







1. volatile关键字与可见性
强制线程到共享内存中读取数据,而不是从线程工作内存中读取数据,从而使变量在多个线程中可见。
无法保证原子性,属于轻量级的同步。性能比synchronized强很多(不加锁),但是只保证线程的可见性,并不能代替sychronized的同步功能。
2. static与volatile
static 保证唯一性,不保证一致性,多个实例共享一个静态变量。
volatile 保证一致性,不保证唯一性,多个实例有多个volatile变量。
在多线程操作时,static变量与会被拷贝到线程的工作内存中进行操作,如果对static变量进行了修改,会在修改之后由工作内存写会到共享内存中。
3. Actomic类的原子性
使用ActomicInteger等原子类可以保证共享变量的原子性
使用Actomic类不能保证成员方法的原子性
package com.jimmy.actomic;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicDemo {
public static AtomicInteger sum = new AtomicInteger(0);
public static void add() {
System.out.println(Thread.currentThread().getName() + " 初始sum = " + sum);
for (int i = 0 ; i < 10000; i ++ ) {
sum.addAndGet(1);
}
System.out.println(Thread.currentThread().getName() + " 相加后sum = " + sum);
}
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
es.submit(() -> add());
}
es.shutdown();
while (true) {
if (es.isTerminated()) {
System.out.println("finally sum = " + sum.get());
break;
}
}
}
}
Actomic类采用了CAS非锁机制保证原子性。
Actomic类的CAS原理与ABA问题:https://blog.csdn.net/u012449363/article/details/86549823
4. ThreadLocal原理
使用ThreadLocal维护变量时, ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程可以独立的改变自己的副本而不会影响其他线程所对应的副本。
package com.jimmy.threadlocal;
public class ThreadLocalDemo {
public static void main(String[] args) throws InterruptedException {
// 不同线程中ThreadLocal变量会各自保存一份副本
final ThreadLocal<Integer> th = new ThreadLocal<>();
new Thread(() -> {
try {
th.set(100);
System.out.println("t1 set th = " + th.get());
Thread.sleep(2000); //保证t1与t2线程在同时执行
System.out.println("t1 get th = " + th.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
Thread.sleep(1000);
new Thread(() -> {
Integer i = th.get();
System.out.println("t2 get th = " + i);
th.set(200);
System.out.println("t2 get th = " + th.get());
}).start();
}
}
演示结果:
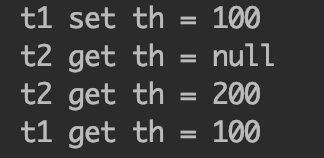
可见,t1中的变量并没有在t2执行过程中发生数值变化。t2线程在第一次获取th的值的时候为null,更明显的说明了t1、t2两个线程中th的值并不是在共享内存中。
5. 同步类容器
1)Vector、Stack、HashTable【使用synchronized关键字来实现同步控制】
例:Hashtable.put方法源码
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
2)Collections 工具类中提供的同步集合类【内部方法也是使用sychronized关键字来实现同步控制】
Collections类是一个工具类,相当于Arrays类对于Array的支持,Collections类中提供了大量对集合或者容器进行排序、查找的方法。它还提供了几个静态方法来创建同步容器类:

例:SynchronizedList.add方法实现:
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
可见也是使用信号量加锁来做的同步控制。
6. 并发容器类
JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能。因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全性,所以这种方法的代价就是严重降低了并发性,当多个线程竞争容器时,吞吐量严重降低。因此Java5.0开始针对多线程并发访问设计,提供了并发性能较好的并发容器.
1.ConcurrentMap类容器
ConcurrentHashMap可以替代HashMap, Hashtable
ConcurrentSkipListMap替代TreeMap
其中ConcurrentHashMap将hash分表分成了16个segment, 每个segment单独进行锁控制,以此来减小加锁的粒度,提升性能。
ConcurrentHashMap.put方法源码
从源码中可以看到,put方法使用CAS和分段加锁两种方式的结合,通过不加锁和减小加锁粒度两种不同方式来提升性能。
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p>The value can be retrieved by calling the {@code get} method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
这里不对ConcurrentHashMap的执行过程做深入探讨,之后会单独写一篇文章单独介绍。
2. COW容器
COW = Copy On Write。
写时复制容器,向容器中添加元素时,先将容器进行copy出一个新容器,然后将元素添加到新容器,再将原容器的引用指向新容器。
每次更新时都会复制新容器,所以如果在写密集型的应用中,会由于更新频繁生成大量复制对象使内存升高。
COW适用于度密集型的应用场景。
以CopyOnWriteArrayList.add(Element e)为例,写操作复制了一份当前arraylist的副本,然后修改之后又把修改后的数组System.arraycopy.整个过程也是通过sychronized关键字来保证程序的线程安全的。
public void add(int index, E element) {
synchronized(this.lock) {
Object[] es = this.getArray();
int len = es.length;
if (index <= len && index >= 0) {
int numMoved = len - index;
Object[] newElements;
if (numMoved == 0) {
newElements = Arrays.copyOf(es, len + 1);
} else {
newElements = new Object[len + 1];
System.arraycopy(es, 0, newElements, 0, index);
System.arraycopy(es, index, newElements, index + 1, numMoved);
}
newElements[index] = element;
this.setArray(newElements);
} else {
throw new IndexOutOfBoundsException(outOfBounds(index, len));
}
}
}
在读的时候,以CopyOnWriteArrayList.get()为例,在读的时候并没有做并发控制。
public E get(int index) {
return elementAt(this.getArray(), index);
}
static <E> E elementAt(Object[] a, int index) {
return a[index];
}
CopyOnWriteArrayList通过读写分离、写时复制的方法来控制并发。这种情况适合在读密集型的应用中使用。















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









