar'
parser = StanfordParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
sentences = parser.raw_parse("the quick brown fox jumps over the \" lazy \" dog .")
# for line in sentences:
# for t in line:
# print(t)
# GUI
for line in sentences:
for sentence in line:
sentence.draw()2.Denpendency Parser
# -*- coding: utf-8 -*-
import os
from nltk.parse.stanford import StanfordDependencyParser
os.environ['STANFORD_PARSER'] = './model/stanford-parser.jar'
os.environ['STANFORD_MODELS'] = './model/stanford-parser-3.8.0-models.jar'
parser = StanfordDependencyParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
sentences = parser.raw_parse("the quick brown fox jumps over the lazy dog")
# 返回的是tree
# for line in sentences:
# print(line)
res = list(parser.parse("the quick brown fox jumps over the lazy dog .".split()))
for row in res[0].triples():
print(row)这是分割线
最终版的:
# -*- coding: utf-8 -*-
import os
from nltk.parse.stanford import StanfordDependencyParser
os.environ['STANFORD_PARSER'] = './model/stanford-parser.jar'
os.environ['STANFORD_MODELS'] = './model/stanford-parser-3.8.0-models.jar'
parser = StanfordDependencyParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
fin = open("./data/raw.clean.test", encoding="utf-8")
fout = open("./result/test.txt", "w+", encoding="utf-8")
i = 0
for line in fin.readlines():
if line is None or line == "":
pass
else:
sentences, = parser.parse(line.split("|||")[0].split(" "))
# print(sentences.to_conll(4))
fout.write(sentences.to_conll(4))
fout.write('\n')
fout.flush()
i += 1
print(i)
fin.close()
fout.close()最终的样子非常符合我的需求
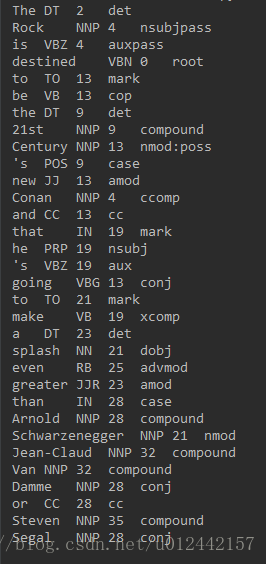
over














 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









